人工智慧
如何防範不受控的 AI 所帶來的風險與衝擊?
本文是有關不受控的 AI (Rogue AI) 一系列部落格文章的最新一篇,請持續鎖定來取得更多技術指引、個案研究以及分析洞見。


在本系列有關不受控的 AI (Rogue AI) 前幾篇文章中,我們簡短討論了企業該如何更有效管理其 AI 攻擊面的風險。此外,我們也提到了如何藉由建立值得信賴的 AI 身分來防範威脅。同時,我們還引述了一些優良示範,包括 MIT 正在蒐集有關 AI 風險的資料,以及 OWASP 正在提出一些能有效防範 LLM 漏洞的建議。
現在,該是補足一些空缺的時候了,以下將說明零信任與多層式防禦如何防範不受控的 AI 所帶來的威脅。
AI 之所以不受控的原因
| LLM 漏洞/不受控的原因 | 意外情況 | 遭到破壞 | 天生惡意 |
| 功能過多 | 功能或防護機制組態設定錯誤 | 功能直接遭到修改或新增,或是避開防護機制 | 惡意目的所需的功能 |
| 權限過多 | 授權組態設定錯誤 | 權限遭提升 | 必須取得所有權限,一開始並無 |
| 自主性過多 | 需經過人員審查的工作出現組態設定錯誤 | 人員審查流程遭移除 | 不受防禦機制控管 |
我們可利用上述原因來發掘及防範不受控的 AI 服務相關的風險。首先,第一步就是正確設定相關的 AI 服務,藉由指定可允許的行為來奠定一個安全的基礎以防範各種 AI 不受控的狀況。保護及清理 AI 服務與資料或工具的接觸點,可杜絕 AI 因遭到破壞而不受控的大部分情況,同時也可消除其他意外發生的情況。限制 AI 系統只能使用經過允許的資料和工具並檢查 AI 系統的輸入和輸出內容,是確保 AI 使用安全性的核心。
天生惡意不受控的 AI 有可能從外部攻擊您的企業,或者在您的環境當中扮演 AI 惡意程式的角色。許多用來偵測網路駭客惡意活動的行為模式,也可用於偵測天生惡意不受控的 AI。但隨著新的功能讓不受控的 AI 變得更加隱匿,能學習行為模式的偵測機制將無法涵蓋未知的情況。此時,就必須在裝置、工作負載以及網路活動上偵測機器的行為。在某些情況下,這是逮住這類天生惡意不受控的 AI 的唯一手段。
此外,行為分析還可偵測其他功能、權限或自主性過多的情況。不論其成因為何,裝置、工作負載及網路上出現異常活動,都是不受控 AI 活動的重要徵兆。
完整涵蓋 OSI 通訊架構的防禦
不過,為了讓防禦更加完善,我們必須考慮在 OSI 模型的每一層都採取縱深防禦,例如:
實體層: 監控雲端、端點和邊緣裝置的處理器 (CPU、GPU、TPU、NPU、DPU) 使用狀況。這適用於 AI 特有的工作負載行為模式、 AI 模型查詢 (推論),以及將模型參數載入 AI 流程附近的記憶體。
資料層: 使用 MLOps/LLMOps 版本追蹤與驗證來確保模型不會遭到下毒或更換,並記錄雜湊碼來識別模型。使用「軟體物料清單/AI 模型物料清單」(SBoM/MBoM) 來確保 AI 服務軟體和模型可信賴。
網路層: 限制可對外存取的 AI 服務,以及 AI 服務可接觸的工具和 API。偵測異常的通訊者,例如:人機移轉以及沒見過的機器活動。
傳輸層: 考慮限制外部 AI 服務的速率,並掃描是否有異常封包。
會議層: 加入驗證程序,例如人工檢查,尤其是在啟動 AI 服務執行個體時。使用逾時機制來防範連線階段遭到挾持,依情境來分析使用者的認證動作,藉此偵測異常的連線階段。
應用層與表現層: 發掘功能、權限及自主性的組態設定錯誤 (如上表所示)。針對 AI 的輸入和輸出設置一些防護機制,例如清除個人身分識別資訊 (PII) 和其他敏感資訊、冒犯的內容,以及提示注入或系統越獄。使用允許清單來管制 LLM 代理可使用的工具,此清單可用來管制 API 和擴充元件,只允許以明確定義的方式使用知名的網站。
不受控的 AI 與零信任成熟度模型
