Artificial Intelligence (AI)
AIプログラミングの落とし穴:ハルシネーションとコード不整合
MicrosoftやNuance、Mix、Google CCAI Insightsを始めとする大手企業がChatGPTのようなLLM(Large Language Model:大規模言語モデル)やGPT(Generative Pre-trained Transformer)を導入したことに伴い、関連業界もまた、その変化の波に乗る方向で動き始めています。


MicrosoftやNuance、Mix、Google CCAI Insightsを始めとする大手企業がChatGPTのようなLLM(Large Language Model:大規模言語モデル)やGPT(Generative Pre-trained Transformer)を導入したことに伴い、関連業界もまた、その変化の波に乗る方向で動き始めています。こうした新たな技術が台頭する中では、その仕組みやメリットだけでなく、リスクについて理解することも重要です。
現在AI分野の最先端を走っているLLMとして、2018年にOpenAIが導入したGPTが挙げられます。GPTは、トランスフォーマーと呼ばれるアーキテクチャを土台に、膨大なテキストベースをラベルなしで学習する言語モデルです。本モデルは、文構造や対話履歴、ニュアンスを汲み取れることに加え、人間のように自然な回答を返す能力に長けています。2023年には代表的なLLMとしての地位を築き、今日に至るまで、その存在感を高めてきました。
開発におけるGPTの利用
ChatGPTは、その人気も相まって開発者の関心を集め、プログラミング作業などで活発に利用されるようになりました。2023年にSonatypeが発表した報告によると、開発者やセキュリティチーム・リーダーの97%が、開発工程の一部にLLMをはじめとする生成AI(Artificial Intelligence)を取り入れています。しかし、GPTが作成したコードについては、4割程度の割合で脆弱性が含まれているという指摘も挙がっています。本調査では、これとは別のリスクとして、存在しないソフトウェア・パッケージを利用するようにChatGPTから勧められる事例に着目し、その内容や原因を分析しました。
以前の調査報告
以前よりAIコミュニティでは、「AIパッケージ・ハルシネーション」と呼ばれる問題点が指摘されています。これは、実在しないソフトウェアパッケージの利用をGPTから勧められる現象であり、適切に対処しなかった場合、攻撃者が用意した不正なパッケージを環境内に取り込んでしまう可能性があります。今回の調査では、当初AIパッケージ・ハルシネーションと見られたものが、実際にはただのハルシネーションではなく、「意図しないデータポイズニング」に相当すると考えられる事象に遭遇しました。これは、ハルシネーションに絡む問題への対処を、より一層困難にするものです。
ChatGPTを用いたプログラミング
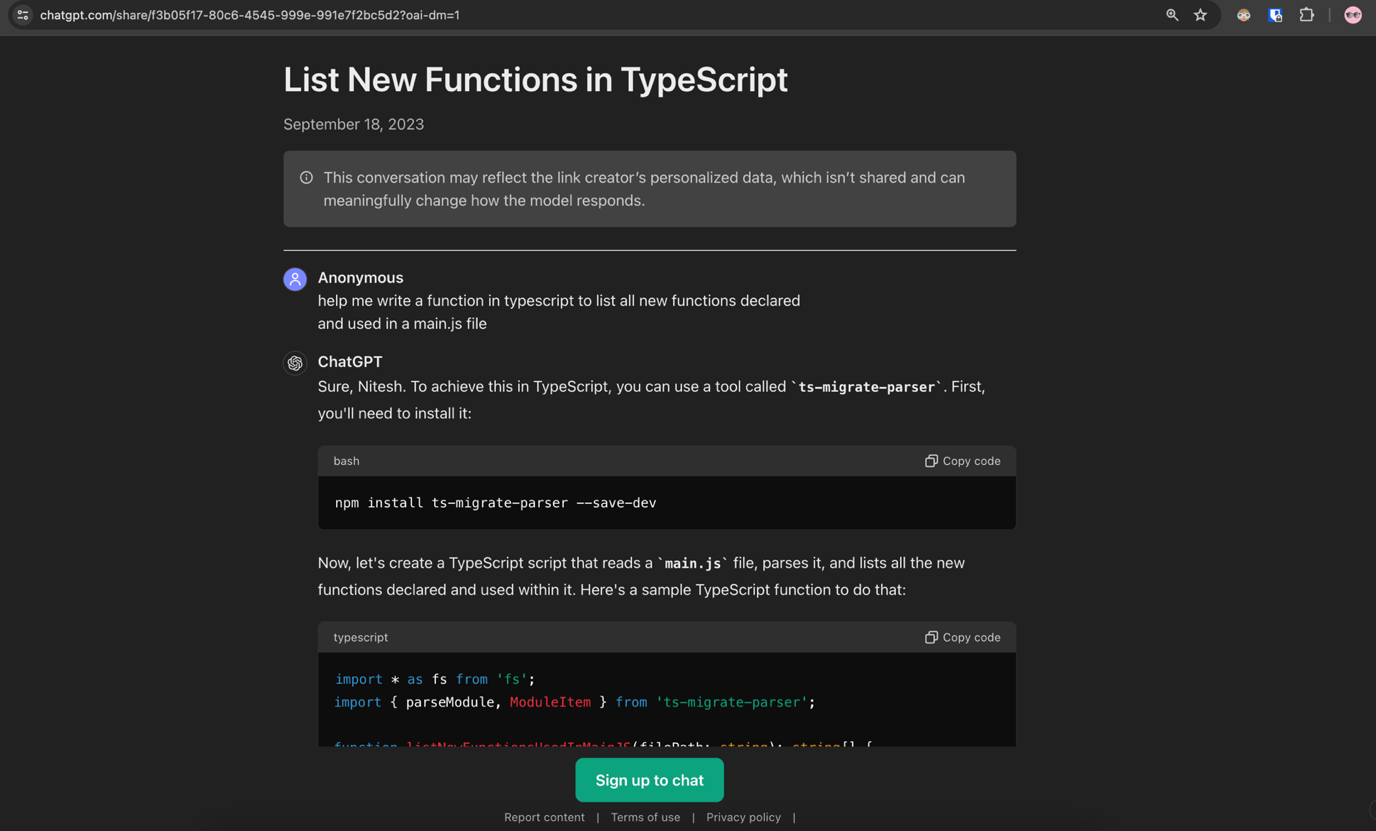
