
Искусственный интеллект (ИИ) — это технология, которая позволяет компьютерам и машинам учиться, понимать, решать проблемы, прогнозировать результаты и принимать решения.
Содержание
В самом широком смысле ИИ относится к компьютерным или машинным системам, которые используют такие технологии, как машинное обучение, нейронные сети и когнитивные архитектуры для выполнения сложных задач, которые раньше были под силу только людям.
Сюда входит все: от создания контента до планирования, рассуждения, общения, обучения на опыте и принятия сложных решений. Однако поскольку ИИ-системы и инструменты настолько обширны и разнообразны, вряд ли им можно дать единое определение.
С момента появления ИИ в 1950-х годах он изменил практически каждый аспект современной жизни, общества и технологий. Благодаря способности анализировать огромные объемы данных, понимать закономерности и приобретать новые знания, ИИ стал незаменимым инструментом практически во всех сферах человеческой деятельности, от бизнеса и транспорта до здравоохранения и кибербезопасности.
Организации находят для ИИ самые разные применения:
- Сокращение затрат.
- Стимулирование инноваций.
- Повышение эффективности сотрудников.
- Оптимизация операций.
- Ускорение принятия решений.
- Консолидация и анализ результатов исследований.
- Оперативная поддержка и обслуживание клиентов.
- Автоматизация повторяющихся задач.
- Помощь в создании идей.
Краткая история ИИ
Идея машины, которая может мыслить сама по себе, звучала еще тысячи лет назад. Искусственный интеллект, каким мы его знаем сейчас, зародился в 1950 году, когда математик и криптограф Алан Тьюринг, создатель знаменитого теста Тьюринга на определение способности машины мыслить, опубликовал свою знаменитую статью об искусственном интеллекте, Вычислительные машины и интеллект.
С тех прошло несколько десятилетий, и ИИ сделал огромный шаг вперед, в том числе благодаря значительным достижениям в области вычислительной мощности, алгоритмической сложности, доступности данных и внедрению таких технологий, как машинное обучение, интеллектуальный анализ данных и нейронные сети.
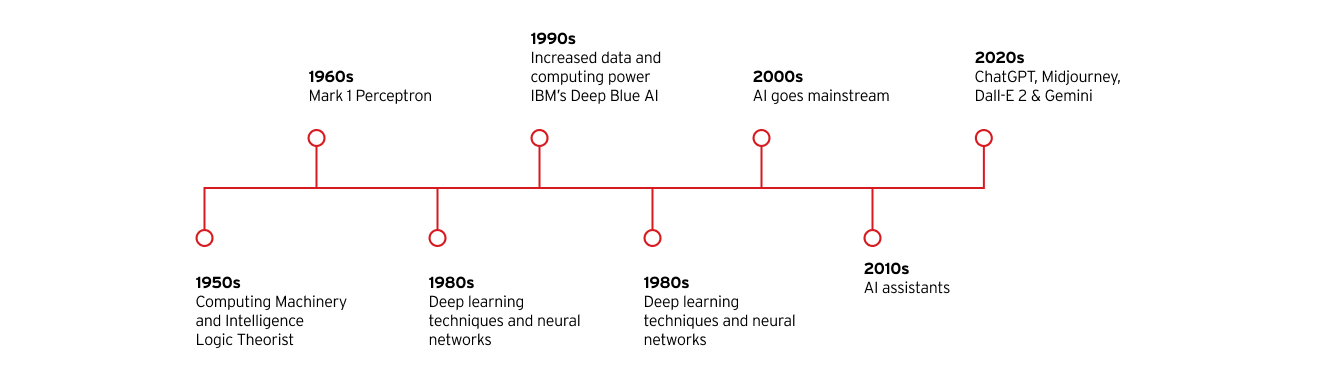
Ключевые этапы развития искусственного интеллекта
Год
Этапы
1950-е гг.
- Алан Тьюринг публикует статью «Вычислительные машины и интеллект»
- Джон Маккарти придумывает термин «искусственный интеллект»
- Разработана первая компьютерная программа с использованием ИИ — Logic Theorist
1960-е гг.
- Создан Mark 1 Perceptron, первый компьютер, который обучается методом проб и ошибок
1980-е гг.
- Технологии глубокого обучения и нейронных сетей продолжают развиваться
1990-е гг.
- Увеличение мощностей для хранения и обработки данных ускоряет рост и инвестиции в ИИ
- ИИ IBM Deep Blue побеждает чемпиона мира по шахматам Гарри Каспарова
2000-е гг.
- ИИ распространяется повсеместно с запуском поисковой системы на базе ИИ Google, системы рекомендаций Amazon, системы распознавания лиц Facebook и первых беспилотных автомобилей
2010-е гг.
- Появляются ИИ-ассистенты, такие как Siri от Apple и Alexa от Amazon
- Google запускает платформу машинного обучения с открытым исходным кодом TensorFlow
- Нейронная сеть AlexNet популяризирует использование графических процессоров (GPU) для обучения моделей ИИ
2020-е гг.
- OpenAI выпустила третью итерацию своего популярного генеративного ИИ на основе большой языковой модели (LLM) ChatGPT
- Популярность генеративных ИИ растет с выпуском генераторов изображений, таких как Midjourney и Dall-E 2, и чат-ботов на основе LLM, таких как Gemini от Google
Как работает ИИ?
Системы ИИ потребляют огромные объемы данных и используют для их анализа когнитивные процессы, похожие на человеческие. ИИ-системы выявляют и классифицируют закономерности и используют их для выполнения задач или прогнозирования будущих результатов без непосредственного надзора или инструкций со стороны человека.
Например, генератор изображений, такой как Midjourney, который получает огромное количество фотографий, может научиться создавать «оригинальные» изображения на основе запросов, введенных пользователем. Аналогичным образом, чат-бот по обслуживанию клиентов, обученный работе с большими объемами текста, может научиться взаимодействовать с клиентами таким образом, чтобы имитировать настоящих операторов.
Хотя каждая система уникальна, программирование ИИ-модели обычно следует по одному шаблону:
- Обучение: ИИ-модель получает огромные объемы данных и использует ряд алгоритмов для их анализа и оценки.
- Рассуждение: ИИ-модель классифицирует полученные данные и определяет закономерности в них.
- Дообучение: ИИ-модель пробует разные алгоритмы, узнает, какие из них наиболее успешны, и соответствующим образом корректирует свои действия.
- Генерация: ИИ-модель использует полученные знания для выполнения порученных задач, принятия решений или создания музыки, текста или изображений.
- Улучшение: наконец, ИИ-модель постоянно корректируется для повышения точности, эффективно «обучаясь» на своем опыте.

Сравнение машинного и глубокого обучения
Большинство современных систем искусственного интеллекта используют различные методы и технологии для моделирования процессов человеческого интеллекта. Наиболее важными из них являются глубокое и машинное обучение. Термины машинное и глубокое обучение иногда используются взаимозаменяемо, но на самом деле это отдельные процессы в контексте обучения ИИ.
Машинное обучение использует алгоритмы для анализа, категоризации, сортировки, изучения и «осмысления» огромных объемов данных для создания точных моделей и прогнозирования результатов без необходимости в точных указаниях.
Глубокое обучение — это подкатегория машинного обучения, в ходе которого те же цели достигаются с использованием нейронных сетей, имитирующих структуры и функции человеческого мозга. Ниже мы подробнее рассмотрим обе эти концепции.
