Was ist maschinelles Lernen (ML)?
Maschinelles Lernen Definition
Machine Learning ist eine Form der künstlichen Intelligenz (KI), die es einem System erlaubt, iterativ aus Daten zu lernen, indem es verschiedene Algorithmen verwendet, um sie zu beschreiben und Ergebnisse vorherzusagen, indem es aus Trainingsdaten lernt, die präzise Modelle erzeugen.
Dass Computer ohne explizite Anweisung wissen, was zu tun ist, war lange Zeit reine Fiktion.
Das autonome Fahrzeug, das alles für Sie erledigt, während Sie (natürlich auf dem Fahrersitz) mitfahren, ist Machine Learning (ML) in Aktion. Das Fahrzeug fährt komplett eigenständig, erkennt Fußgänger und Schlaglöcher und reagiert schnell und effizient auf Umgebungsänderungen, damit Sie sicher an Ihrem Ziel ankommen.
Funktionsweise Analysieren wir zunächst lediglich Geschäftsdaten.
ML ist eine Art der KI, bei der Unternehmen große Datenmengen nutzen und daraus lernen können. Denken Sie zum Beispiel an Twitter. Laut Internet Live Stats senden Twitter-Anwender täglich etwa 500 Millionen Tweets, also ungefähr 200 Milliarden Tweets jährlich. Menschen können diese Anzahl an Tweets schlichtweg nicht analysieren, kategorisieren, sortieren, nicht aus ihnen lernen und keine Prognosen ableiten.
Wie maschinelles Lernen Unternehmen helfen kann
Maschinelles Lernen schützt Unternehmen vor Cyberbedrohungen. Sie funktioniert jedoch am besten als Teil einer mehrschichtigen Sicherheitslösung.
Damit Unternehmen durch Machine Learning nützliche Informationen erhalten, ist ein erheblicher Aufwand erforderlich. Sie müssen über bereinigte Daten verfügen und Ihre Fragen dazu kennen, um von ML bestmöglich zu profitieren. Erst dann können Sie für Ihr Unternehmen das beste Modell und den besten Algorithmus auswählen. ML ist kein einfacher Prozess. Um erfolgreich zu sein, bedarf es sorgfältiger Arbeit.
Es gibt einen Lebenszyklus für ML:
- Verständnis: Warum setzen Sie ML ein und was möchten Sie tun oder lernen?
- Datenerfassung und -bereinigung: Sie verfügen über die erforderliche Menge an Daten, und diese sind so bereinigt, dass Sie die erforderlichen Erkenntnisse gewinnen können.
- Funktionsauswahl: Um ein ML-Modell zu bauen, bestimmen Sie die in das ML zu integrierenden Daten. Je nach Algorithmustyp, den Sie verwenden, stehen verschiedene Methoden zur Verfügung, die Ihnen die Auswahl von Funktionen erleichtern. Angenommen, Sie verwenden einen Entscheidungsstrukturalgorithmus. In diesem Fall kann das Analyse- oder Modellierungstool durch „Relevanzbewertung“ feststellen, ob die Daten in den Spalten einer Datenbank zum Erstellen Ihres Modells verwendet werden sollen.
- Modellauswahl: Ausgewählt wird die Datei (das Modell), die (bzw. das) für die Verarbeitung und Suche nach bestimmten Elementen in den Daten trainiert wurde. Ein Modell zieht seine Schlüsse aus der Kombination des Algorithmus und der Testdaten, die ihm zugewiesen wurden.
- Training und Optimierung: Das Modell zieht Schlüsse für Sie, damit Sie Antworten auf Ihre Fragen erhalten.
- Auswertung: Modell und Algorithmus werden ausgewertet, um die Einsatzbereitschaft zu bestimmen. Möglicherweise müssen Sie ein paar Schritte zurückgehen, um das Modell, die Funktion, den Algorithmus oder die Daten mit Blick auf Ihre Ziele zu optimieren.