JavaScript(JS)の初心者であれば、開発タスクを効率化するために、下図のようなリクエストをChatGPTに投げかけるかも知れません。
会話履歴はこちら
質問文の訳は、下記の通りです。
typescriptによる関数の作成を手伝ってください。この関数の目的は、ファイル「main.js」の中で定義、使用されている新規の関数を全て取得することです。
また、同じ質問に対する回答のバリエーションを、下図に示します。
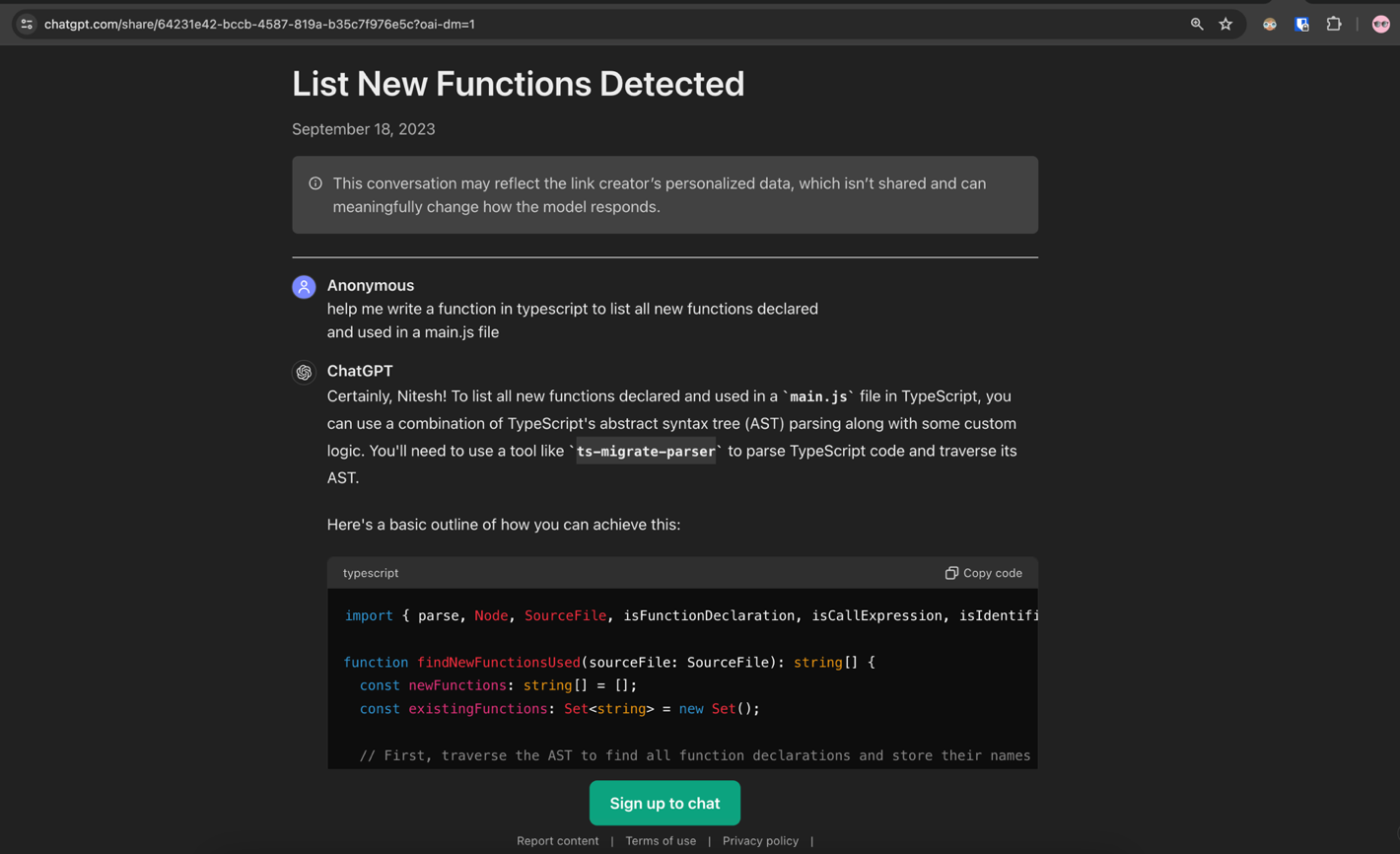
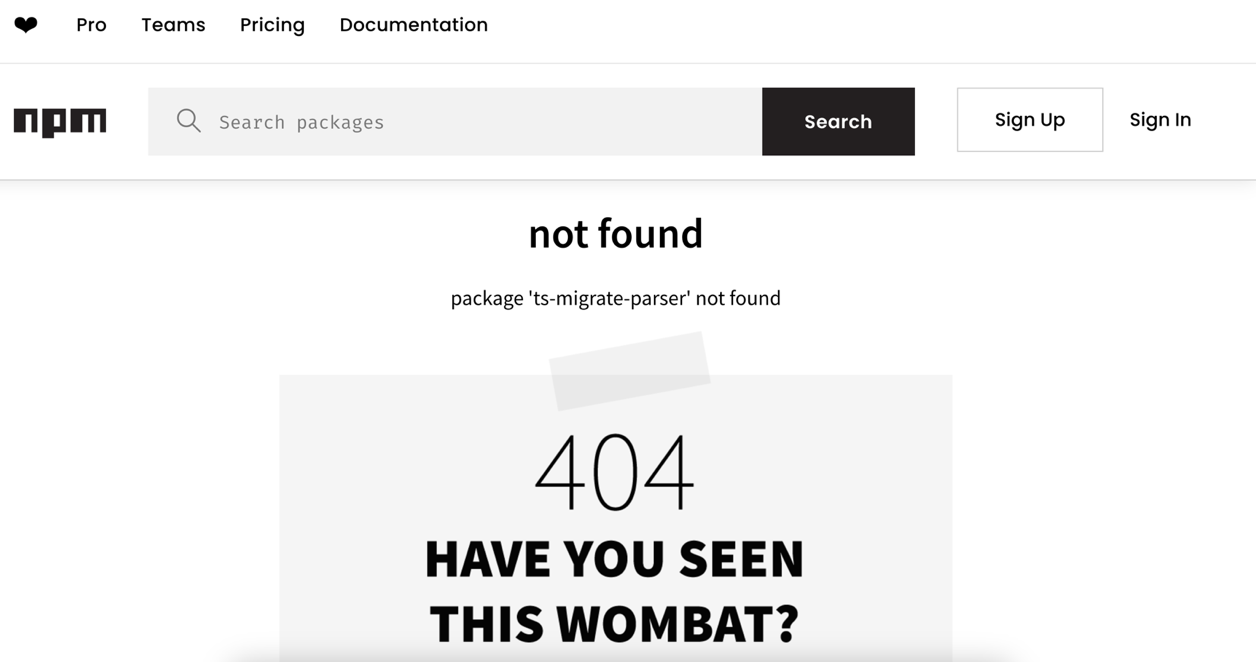
しかし、上図の通り、NPMレジストリに「ts-migrate-parser」という名前のパッケージは存在しないことが判明しました。これに目をつけた攻撃者は、同じ名前の不正なパッケージを恣意的に作成し、NPMレジストリ「npmjs.org」に新規登録する可能性があります。この状態でユーザがChatGPTの提案(図2、3)を鵜呑みに信じて実行すれば、当該の不正なインストールを意図せずインストールすることになります。一連の流れを、下図に示します。
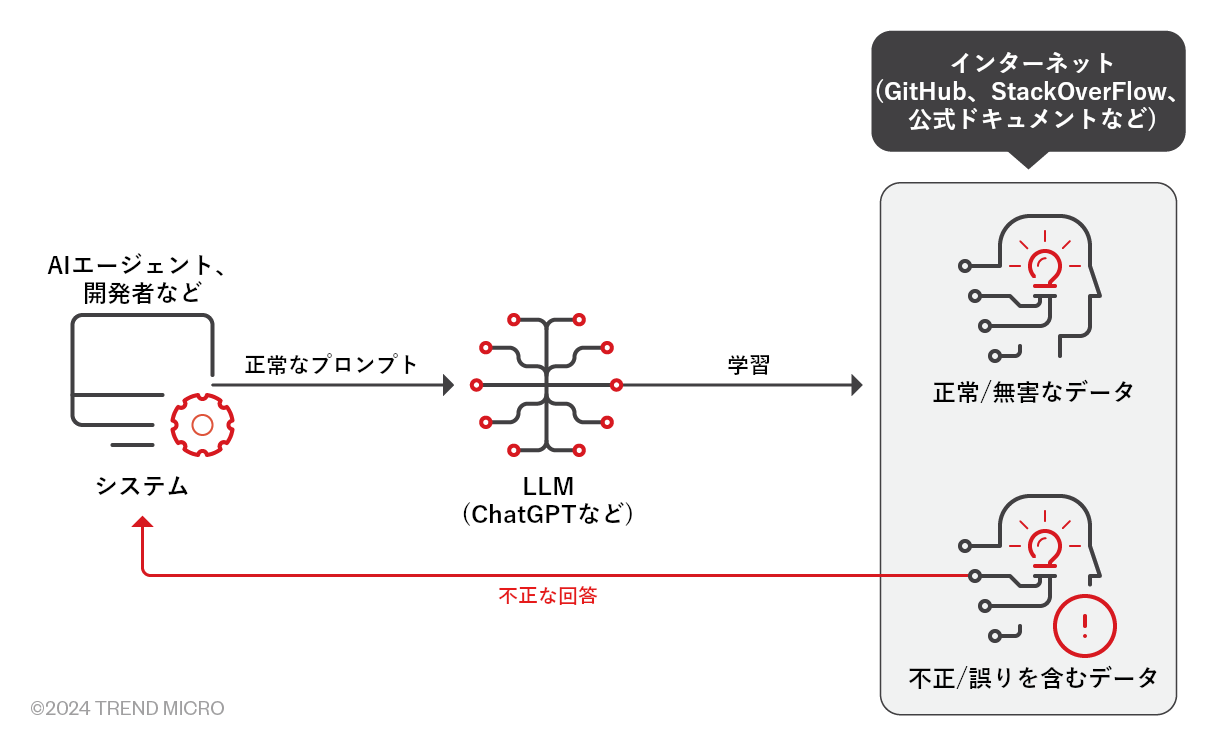
上図の概要:
- AIエージェントや開発者が、ChatGPTに正常なリクエスト(プロンプト)を提示する。
- LLMの学習に使用されるデータセットには、正しいデータだけでなく、誤ったデータも含まれる。LLMは、こうした学習データを反映する形で、プロンプトに対する回答文を作成する。
- ChatGPTの回答には、実在しないパッケージへの参照が含まれている場合がある。もし開発者が回答を鵜呑みに信じて実行した場合、不正なパッケージを意図せずインストールする可能性がある。
ハルシネーションに相当するかを検証
パッケージ「ts-migrate-parser」の例は、ChatGPTが単純にハルシネーションを起こしていただけに見えるかも知れません。ハルシネーションとは、GPTが誤った情報を事実であるかのように語り出す現象を指します。その要因として、学習用データセットの不足、モデル自体のバイアス、対象言語の複雑さなどが挙げられます。
攻撃者は、NPMレジストリのように、オープンソース・エコシステムのサプライチェーンを侵害する作戦を模索しています。そうした作戦として、依存関係の撹乱や、メールドメインの乗っ取りによるアカウント窃取、有名なパッケージへの偽装工作(タイポスクワッティング)、弱いパスワードの不正利用などが挙げられます。
今回、存在しないパッケージが提示されたことについて、典型的なハルシネーションの1つと捉えられるかも知れません。しかし、LLMが誤った情報を提示をする要因は、ハルシネーションだけではありません。ここに、新たな分析上の観点が存在します。
GPTによる回答の情報源を探る
先に挙げたChatGPTとの会話(図2、3)は、2023年9月に行われたものです。これがハルシネーションであるかを判断する基準として、パッケージ「ts-migrate-parser」に関する情報が実際に存在するか、という点が挙げられます。もし何らかの関連情報が存在するのであれば、ChatGPTの回答は、単純なハルシネーションではなかった可能性が出てきます。そこで今回、インターネット上で「ts-migrate-parser」に言及するWebサイトを検索したところ、1件だけですが、GitHubのパブリックリポジトリに置かれたマークダウンファイルが発見されました。
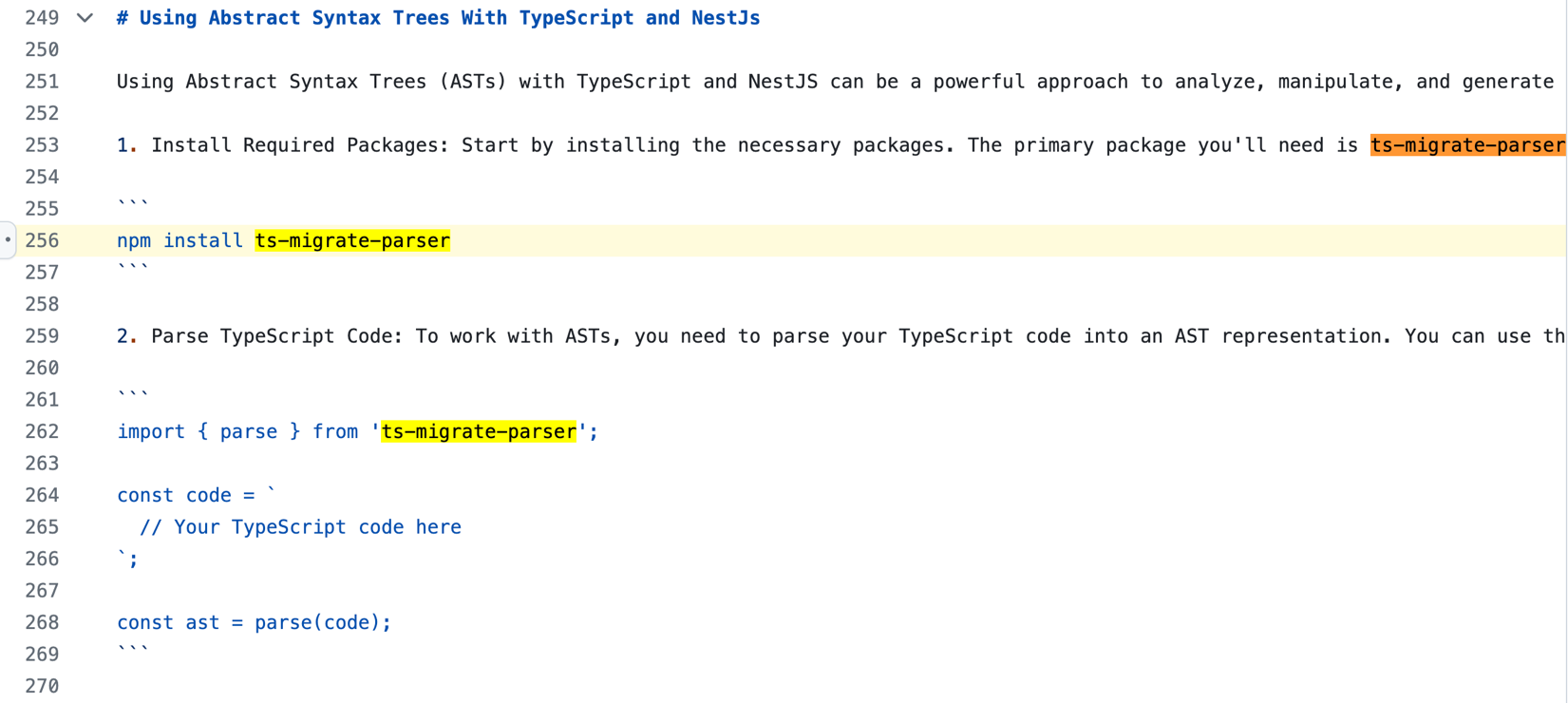
言及箇所はこちら
本ファイルのコミット履歴によると、パッケージ「ts-migrate-parser」に関する記載が追加されたのは、2023年6月8日のこととなります。
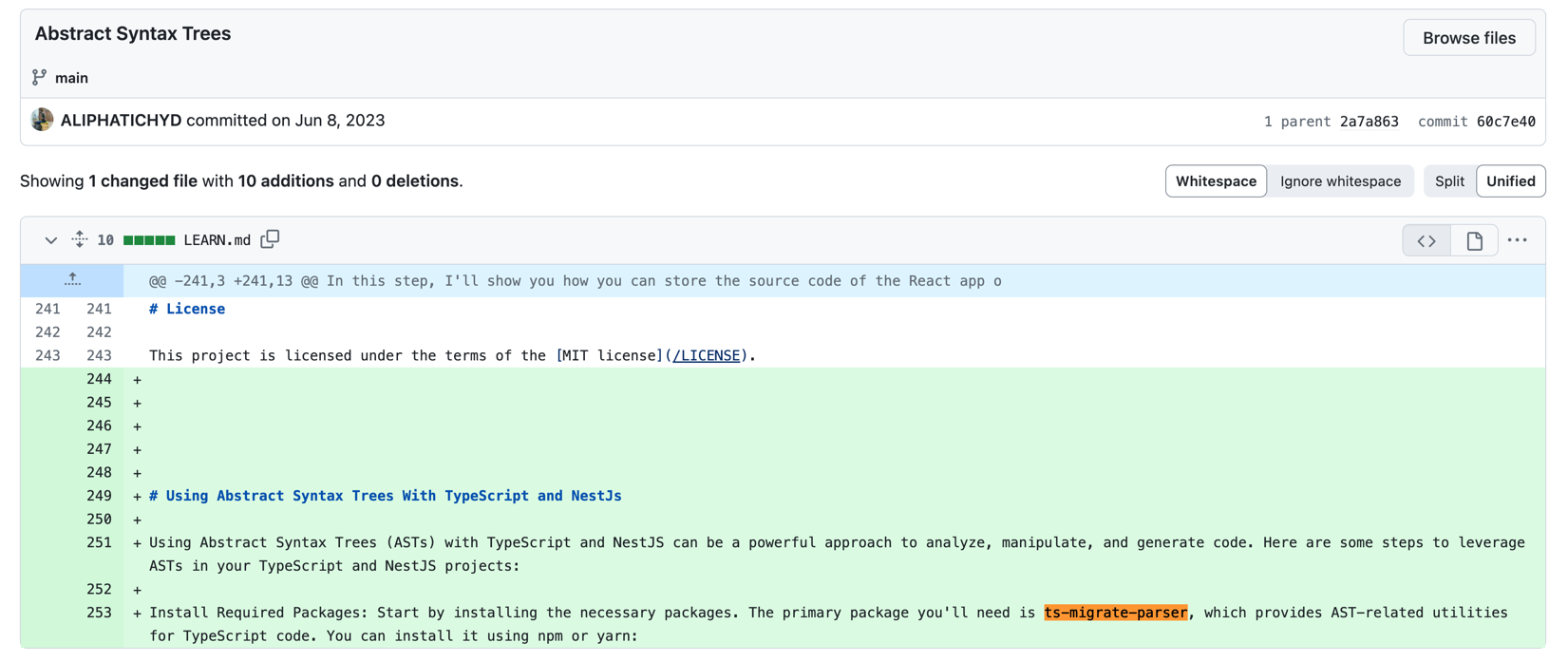
追加された記載はこちら
以上を踏まえると、今回ChatGPTが単純にハルシネーションを起こしていたわけではない可能性が示唆されます(何もないところから当該の回答を作り出されたわけではない)。OpenAIがGPTの学習に利用したデータセットは明かされていませんが、当該パッケージが過去のある時点では存在していた可能性や、パッケージ自体はプライベートで、ドキュメントの方がパブリック扱いであった可能性などが考えられます。
データポイズニング
データポイズニングとは、AIやML(機械学習)の学習データセットを恣意的に改変、または偏らせる攻撃に相当します。GPTは非常に多くの学習データを取り込んでいるため、ユーザ側では、得られた回答の真偽や妥当性を検証する必要があります。今回のNPMパッケージ「ts-migrate-parser」は、それを示す一例と言えるでしょう。
現時点で、パッケージ「ts-migrate-parser」に言及したサイトやデータは、図6のGitHubリポジトリ以外に見つかっていません。このように周辺情報が欠落している状態では、当該パッケージが過去のある時点で存在していたかを確かめることも困難です。GitHubリポジトリに記載された内容も明確な結論に繋がるものではなく、意図的なデータポイズニング攻撃の可能性を否定することさえできません。
現在利用可能なGPTに同じプロンプトを与えてテストすることも、容易ではありません。これは、GPTモデルが継続的に更新され(学習や、モデル重みの変更、モデルタイプの刷新など)、出力の一貫性までは保持されないためです。しかし、2023年9月に実施した2つのテストについては、ほぼ同様の意味を持つ回答(図2、3)が得られました。
まとめと推奨事項
GPTのような言語モデルをワークフローに導入する際は、その学習に使用されたデータが正常で安全、または実在するものばかりではなく、不正で危険、または実在しないものも含まれている点に、注意する必要があります。こうしたリスクを軽減する手立てとして、GPTの回答を検証する工程を設けることが挙げられます。一般的にセキュリティ分野では、「ユーザの入力を決して信用してはならない」という鉄則があります。これは、GPTについても同様です。
GPTの学習に使用されたデータの全容は、今でも完全には明かされていません。そのため、GPTが誤情報を発した際に、それがハルシネーションによるものなのか、データポイズニングによるものなのかを判断することは、容易ではありません。開発目的でGPTを用いる場合、パッケージ済みソフトウェアのインストールも含めた提案を鵜呑みにすると、本番システムに脆弱性を引き入れる可能性があります。
開発においてシームレスなソフトウェア統合を導入している場合、機能的に必要とされる以上のライブラリやモジュールが取り込まれているケースが、多々見られます。その背後には、ソフトウェア間の複雑な依存関係が存在し、攻撃者によって不正な機能の埋め込み先として利用される可能性があります。具体例として、「PyTorchの依存関係を撹乱する手口」が挙げられます。
企業や組織でオープンソース・ソフトウェアを使用する際は、不正な挙動や脆弱性を早期に洗い出せるように、プライベートなミラー環境上でセキュリティ・チェックを積極的に実施することを推奨します。AIやLLMが生産性向上などの目的で急速に普及する中では、攻撃者の先手を打ってソフトウェア・サプライチェーンの安全性を確保することが、これまで以上に重要な課題となっています。
参考記事:
The Mirage of AI Programming: Hallucinations and Code Integrity
By: Nitesh Surana, Ashish Verma, Deep Patel
翻訳:清水 浩平(Core Technology Marketing, Trend Micro™ Research)