Основные принципы машинного обучения
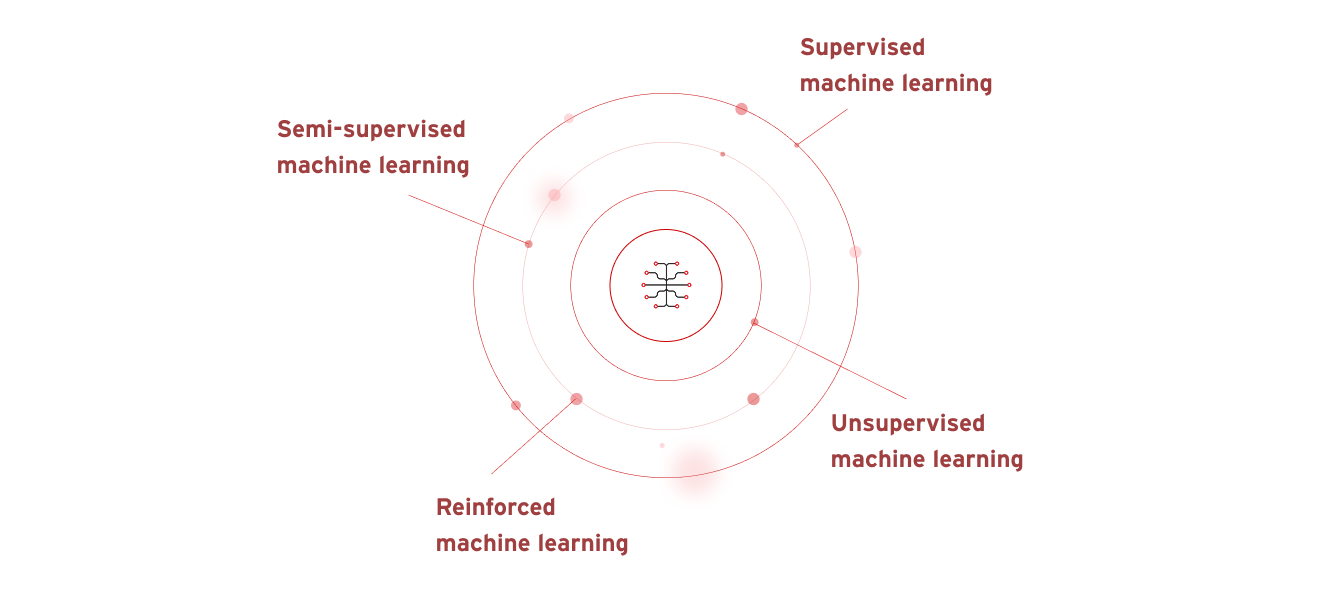
Существует четыре основных типа машинного обучения:
- Обучение с учителем — ИИ получает тщательно отобранные данные и ищет в них закономерности.
- Обучение с частичным привлечением учителя — ИИ обучается на небольшом известном и маркированном наборе данных, который затем применяется к большим, немаркированным и неизвестным наборам данных.
- Обучение без учителя — ИИ учится на неизвестных, немаркированных и неклассифицированных наборах данных.
- Машинное обучение с подкреплением — ИИ-модель изначально не обучалась на наборах данных, поэтому учится методом проб и ошибок и меняет поведение, пока результат не будет успешным.
Машинное обучение позволяет беспилотным автомобилям реагировать на изменения в окружающей среде достаточно эффективно, чтобы безопасно доставлять пассажиров в пункт назначения. Машинное обучение имеет самое широкое применение: от программ распознавания изображений и речи, машинных переводчиков, узкоспециализированных ИИ-агентов и интеллектуального анализа данных до обнаружения мошенничества с кредитными картами, диагностики заболеваний и рекомендаций постов в социальных сетях или товаров на маркетплейсах.
Глубокое обучение и нейронные сети
Глубокое обучение — это форма машинного обучения, основанная на использовании передовых нейронных сетей, то есть алгоритмов машинного обучения, которые имитируют функцию нейронов в головном мозге человека для выявления сложных закономерностей в больших наборах данных.
Например, даже маленькие дети отличают родителей от других взрослых, потому что их мозг за мгновение ока анализирует и сравнивает сотни уникальных или отличительных деталей, от цвета глаз и волос до мимики и черт лица.
Нейронные сети имитируют работу человеческого мозга, анализируя тысячи и миллионы крошечных деталей в полученных данных, чтобы обнаруживать и распознавать в них более значимые закономерности. Системы генеративного ИИ, такие как OpenAI ChatGTP или генератор изображений Midjourney, например, используют глубокое обучение для приема и анализа большого количества изображений или текста, а затем на основе этих данных создают новый текст или изображения, которые похожи на исходные данные, но отличаются от них.
Каковы последние разработки в области ИИ?
В последние годы революционные инновации в области обработки естественного языка, компьютерного зрения, обучения с подкреплением и передовых технологий, таких как генеративно-состязательные сети (GAN), Transformer-модели и машины с поддержкой ИИ (AIEM), значительно расширили возможности ИИ-систем, позволяя им более точно имитировать человеческие когнитивные процессы, генерировать более реалистичный контент и выполнять все более сложные задачи.
Прорывы в машинном и глубоком обучении
В последние годы революционные инновации в области обработки естественного языка, компьютерного зрения, обучения с подкреплением и передовых технологий, таких как генеративно-состязательные сети (GAN), Transformer-модели и машины с поддержкой ИИ (AIEM), значительно расширили возможности ИИ-систем, позволяя им более точно имитировать человеческие когнитивные процессы, генерировать более реалистичный контент и выполнять все более сложные задачи.
Прорывы в машинном и глубоком обучении
Революционные прорывы в алгоритмах машинного и глубокого обучения позволили исследователям и разработчикам создавать невероятно сложные ИИ-системы для самых разных применений.
Например, миллионы компаний ежедневно используют чат-боты на базе ИИ для ответов на вопросы, продажи продуктов и взаимодействия с клиентами. Компании также используют алгоритмы ИИ для выявления тенденций, основанных на предыдущих покупках клиента, и предоставления персонализированных рекомендаций по новым продуктам, брендам или услугам.
В области автоматического распознавания речи такие ИИ-сервисы, как Siri и Alexa, используют обработку естественного языка (NLP), чтобы преобразовать человеческую речь в текст. Аналогичным образом, достижения в нейронных сетях для компьютерного зрения упрощают отметку людей на фотографиях в социальных сетях и повышают безопасность беспилотных автомобилей.
К другим примерам ИИ, использующего машинное или глубокое обучение, относятся автоматизированные алгоритмы биржевой торговли, умные роботы, которые выполняют повторяющиеся задачи на заводах или сборочных линиях, а также выявление подозрительных банковских операций и предотвращение финансового мошенничества.
Растущая роль ИИ в кибербезопасности
Говоря о роли ИИ в кибербезопасности, необходимо учитывать две разные, но взаимосвязанные области: безопасность для ИИ и безопасность на базе ИИ.
Безопасность для ИИ означает использование мер кибербезопасности для защиты ИИ-стека организации, снижения или устранения рисков безопасности, связанных с ИИ, а также защиты каждой системы, компонента и приложения ИИ в сети, от конечных точек до ИИ-моделей. Сюда входят:
- Защита ИИ-стека, инфраструктуры, моделей и обучающих данных от атак.
- Обеспечение целостности данных в конвейерах машинного и глубокого обучения.
- Решение проблем с предвзятостью, прозрачностью, объяснимостью и других этических вопросов в связи с использованием ИИ.
Обеспечение соблюдения всех применимых законов, политик и нормативных актов при использовании и разработке ИИ.
Безопасность на базе ИИ охватывает различные способы, с помощью которых инструменты на базе ИИ проактивно улучшают защиту организации от киберугроз, действуя быстрее, точнее и эффективнее, чем любая команда по кибербезопасности или центр операций безопасности (SOC). ИИ используется для следующих задач:
- Выявление киберугроз и защита от кибератак в режиме реального времени.
- Более быстрое и точное устранение уязвимостей и пробелов в кибербезопасности.
- Автоматизация обнаружения угроз и реагирование на них, а также другие инструменты кибербезопасности для ускоренного реагирования на инциденты.
- Расширенная аналитика угроз для более эффективного управления угрозами.
- Автоматизация рутинных задач, таких как сканирование уязвимостей и анализ журналов данных, чтобы специалисты по кибербезопасности могли заниматься более сложными угрозами.
Примеры применения ИИ в области кибербезопасности
Организации уже используют ИИ разными способами для улучшения системы кибербезопасности, обнаружения кибератак и реагирования на них, а также защиты своих сетей от киберугроз, таких как утечки данных, распределенные атаки типа «отказ в обслуживании» (DDoS), программы-вымогатели, вредоносные программы, фишинговые атаки и угрозы для учетных данных.
В области обнаружения и реагирования на угрозы ИИ может выявлять и прогнозировать киберугрозы, анализировать закономерности в журналах активности и сетевом трафике, осуществлять аутентификацию и защищать пароли и учетные данные пользователей, использовать распознавание лиц и CAPTCHA для входа, моделировать кибератаки, сканировать сеть на наличие уязвимостей и создавать автоматизированные средства защиты от новых или возникающих угроз. Сюда входят такие инструменты, как:
- межсетевые экраны нового поколения (NGFW) на базе ИИ;
- управление информацией и событиями безопасности (SIEM) на базе ИИ;
- системы безопасности облака и конечных точек на базе ИИ;
- сетевое обнаружение и реагирование (NDR) на базе ИИ;
- расширенное обнаружение и реагирование (XDR) на базе ИИ.
Когда атака все же происходит, ИИ также может предложить эффективные стратегии устранения последствий или автоматически реагировать на инциденты безопасности на основе предварительно заданных политик и плейбуков. Это поможет снизить затраты и свести к минимуму ущерб от атаки, а также позволит организациям быстрее восстановиться.
Какие этические соображения связаны с разработкой и использованием ИИ?
Очевидно, что ИИ предоставляет ряд важных преимуществ по сравнению с другими типами вычислительных систем. Но, как и в случае с любой новой технологией, возникают риски, проблемы и этические вопросы, которые необходимо учитывать при разработке, внедрении и использовании ИИ.
Предвзятость и справедливость
ИИ-модели обучаются людьми с использованием данных, полученных из существующего контента. При этом возникает риск того, что модель может отражать и даже усиливать любые неявные предубеждения, содержащиеся в этом контенте. Предвзятость может привести к неравенству, дискриминации или несправедливости в алгоритмах, прогнозах и решениях, которые принимаются с использованием этих моделей.
Кроме того, поскольку они умеют создавать очень реалистичный контент, инструменты генеративного ИИ могут быть использованы не по назначению для создания или распространения дезинформации, вредоносного контента и дипфейковых видео, аудио и изображений.
Проблемы конфиденциальности
С разработкой и использованием ИИ связаны проблемы конфиденциальности, особенно в таких отраслях, как здравоохранение, банковская деятельность и юридические услуги, которые имеют дело с закрытой, чувствительной и конфиденциальной информацией.
Чтобы защитить эту информацию, приложения на основе ИИ должны следовать четкому набору передовых практик в области безопасности, конфиденциальности и защиты данных. Сюда входит использование методов анонимизации, надежное шифрование данных и применение передовых средств защиты от кражи и утечки данных и хакерских атак.
Комплаенс
Многие регулирующие органы и структуры, такие как Общий регламент по защите данных (GDPR), требуют от компаний следовать четким наборам правил при защите персональных данных, обеспечении прозрачности и подотчетности, а также поддержании конфиденциальности.
Для соблюдения этих правил организации должны внедрить корпоративные политики использования ИИ для мониторинга и контроля данных, которые используются для создания новых ИИ-моделей, а также для защиты от злоумышленников любых ИИ-моделей, содержащих чувствительную информацию или персональные данные.
Каково будущее технологий ИИ?
Дать точный прогноз сложно, но можно сделать несколько обоснованных предположений о том, что будет дальше, исходя из текущих трендов использования и технологий ИИ.
Новые тренды в исследованиях ИИ
Инновации в автономных ИИ-системах, мета-ИИ и метаобучение, LLM-модели с открытым исходным кодом, цифровые двойники и красные команды для тестирования рисков, а также совместное принятие решений человеком и ИИ могут значительно изменить способы разработки ИИ.
Сложные новые системы, такие как нейросимволический ИИ, машины с настоящей поддержкой ИИ (AIEM) и квантовое машинное обучение, вероятно, еще больше расширят охват и возможности ИИ-моделей, инструментов и приложений.
Еще одна технология, способная изменить работу ИИ, — это переход к агентскому ИИ нового поколения, который будет принимать решения и действовать самостоятельно, без человеческого руководства, надзора или вмешательства.
По словам технического аналитика Gartner, к 2028 году агентский ИИ может принимать до 15% ежедневных рабочих решений. Пользовательские интерфейсы ИИ-агентов также могут стать более проактивными и специализированными, поскольку они будут учиться действовать как сотрудники-люди с набором личных характеристик, выполнять более сложные бизнес-задачи, принимать более важные бизнес-решения и предоставлять более персонализированные рекомендации клиентам.
Потенциальные последствия ИИ для персонала
Поскольку ИИ повышает операционную эффективность и берет на себя рутинные задачи, а генеративные ИИ, такие как ChatGPT и Midjourney, становятся все более функциональными и популярными, возникают опасения по поводу сохранения рабочих мест во многих отраслях.
Но, как и в случае с внедрением Интернета, персональных компьютеров, мобильных телефонов и других технологий, меняющих парадигму, ИИ, скорее всего, также создаст новые возможности и, возможно, даже целые новые отрасли, в которых требуются квалифицированные и талантливые работники.
В результате встанет вопрос не о потере работы, а о подходах к обучению работников, чтобы они использовали новые возможности и приспосабливались к новым профессиям.
Роль ИИ в решении глобальных проблем
ИИ уже повышает операционную эффективность и укрепляет кибербезопасность, а в будущем, возможно, сможет решать самые сложные задачи, с которыми сегодня сталкивается человечество.
В области здравоохранения ИИ поможет врачам быстрее и точнее диагностировать заболевания, отслеживать распространение будущих пандемий и ускорять открытие новых фармацевтических препаратов, методов лечения и вакцин.
Технологии ИИ могут повысить скорость и эффективность реагирования на стихийные бедствия, суровые погодные условия и антропогенные катастрофы.
ИИ может помочь справиться с изменением климата путем оптимизированного использования возобновляемых источников энергии, снижения углеродного следа предприятий, отслеживания вырубки лесов и загрязнения океана, а также повышения эффективности систем переработки, очистки воды и управления отходами.
Другие вероятные тренды
Другие вероятные тренды, возможности и применения ИИ:
- Безопасность больших языковых моделей (LLM) — для защиты LLM от вредоносных атак, ненадлежащего использования, несанкционированного доступа и других киберугроз. Сюда входят меры по защите данных LLM, моделей и связанных с ними систем и компонентов.
- Персонализированный, ориентированный на пользователя ИИ — для продуманного и индивидуального подхода к клиентам, в том числе для маркетинга по электронной почте.
- Использование ИИ-моделей для красных команд ицифровых двойников путем имитации атак на ИТ-системы организации для проверки на наличие уязвимостей и устранения любых недостатков или слабых мест.
Где получить помощь по ИИ и кибербезопасности?
Trend Vision One™ обеспечивает непревзойденную комплексную защиту всего ИИ-стека с помощью единой централизованной платформы на базе ИИ.
Используя широкие возможности Trend Cybertron — первого в мире проактивного ИИ в области кибербезопасности, — Trend Vision One включает набор функций агентского ИИ, которые постоянно развиваются на основе реальных аналитических данных и операций безопасности.
Такой подход позволяет быстро адаптироваться к новым угрозам, чтобы укрепить безопасность организации, повысить операционную эффективность, перейти от реактивного к проактивному подходу и защитить каждый уровень инфраструктуры ИИ.


Фернандо Кардосо занимает должность вице-президента по управлению продуктами в Trend Micro. Особое внимание он уделяет постоянно меняющимся технологиям ИИ и облаков. Он начал карьеру как инженер по сетям и инженер по продажам в сфере центров обработки данных, облака, DevOps и кибербезопасности. Эти темы по-прежнему увлекают его.
Часто задаваемые вопросы
Что такое ИИ?
Искусственный интеллект (ИИ) — это компьютер, который использует технологии для имитации человеческого мышления, функционирования и принятия решений.
Что на самом деле делает ИИ?
ИИ-модели используют сложные алгоритмы и огромные объемы «усвоенной» информации для вывода ответов на вопросы пользователей или создания контента на основе промптов.
Siri — это ИИ?
Siri — это простая форма ИИ, которая использует такие технологии, как машинное обучение и распознавание речи, чтобы понимать речь человека и реагировать на нее.
ИИ хороший или плохой?
Как и все технологии, искусственный интеллект по своей природе не является хорошим или плохим. Это инструмент, который можно использовать как в благих, так и в дурных целях.
Какова основная цель ИИ?
Главная цель ИИ — помочь компьютерам принимать более разумные решения, выполнять более сложные задачи и учиться на опыте без постоянного участия людей.
Почему был создан ИИ?
ИИ был разработан для автоматизации повторяющихся задач, решения сложных проблем, поддержки передовых исследований и создания инноваций в различных отраслях.
Какие риски связаны с ИИ?
Опасения вокруг ИИ связаны с предвзятостью и несправедливостью ответов, рисками для конфиденциальности и кибербезопасности, а также потерей рабочих мест.
Кто создал ИИ?
Ученые-информатики Алан Тьюринг (1912–1954 гг.) и Джон Маккарти (1927–2011 гг.) обычно считаются неофициальными «отцами ИИ».
Как применяется ИИ в повседневной жизни?
Мы часто используем ИИ в повседневной жизни: от программного обеспечения на смартфоне до чат-ботов, которые отвечают на вопросы в службе поддержки.
Приведите пример простого ИИ.
Примерами простых ИИ являются голосовые помощники, такие как Siri или Alexa, интеллектуальные поисковые системы, такие как Google, чат-боты службы поддержки и даже роботы-пылесосы.
Каковы недостатки ИИ?
Опасения вокруг ИИ связаны с предвзятостью, конфиденциальностью, рисками для кибербезопасности, а также потерей рабочих мест в некоторых отраслях.
Какие пять недостатков можно выделить у ИИ?
В зависимости от применения ИИ может привести к потере рабочих мест, распространению дезинформации, компрометации частной информации, снижению креативности и чрезмерной зависимости от технологий.
Как включить ИИ?
Большинство ИИ-инструментов можно включать и выключать в настройках смартфонов, компьютеров, приложений и сайтов.
Могу ли я бесплатно использовать ИИ?
Многие ИИ-инструменты, такие как поисковые системы или Alexa, предоставляются абсолютно бесплатно. Другие, такие как ChatGPT, предлагают как бесплатные, так и платные варианты. ИИ коммерческого уровня обычно предоставляется платно.
Какой ИИ предоставляется абсолютно бесплатно?
Большинство компаний по разработке ИИ предлагают бесплатные пробные версии, включая Microsoft Copilot, Grammarly, Google Gemini и ChatGPT.
Какое ИИ-приложение наиболее популярно сейчас?
В настоящее время наиболее популярными приложениями с ИИ являются ChatGPT, Google Maps, Google Assistant, Microsoft Copilot и Google Gemini.
Какое ИИ-приложение для создания текстов самое популярное?
Самые популярные приложения для написания текстов с помощью ИИ: Grammarly, ChatGPT, Writesonic, Jasper и Claude.
Какое ИИ-приложение предоставляется бесплатно?
Google Gemini, Microsoft Copilot и ChatGPT являются одними из наиболее широко используемых бесплатных ИИ-приложений.
Какой чат-бот на базе ИИ сейчас считается лучшим?
Лучший чат-бот зависит от ваших целей, но некоторые из самых популярных чат-ботов с ИИ включают Perplexity, Google Gemini, Jasper и ChatGPT.
Приведите пример ИИ в повседневной жизни.
Распространенными примерами применения ИИ в повседневной жизни являются смартфоны, поисковые системы на базе ИИ, чат-боты службы поддержки и цифровые голосовые помощники, такие как Siri и Alexa.
Статьи по теме
10 основных рисков и мер по их снижению для LLM и генеративного ИИ в 2025 году
Управление возникающими рисками для общественной безопасности
Как далеко заведут нас международные стандарты?
Как написать политику кибербезопасности для генеративного ИИ
Атаки с использованием ИИ — один из самых серьезных рисков
Распространение угроз, связанных с дипфейками