零信任資安架構提供了許多工具來防範不受控的 AI 所帶來的風險。「零信任成熟度模型」(Zero Trust Maturity Model) 是由美國「網路資安與基礎設施安全局」(Cybersecurity and Infrastructure Security Agency,簡稱 CISA) 所制訂,旨在協助聯邦機構遵守美國 14028 號行政命令 (EO):提升國家網路資安。它呼應了 NIST SP 800-207 所提出的零信任七大原則:
- 所有資料來源和運算服務都應被視為資源。
- 不論在網路的哪個位置,所有通訊都應受到保護。
- 個別企業資源的存取,應以個別連線階段為基礎。
- 資源的存取應透過動態的政策來加以管制。
- 企業應對其擁有及相關的資產進行完整性及安全狀況的監控和評估。
- 所有資源的認證與授權都是動態的,而且必須先嚴格執行之後才允許存取。
- 企業應盡可能蒐集有關資產、網路基礎架構及通訊當前狀態的資訊,並利用這些資訊來改善資安狀況。
要有效防範不受控 AI 的風險,企業必須達到 CISA 文件所述的「進階」(advanced) 階段:
「盡可能做到:自動化的生命週期控管以及組態設定與政策的指派和跨支柱協調、集中可視性與身分控管、跨支柱整合政策強制貫徹、回應預先定義的防範措施、根據風險與狀況評估而調整最低權限,以及建立企業整體意識 (包括外部代管的資源)。」
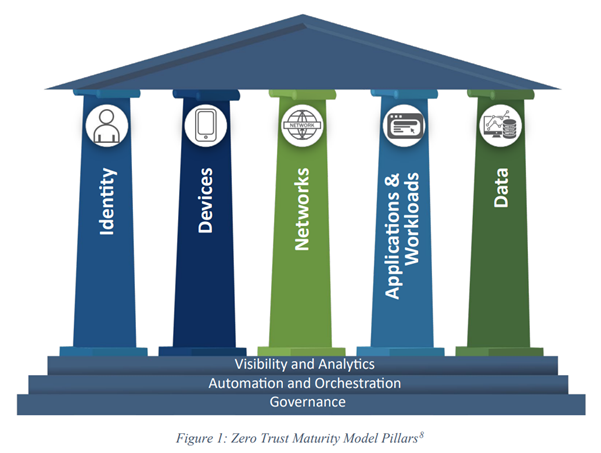
零信任支柱大致上可對應 OSI 模型的各層,提供一種更結構化的方法來指定通訊架構的層級,而非需要保護的支柱。管理每一支柱所允許的動作,是防止 AI 不受控的一種最基本防護:只有明確允許的才能做。控管、存取、信譽評等及模式偵測的自動化和協調,可提供更高層次的防禦。橫跨零信任成熟度模型各支柱的可視性,有利於發掘正常和異常的行為,進而偵測未知的情況。不受控的 AI 或許可以藉由嚴格的政策、其他規則以及 ML 活動偵測來加以防範,但最終仍必須掌握那些異常、非預期 (因而不當) 的動作。
多層式防禦與跨層級的防禦
長期而言,邁向 AI 安全之路的第一步就是要符合政策:唯有明確允許的才能做,確保 AI 獲准在一個嚴格控管的隔離環境中執行,並且限制使用者建立新的執行個體來使用 AI 服務、存取新型態資料或使用工具。此外也要確保 AI 擁有自己的授權機制,並同時受到 AI 身分與使用者身分的限制。這必須明確定義,好讓所有輸入和輸出都能被充分理解。
信譽也很重要,事實上,它是偵測已知「不良」或「良性」事物最快的方法。這就需要追蹤 AI 的身分,不同的身分會有不同的功能與信譽,視它們可能不受控的原因而定。我們必須盡可能了解它們是否可能騙人,或提供危險的指示。
基於規則與 ML 模式的偵測,可提供一道額外的防禦。資料內容的辨識,可防止機敏資訊外洩、提示注入以及模型下毒。網路偵測可顯示 AI 服務流量,針對裝置使用方式與流程的簡單規則,可對非預期的使用方式發出警報。
零信任意味著任何已知的事物都必須經過驗證,任何未知的事物都無法被信任。異常行為的偵測對資安一直是個挑戰,而且經常發生誤判的情況。提供佐證資訊可提高異常偵測的確定性,不論是來自信譽評等、規則、模式或其他行為異常狀況。異常偵測是最後一道防線,可偵測先前未知的活動。不受控的 AI 有可能出現前所未見的行為,因此請考慮針對零信任的五大支柱建立自動化 AI 行為監控:
- 身分:人類與機器的身分與行為。
- 裝置:實體與虛擬資產的掌握。
- 網路:允許、禁止和異常的通訊。
- 應用程式與工作負載:受信賴與不受信賴的 API/運算。
- 資料:內容感應的防護,例如:資料外洩防護、資料安全狀況管理 (DSPM) 以及資料偵測及回應 (DDR)。
請考慮增加上述手段來補強 (而非取代) OWASP 的防範措施。有了嚴謹、系統化的方法來防範 OSI 各層級與零信任各支柱的風險,企業就能開始實行自己的 AI 計畫,並確定其採用的 AI 能符合自己的目標。
To read more about Rouge AI: