SBOMs: ein Weg – nicht das Ziel
SBOMs allein sind kein Allheilmittel. Sie dokumentieren lediglich Zustände von Software-Artefakten als Grundlage für eine sinnvolle Risikoabschätzung. Aber erst Minderungs- oder Abwehrmaßnahmen steigern die Sicherheit wirklich.


Save to Folio
SBOM (Software Bill of Materials) ist ein Inventar einer Codebasis, einschließlich aller identifizierbaren Komponenten samt ihrer Lizenz- und Versionsinformationen sowie Angaben zu eventuell vorhandenen Sicherheitslücken. Obwohl diese „Software-Stücklisten“ an sich kein neues Thema sind, haben sie durch die aktuelle Berichterstattung und entsprechende gesetzliche Vorstöße, insbesondere der US-Regierung (siehe Executive Order on Improving the Nation’s Cybersecurity), einen hohen Bekanntheitsgrad erlangt. Damit einhergehend ist leider auch ein gewisser Hype um diese Themen entstanden. Einerseits bekommen SBOMs „endlich“ die Aufmerksamkeit, die Stücklisten in anderen Industrien schon lange haben. Andererseits muss man „leider“ sagen, denn durch den Hype entsteht der Eindruck, dass mit der Erstellung von SBOMs das Problem der Integrität der Softwarelieferkette gelöst ist. Dabei sind SBOMs nur ein kleines Puzzlestück auf dem Weg dahin – sie sind noch lang nicht das Ziel.
Dokumentiert heißt nicht gelöst
In diesem Punkt ähneln SBOMs den Schwachstellenanalyse-Werkzeugen. Die Tools scannen Systeme und Netzwerke und melden gefundene Schwachstellen. Abgesehen davon, dass sie in vielen Fällen das Vorhandensein von Sicherheitslücken allein aufgrund der gefundenen Komponenten und Versionsnummern vermuten, jedoch nicht erkennen, ob diese etwa durch andere Mechanismen (z.B. Virtual Patching) geschützt sind, ermöglichen sie allein keine echte Risikobewertung und keine Umsetzung von Abwehrmaßnahmen.
Genauso stellen SBOMs zunächst auch „nur“ ein Datenformat dar, in dem Softwarekomponenten und deren (Meta-)Daten erfasst werden können. Zu diesen Daten gehören u.a. Versionen, Abhängigkeiten, Lizenzen, aber auch Sicherheitslücken. Insbesondere letztere sind interessant, da viele Tools mittlerweile nicht nur SBOMs mit Abhängigkeiten erzeugen, sondern quasi „nebenbei“ auch zum Zeitpunkt der Erstellung bekannte Sicherheitslücken in die SBOM-Daten schreiben. Und selbst wenn die generierten SBOMs keine Sicherheitsdaten enthalten, übernehmen spätestens nachgelagerte Werkzeuge, z.B. OWASP Dependency Track, die mehrere SBOMs verwalten, oft den kontinuierlichen Abgleich der gespeicherten SBOMs mit Schwachstellen-Datenbanken.
Aus Sicherheitssicht ist dies natürlich zu begrüßen, da sich so auf einen Blick erkennen lässt, welche im Unternehmen eingesetzte und entwickelte Software letztendlich von Sicherheitslücken betroffen ist. Dennoch handelt es sich zunächst „nur“ um eine Dokumentation zum Sicherheitsstatus, die zwar die Transparenz für diesen Aspekt der Sicherheit erhöht, jedoch wirklich „sicherer“ wird das System dadurch aber nicht.
Risiken bewerten
Auch die Ergebnisse von Schwachstellenanalyse-Werkzeugen allein reichen nicht aus, um die Risiken bewerten zu können. Für eine solche Abschätzung fehlt beispielsweise die tatsächliche Anzahl der betroffenen Systeme oder die Kritikalität der darauf betriebenen Dienste. Und selbst wenn diese Informationen vorliegen, erhöhen sie nicht die Sicherheit. Bis zu diesem Zeitpunkt ist „nur“ der Sicherheitsstatus dokumentiert und dessen Auswirkung auf das Risiko bewertet -- nicht mehr und nicht weniger.
Bezüglich SBOMs bedeutet dies, dass Softwareinformationen, Abhängigkeiten und Schwachstellen viel zu kurz greifen. Der Verbreitungsgrad einer Software, z.B. Firmware für selbst entwickelte Geräte, ist ein gutes Beispiel. Während Dependency Track sauber Buch darüber führt, welche Firmware-Version welche Lücken enthält und auch gleich die jeweilige Verwundbarkeit über den CVSS Score bewertet, fehlt für eine echte Risikoabschätzung noch mindestens eine wichtige Kennzahl: der Verbreitungsgrad der Firmware! Eine extrem angreifbare Firmware, die aber nur für interne Tests gebaut wurde und nicht mehr in Betrieb ist, kann niedriger bewertet werden als eine harmlosere Sicherheitslücke, die aber tausendfach draußen im Feld ist.
Diese und andere Kennzahlen sind unverzichtbar, um das Risiko zu bewerten - werden aber von Tools wie Dependency Track nicht erhoben. Und genau genommen ist es auch nicht die Aufgabe solcher Tools, diese Kennzahlen zu pflegen. Es sind Repositories für SBOMs und zugehörige Verwundbarkeiten. Verbreitungszahlen werden z.B. in Admin- oder Lizenzmanagement-Portalen gepflegt. Dann fehlt vielleicht noch das Preissegment oder der Supportstatus für den Business Impact.
All dies sind Zahlen, die im Unternehmen vorliegen und herangezogen werden müssen, um das Risiko bewerten zu können. Von einem SBOM-Management-Tool zu erwarten, diese Zahlen zusammenzuführen, ist nicht sinnvoll. Das bedeutet auch, dass SBOMs und SBOM-Management nur ein Baustein der Lieferkettensicherheit sind. Weitere Bausteine bestehen u.a. darin, Daten zum Verbreitungsgrad, zum Supportstatus oder allgemein zum „Business Impact“ einfließen zu lassen. Dabei ist es von untergeordneter Bedeutung, ob diese Integration durch eigene Software/Portale oder durch Standardlösungen erfolgt.
Wichtig ist, dass bei der Risikobewertung sowohl die „Eintrittswahrscheinlichkeit“ (z.B. abhängig von der Anzahl/Kritikalität der Schwachstellen und der Anzahl der verwundbaren Systeme) als auch die mögliche Schadenshöhe (abhängig von der Art der Systeme/Services und ggf. auch von der Verbreitung) betrachtet werden. Dies erfordert jedoch mehr als nur die Erstellung von SBOMs bzw. deren Management. Es bedarf zusätzlich administrativer (z.B. Verbreitungsgrad) und wirtschaftlicher Kennzahlen (Lizenzgrößen, Supportstatus, ...).
Risikobewertung entlang der Lieferkette
Bei der Diskussion um SBOM ist es immer wichtig, den Kontext zu berücksichtigen. Häufig wird leider nur der rein lokale Kontext betrachtet. Heutzutage wird aber kaum eine Software vollständig mit allen Funktionen im eigenen Haus erstellt, sondern mit bestehenden Diensten und Bibliotheken versehen, ob Open Source oder kommerzieller Herkunft ist hier nebensächlich. Die wachsende Bedeutung von Open Source Software und die Auswirkungen von Sicherheitslücken in ebendieser auf die Sicherheit nachgelagerter Software in (staatlichen) Softwarepaketen lässt sich auch an Gesetzesentwürfen ablesen, die derzeit in den USA diskutiert werden. Der Securing Open Source Software Act definiert Rahmenbedingungen für die CISA (Cybersecurity and Infrastructure Security Agency) zur Verbesserung der Sicherheit von quelloffener Software, die im staatlichen Umfeld eingesetzt wird.
Abhängigkeiten in der Lieferkette zu dokumentieren, um Risiken zu bewerten, ist darüber hinaus nicht nur auf Software beschränkt. Daher ist es umso wichtiger, auch Akteure wie Entwickler, Lieferanten oder Integratoren, Lizenzen, Verbreitungsgrad, Reifegrad, gesetzliche Rahmenbedingungen (z.B. Exportbeschränkungen) im Abhängigkeitsgraphen zu dokumentieren und entsprechend zu berücksichtigen.
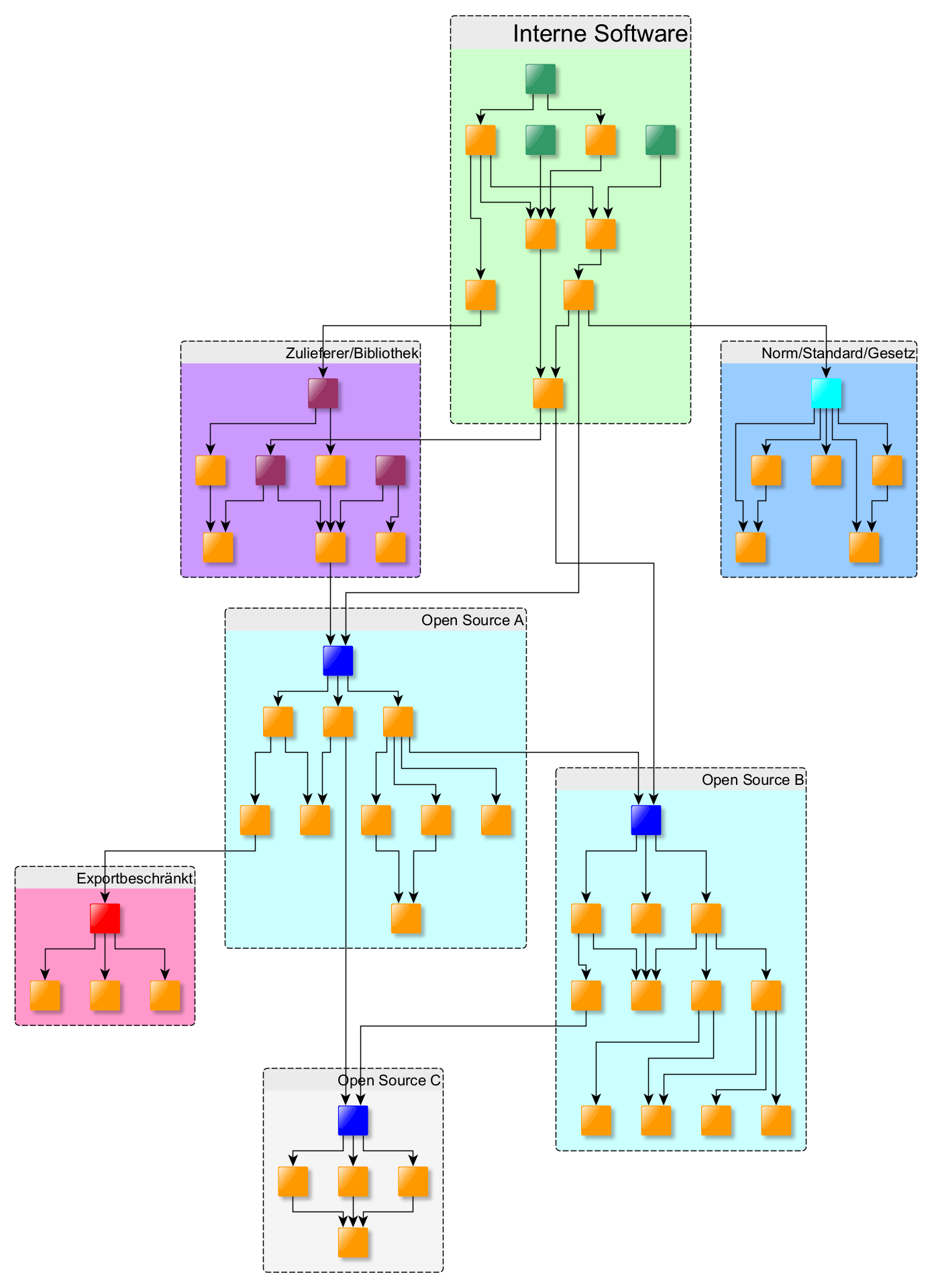
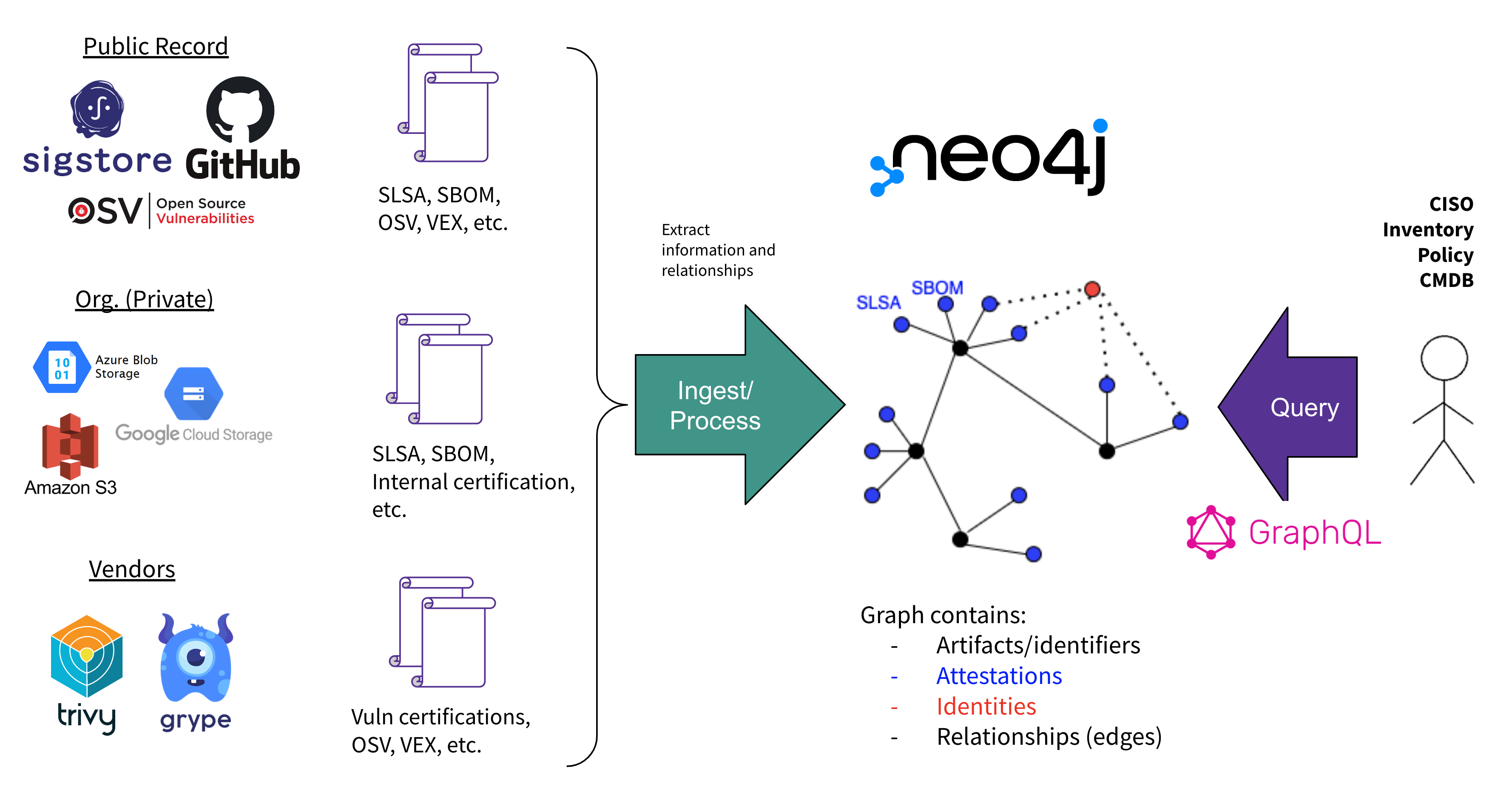
Informationen gespeichert werden. Darüber hinaus werden Datenquellen und Abfragemöglichkeiten spezifiziert. Dabei sieht GUAC von Anfang an vor, dass mehrere Parteien an (Teil-)Graphen zusammenarbeiten. Das bedeutet z.B., dass Unternehmen durchaus eigene (Teil-)Graphen pflegen können, die auf fremden/öffentlichen Graphen basieren. Das Datenformat der Knoten und Kanten und die Abfragemöglichkeiten bleiben jedoch unabhängig von der Graphenstruktur identisch.
Bestehende Lösungen sind konzeptionell dagegen mehr als eine Einbahnstraße konzipiert, bei denen SBOM-Daten eingepflegt und dann entsprechende Reports erstellt werden. GUAC hingegen definiert ein offenes interoperables Daten- und Abfragemodel. Es ist also davon auszugehen, dass z.B. bestehende Lösungen in Zukunft ihre Daten selbst via GUAC zu Verfügung stellen bzw. gleich auf GUAC als Datenmodell aufsetzen. Der Mehrwehrt zukünftiger Lösungen wird also nicht mehr im „Ingest“ (also dem Importieren von Daten aus verschiedenen Quellen) und der (einfachen) Kreuzkorrelation von Daten (z.B. Verwundbarkeiten in Software-Artefakten) bestehen. Vielmehr können sie sich auf spezifischere Anreicherung von Daten im Graph, die Herausarbeitung komplexer Abhängigkeiten und umsetzungsfähiger Sicherheitsinformationen („actionable intelligence“) konzentrieren.
Fazit
Es ist wichtig, im Hinterkopf zu behalten, dass alle bisher diskutierten Technologien/Projekte/Standards „nur“ die Sichtbarkeit/Dokumentation verbessern bzw. eine fundiertere Risikoabschätzung ermöglichen. Die Dokumentation von Lücken/Risiken (entlang der Lieferkette) sorgt nicht automatisch für mehr Sicherheit. Für Inhouse-Software müssen z.B. Prozesse existieren, die sicherstellen, dass im Bedarfsfall schnellstmöglich neue (lückenlose) Softwareversionen erstellt, getestet und verteilt werden.
Der einfachste Prozess in der gesamten Kette ist dabei das eigentliche technische „Bauen“ der neuen Releases! Man sollte aber auch die Abhängigkeiten entlang der Lieferkette nicht vergessen. Zu wissen, dass ein Zulieferer eine gefährdete Bibliothek verwendet, ist zwar gut, doch im Gegensatz zur eigenen Software ist die Aktualisierung nicht so einfach. Vielmehr ist der Lieferant in die Pflicht zu nehmen, eine neue Version seines Produkts zur Verfügung zu stellen, die eine aktualisierte Bibliothek enthält. Dumm nur, wenn man im Vorfeld eines Vorfalls keine Prozesse oder rechtlichen Rahmenbedingungen mit dem Lieferanten vereinbart hat, die ihn hier a) überhaupt und b) rechtzeitig zum Reagieren bringen.
Werkzeuge wie GUAC werden in Zukunft vielleicht die Modellierung und Abfrage von Software-Artefakt-Graphen unter Einbeziehung von Open Source und kommerziellen Akteuren erleichtern. Basierend auf der daraus abgeleiteten Risikobetrachtung kann dies z.B. die Grundlage für Vertragsinhalte beim Bezug von (nicht Open Source) Software von Dritten darstellen.
Letztlich kann aber nur das Einspielen neuer Versionen ohne Sicherheitslücken die Sicherheit wirklich erhöhen. SBOMs, GUACs und Co. sorgen für mehr Transparenz - aber alleine nicht für mehr Sicherheit.