- Bereitstellung des trainierten Modells in der Produktion
- Überprüfung der Ergebnisse des vorhandenen Modells in der Produktion
Machine Learning – Anwendungsbereiche
Durch Machine Learning können Unternehmen Ihre Daten verstehen und aus ihnen lernen. Ein Unternehmen kann ML für eine Vielzahl von Teilbereichen verwenden. Der Anwendungsfall hängt davon ab, was ein Unternehmen erreichen will: die Umsätze erhöhen, eine Suchfunktion bereitstellen, Sprachbefehle in sein Produkt integrieren oder ein selbstfahrendes Auto entwickeln.
Machine Learning – Teilbereiche
ML hat in der heutigen Geschäftswelt eine fantastische Bandbreite an Einsatzmöglichkeiten, und mit der Zeit kann es nur besser werden. Zu den Teilbereichen des ML zählen etwa Social Media und Produktempfehlungen, Bilderkennung, Gesundheitsdiagnostik, Sprachübersetzung, Spracherkennung und Data Mining.
Social-Media-Plattformen wie Facebook, Instagram oder LinkedIn verwenden ML, um Ihnen anhand Ihrer Likes Seiten oder Gruppen vorzuschlagen, denen Sie folgen oder beitreten könnten. ML verwendet Verlaufsdaten dazu, was anderen gefallen hat oder welche Posts denen ähneln, die Ihnen gefallen haben, unterbreitet Ihnen diese Vorschläge oder fügt sie zu Ihrem Feed hinzu.
ML kann auch auf einer E-Commerce-Website verwendet werden, um Ihnen Produkte zu empfehlen. Basis dafür könnten Ihre früheren Käufe sein, Ihre Suchvorgänge und Aktionen anderer Anwender, die Ihren ähneln.
Ein wichtiger Anwendungsbereich für ML ist heute die Bilderkennung. Social-Media-Plattformen empfehlen, Personen anhand ML auf Ihren Fotos zu kennzeichnen. Die Polizei kann damit in Bildern oder Videos nach Verdächtigen suchen. Aufgrund der vielen in Flughäfen, Geschäften und an Türklingeln angebrachten Kameras kann ermittelt werden, wer ein Verbrechen begangen hat oder wohin der Kriminelle verschwunden ist.
Auch die Gesundheitsdiagnose ist ein guter Einsatzbereich für ML. Nach einem Vorfall wie einem Herzinfarkt ist es möglich, zurückzublicken und Warnzeichen zu erkennen, die übersehen wurden. Ein von Ärzten oder Krankenhäusern verwendetes System könnte auf frühere Krankenakten zurückgreifen und Rückschlüsse ziehen. Dadurch ließen sich Verbindungen von der Eingabe (Verhalten, Testergebnis oder Symptom) bis zur Ausgabe (z. B. einem Herzinfarkt) nachvollziehen. Wenn der Arzt künftig seine Notizen und Testergebnisse in das System eingibt, könnte der Computer Herzinfarktsymptome viel zuverlässiger erkennen als Menschen. Der Patient und der Arzt oder die Ärztin könnten Maßnahmen ergreifen, um einen Herzinfarkt zu verhindern.
Ein weiterer Einsatzbereich für ML ist die Sprachübersetzung auf Internetseiten oder Apps für mobile Plattformen. Einige Apps liefern bessere Ergebnisse als andere. Dies hängt vom jeweiligen Einsatz des ML-Modells, der Technik und den Algorithmen ab.
Bei Bank- und Kreditkarten kommt ML heute täglich zum Einsatz. ML kann Betrugsanzeichen schnell erkennen. Menschen bräuchten dafür lange, so es ihnen überhaupt gelänge. Durch die Vielzahl der geprüften und gekennzeichneten Transaktionen (Betrug oder nicht) kann sich das ML weiterentwickeln und künftig Betrugsfälle in einzelnen Transaktionen erkennen. ML eignet sich hervorragend für das Data Mining.
Data Mining
Data Mining ist eine Art des ML, bei der Daten analysiert werden, um Prognosen zu erstellen oder Muster in großen Daten zu erkennen. Der Begriff ist ein wenig irreführend. Niemand – sei es ein Angreifer oder Mitarbeiter – wird angehalten, in Ihren Daten nach etwas Nützlichem zu suchen. Vielmehr werden im Rahmen des Prozesses Datenmuster erkannt, die bei künftigen Entscheidungen helfen.
Denken Sie zum Beispiel an ein Kreditkartenunternehmen. Wenn Sie eine Kreditkarte haben, hat Ihre Bank Sie wahrscheinlich schon einmal benachrichtigt, dass es eine verdächtige Aktivität im Zusammenhang mit Ihrer Karte gab. Wie kann die Bank eine solche Aktivität so schnell feststellen und beinahe sofort eine Warnung senden? Diesen Schutz vor Betrug ermöglicht kontinuierliches Data Mining. Allein in den USA wurden seit Anfang 2020 über 1,1 Billionen Karten ausgestellt. Aus der Anzahl der Transaktionen dieser Karten ergeben sich vielfältige Daten für das Mining, für die Suche nach Mustern und für das Lernen. Dadurch können künftig verdächtige Transaktionen erkannt werden.
Deep Learning
Deep Learning ist eine bestimmte Art des ML, die auf neuronalen Netzen basiert. Ein neuronales Netz ahmt nach, wie die Neuronen in einem menschlichen Gehirn funktionieren, wenn sie eine Entscheidung treffen oder etwas verstehen. So unterscheidet beispielsweise ein sechsjähriges Kind durch einen Blick in ein Gesicht seine Mutter von der Verkehrshelferin. Das Gehirn analysiert innerhalb eines Wimpernschlags viele Details, etwa die Haarfarbe, Gesichtsmerkmale und Narben. Machine Learning repliziert dies in Form von Deep Learning.
Ein neuronales Netz hat drei bis fünf Schichten: eine Eingabeschicht, ein bis drei versteckte Schichten und eine Ausgabeschicht. Die versteckten Schichten treffen die Entscheidungen und arbeiten nacheinander auf die Ausgabeschicht oder die Schlussfolgerung hin. Welche Haarfarbe? Welche Augenfarbe? Ist da eine Narbe? Gehen die Schichten in die Hunderte, ist von Deep Learning die Rede.
Machine Learning – Arten
Es gibt im Wesentlichen vier Arten von Algorithmen im Machine Learning: überwacht, halbüberwacht, nicht überwacht und verstärkend. ML-Experten gehen davon aus, dass von den heute verwendeten ML-Algorithmen etwa 70 % überwacht werden. Sie funktionieren mit bekannten oder bezeichneten Datensets, etwa Bildern von Hunden und Katzen. Diese beiden Arten von Tieren sind bekannt. Entsprechend können Administratoren die Bilder bezeichnen, bevor sie diese an den Algorithmus übergeben.
Nicht überwachte ML-Algorithmen lernen aus unbekannten Datensets. Ein Beispiel dafür sind TikTok-Videos. Es gibt so viele Videos mit so vielen Themen, dass es unmöglich ist, einen Algorithmus überwacht damit anzulernen. Die Daten sind noch nicht bezeichnet.
Halbüberwachte ML-Algorithmen werden anfänglich mit einem kleinen Datenset trainiert, das bekannt und bezeichnet ist. Anschließend werden sie auf ein größeres, unbezeichnetes Datenset angewendet, um das zugehörige Training fortzusetzen.
Verstärkende ML-Algorithmen werden nicht anfänglich trainiert. Sie lernen aus Tests und zwischenzeitlichen Fehlern. Stellen Sie sich einen Roboter vor, der lernt, durch einen Steinhaufen zu navigieren. Er lernt bei jedem Sturz, was nicht funktioniert hat, und ändert sein Verhalten, bis er erfolgreich ist. Denken Sie etwa an das Hundetraining und den Einsatz von Leckerbissen zum Trainieren verschiedener Kommandos. Eine positive Verstärkung bewirkt, dass der Hund weiterhin auf die Kommandos reagiert und sein Verhalten ändert, wenn es zu keiner positiven Reaktion führt.
Überwachtes Machine Learning
Dabei werden bekannte, bestehende und klassifizierte Datensets verwendet, um Muster zu erkennen. Dies lässt sich anhand der vorherigen Idee der Bilder von Hunden und Katzen veranschaulichen. Angenommen, Sie verfügen über einen riesigen Datensatz mit Tausenden von unterschiedlichen Tieren in Millionen von Bildern. Da die Tierarten bekannt sind, könnten diese gruppiert und bezeichnet werden, bevor sie dem überwachten ML-Algorithmus übergeben werden, damit er daraus seine Schlüsse ziehen kann.
Der überwachte Algorithmus vergleicht nun die Eingabe mit der Ausgabe und das Bild mit der Bezeichnung der Tierart. Mit der Zeit wird er lernen, eine bestimmte Tiergattung in neuen Fotos zu erkennen.
Nicht überwachtes Machine Learning
Nicht überwachte ML-Algorithmen agieren wie heutige SPAM-Filter. Anfangs konnten Administratoren SPAM-Filter so programmieren, dass sie in der E-Mail nach bestimmten Wörtern suchten, um SPAM zu verstehen. Das ist nicht mehr möglich, deshalb eignen sich in diesem Fall nicht überwachte. Der nicht überwachte ML-Algorithmus wird mit nicht bezeichneten E-Mails gefüttert, damit er darin nach Mustern zu suchen beginnt. Finden sich solche Muster, lernt er, wie SPAM aussieht, und ermittelt ihn in der Produktionsumgebung.
Instanzbasiertes maschinelles Lernen
Ein weiterer Typ ist instanzbasiertes maschinelles Lernen, das neu aufgetretene Daten mit Trainingsdaten korreliert und basierend auf der Korrelation Hypothesen erstellt. Dazu verwendet instanzbasiertes maschinelles Lernen schnelle und effektive Matching-Methoden, um gespeicherte Trainingsdaten zu referenzieren und mit neuen, nie zuvor gesehenen Daten zu vergleichen. Es verwendet bestimmte Instanzen und berechnet Entfernungswerte oder Ähnlichkeiten zwischen bestimmten Instanzen und Trainingsinstanzen, um eine Vorhersage zu erstellen. Ein instanzbasiertes Modell für maschinelles Lernen ist ideal, um sich an zuvor nicht erkannte Daten anzupassen und daraus zu lernen.
Machine Learning – Techniken
Durch ML-Techniken lassen sich Probleme beheben. Welche spezifische ML-Technik Sie auswählen, hängt von Ihrem jeweiligen Problem ab. Es folgen sechs allgemeine Techniken.
Regression
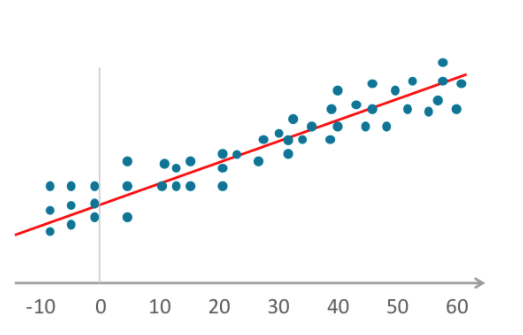
Mithilfe der Regression lassen sich Inlandspreise prognostizieren oder etwa der optimale Verkaufspreis einer Schneeschaufel in München im Dezember bestimmen. Die Regression besagt, dass die Preise zwar schwanken, aber immer wieder zum Durchschnittspreis zurückkehren. Selbst wenn die Immobilienpreise im Lauf der Zeit steigen, gibt es einen Durchschnittswert, der sich immer wieder einpegelt. Sie können die Preise im Verlauf in einem Diagramm darstellen und mit der Zeit den Mittelwert feststellen. Anhand der roten Linie, die im Diagramm weiter nach oben wandert, lassen sich Zukunftsprognosen treffen.
Klassifizierung
Mithilfe der Klassifizierung werden Daten in bekannte Kategorien gruppiert. Sie könnten nach Kunden suchen, die laut Prognose gut sind, also immer wiederkommen und Geld ausgeben, oder nach solchen, die abwandern. Wenn Sie aus der Vergangenheit Prädiktoren für die jeweilige Klassifizierung ermitteln, können Sie diese auf die aktuellen Kunden anwenden und prognostizieren, zu welcher Gruppe die Kunden gehören. Anschließend können Sie die Vermarktung effektiver gestalten und einen potenziell abwandernden Kunden möglicherweise zu einem hervorragenden Stammkunden konvertieren. Dies ist ein gutes Beispiel für überwachtes ML.
Clustering
Clustering zählt im Gegensatz zur Klassifizierungstechnik zum nicht überwachten ML. Beim Clustering ermittelt das System, wie Daten gruppiert werden sollen, bei denen Sie nicht wissen, wie das geschehen soll. Diese Art des ML eignet sich bestens zum Analysieren medizinischer Bilder und sozialer Netzwerke oder zum Ermitteln von Anomalien.
Google verwendet Clustering für die Generalisierung, die Datenkomprimierung und die Datenschutzwahrung in Produkten, etwa in YouTube-Videos, Play-Apps und Musik-Titeln.
Anomalieerkennung
Mithilfe der Anomalieerkennung wird nach Ausreißern gesucht, etwa nach dem schwarzen Schaf in einer Herde. Bei einer riesigen Datenmenge können Menschen solche Anomalien unmöglich ermitteln. Wenn jedoch beispielsweise ein Data Scientist medizinische Abrechnungsdaten aus vielen Krankenhäusern in ein System implementiert, würde die Anomalieerkennung eine Möglichkeit finden, die Abrechnungsdaten zu gruppieren. Sie könnte auch eine Reihe von Ausreißern erkennen, die auf Betrug hindeuten.
Marktkorbanalyse
Die Logik der Marktkorbanalyse ermöglicht Prognosen. Einfaches Beispiel: Wenn Kunden Rinderhack, Tomaten und Tacos in ihren Korb legen, könnten Sie prognostizieren, dass sie auch Käse und Sour Cream hinzufügen. Anhand dieser Prognosen lassen sich zusätzliche Umsätze generieren, indem Online-Käufer Vorschläge zu Artikeln erhalten, die Sie vergessen haben könnten, oder indem Produkte in einem Geschäft gruppiert werden.
Zwei Professoren am MIT nutzten diesen Ansatz, um den „Harbinger of Failure“ (Vorboten des Fehlers) zu erkennen. Wie sich herausgestellt hat, mögen manche Kunden erfolglose Produkte. Wenn Sie diese erkennen können, haben Sie die Wahl, ob Sie ein Produkt weiterhin vertreiben oder nicht. Außerdem können Sie die Marketingstrategie festlegen, die Sie anwenden wollen, um den Umsatz mit den richtigen Kunden zu erhöhen.
Zeitreihendaten
Mithilfe von Fitnessarmbändern werden über viele von uns Zeitreihendaten erhoben. Diese Armbänder können die Herzschläge pro Minute, Schritte pro Minute oder Stunde und sogar die Sauerstoffsättigung über einen Zeitraum erfassen. Anhand dieser Daten ließe sich prognostizieren, wann jemand künftig läuft. Möglich wäre auch, auf Basis zeitbasierter Daten über Schwingungsniveau, Geräuschpegel (dB) und Druck Daten über Maschinen- und Prognosefehler erfassen.
Machine Learning – Algorithmen
Wenn ML aus Daten lernen soll, wie entwerfen Sie dann einen Algorithmus zum Lernen und Ermitteln der statistisch signifikanten Daten? ML-Algorithmen unterstützen den Prozess des überwachten, nicht überwachten oder Verstärkungs-ML.
Data Engineers schreiben Codestücke, die Algorithmen darstellen, die es einer Maschine ermöglichen, zu lernen oder Signifikanz in Daten zu finden.
Nachfolgend sehen Sie bestimmte Algorithmen, die am gängigsten sind. Hier sind Top 5, die heute verwendet werden.
- Linear-Regression-Algorithmen bauen eine Beziehung auf. Dazu bauen sie unabhängige und abhängige Variablen in ein Diagramm ein und ziehen eine gerade Linie für den Mittelwert oder den Trend. Laut Merriam-Webster ist die Regression „eine Funktion, die den Wert einer Zufallsvariablen vorhersagt unter der Bedingung, dass eine oder mehrere unabhängige Variablen bestimmte Werte annehmen.“ Diese Definition gilt auch für die logistische Regression.
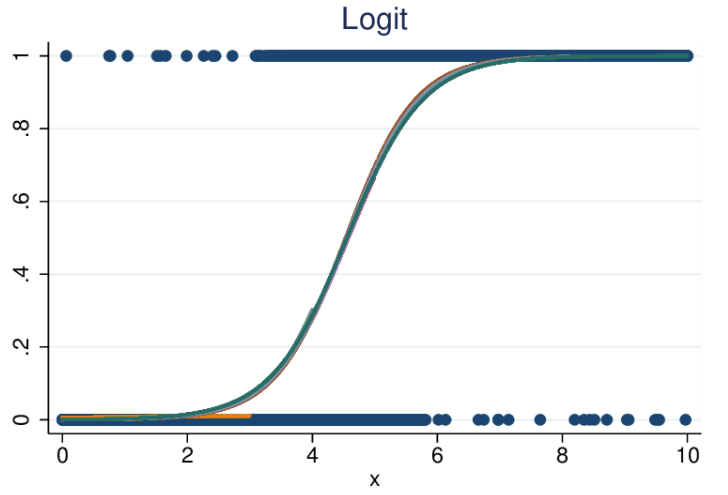
- Bei der (auch als „Logit“ bezeichneten) logistischen Regression werden Variablen ebenfalls an einen Graphen angepasst, die Beziehung ist jedoch nicht linear. Die Linie hier ist eine Sigmoidfunktion.
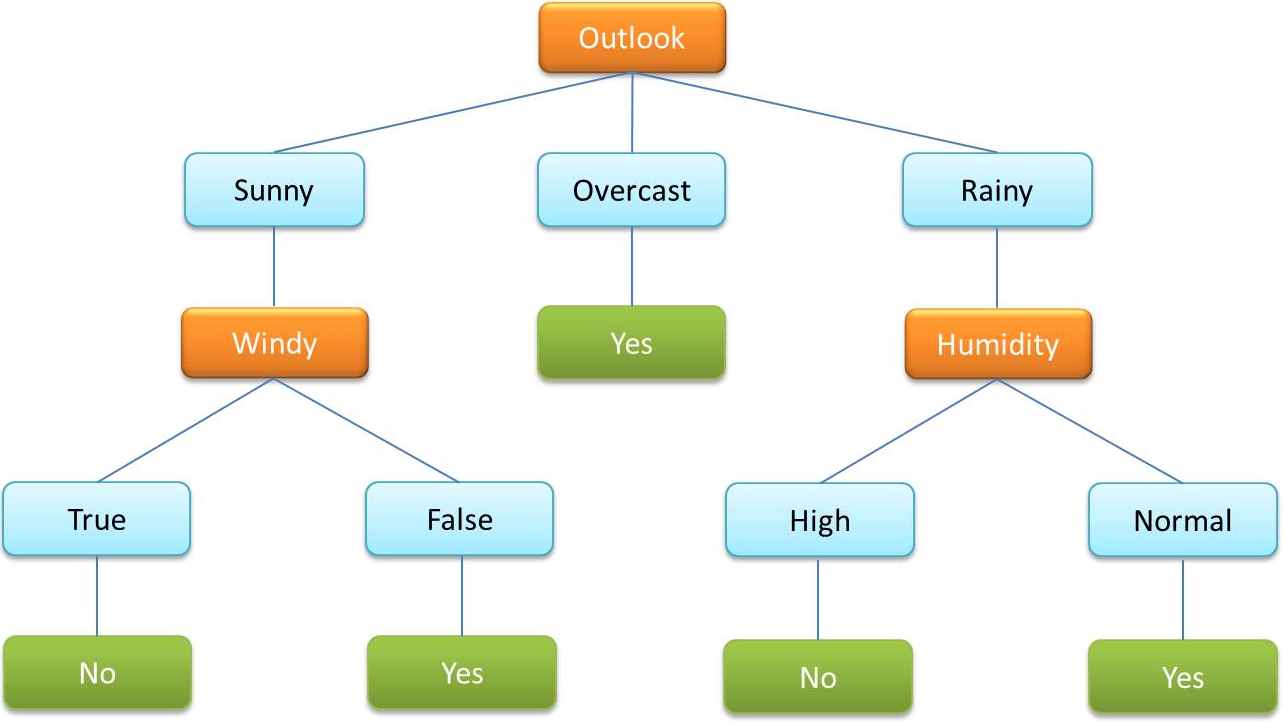
- Ein Entscheidungsbaum ist ein beim überwachten ML sehr häufig eingesetzter Algorithmus. Damit werden Daten nach kategorialen und kontinuierlichen Variablen klassifiziert.
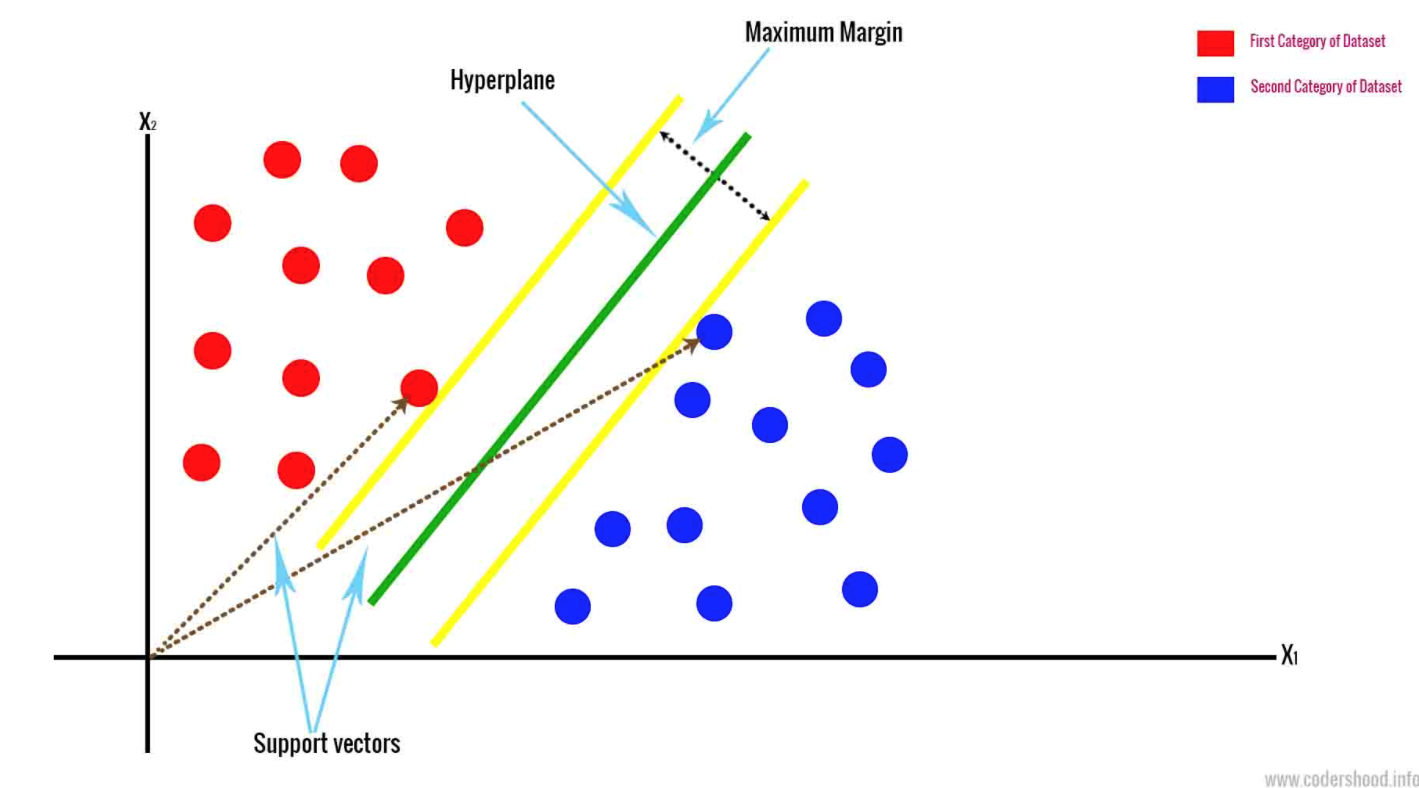
- Die Stützvektormethode zieht auf Basis der zwei nächstgelegenen Datenpunkte eine Hyperebene. Dies trennt die Daten, indem die Klassen ausgeklammert werden. Die Daten werden anhand eines N-dimensionalen Raums klassifiziert. N steht für die Anzahl unterschiedlicher Funktionen, über die Sie verfügen.
- Der Naïve-Bayes-Klassifikator berechnet die Wahrscheinlichkeit eines bestimmten Ergebnisses. Er ist sehr effektiv und übertrifft komplexere Klassifizierungsmodelle. Das Modell eines Naïve-Bayes-Klassifikators versteht, dass ein Merkmal nicht mit dem Vorhandensein anderer bestimmter Merkmale zusammenhängt.
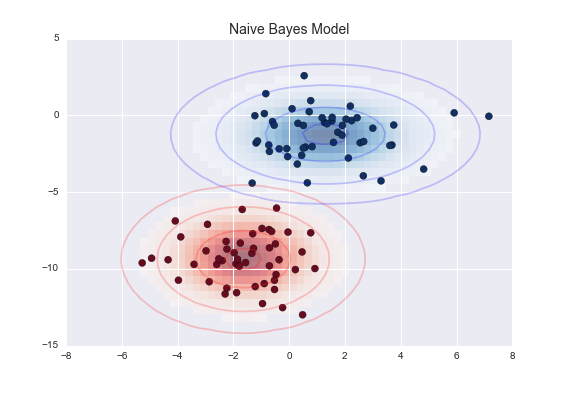
Machine Learning – Modelle
Durch die Kombination der Art des ML (überwacht, nicht überwacht usw.) mit den Techniken und Algorithmen entsteht eine trainierte Datei. Diese Datei kann nun mit neuen Daten gefüttert werden. Sie kann Muster erkennen und nach Bedarf Prognosen oder Entscheidungen für das Unternehmen, den Manager oder den Kunden treffen.
Beste Sprachen für das Machine Learning
Machine-Learning-Sprachen geben an, wie Anweisungen für das System geschrieben werden, damit das System daraus lernen kann. Für jede Sprache gibt es eine Anwender-Community, um von anderen zu lernen oder andere anzuleiten. In jeder Sprache sind Librarys enthalten, die für Machine Learning eingesetzt werden können.
Nachfolgend finden Sie die Top 10 gemäß der Top 10 survey in 2019 (Umfrage zu den Top 10 aus dem Jahr 2019) von GitHub.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala – eine Sprache, die für Interaktionen mit großen Daten verwendet wird
Python-basiertes Machine Learning
Da Python die am weitesten verbreitete ML-Sprache ist, steht sie im Folgenden im Fokus.
Python wurde nach Monty Python benannt und ist eine interpretierte, objektorientierte Open-Source-Sprache. Da sie interpretiert ist, wird sie in Bytecode konvertiert, bevor sie durch eine Python Virtual Machine ausgeführt werden kann.
Aufgrund einer Vielzahl von Funktionen eignet sich Python besonders für ML.
- Eine große Reihe leistungsstarker Pakete, die direkt eingesetzt werden können. Es gibt bestimmte ML-Pakete, etwa NumPy, SciPy und PAnandas.
- Prototypen sind einfach und schnell zu erstellen.
- Es gibt eine Vielzahl von Collaboration Tools.
- Wenn ein Data Scientist von der Extrahierung zur Modellierung übergeht und dabei seine ML-Lösung aktualisiert, kann er durchgängig Python als Sprache der Wahl verwenden. Der Data Scientist muss die Sprache nicht ändern, während er den Lebenszyklus durchläuft.
Maschinelles Lernen und Cybersicherheit
Das Aufkommen von Ransomware hat das maschinelle Lernen ins Rampenlicht gerückt, da Ransomware-Angriffe zum Zeitpunkt Null erkannt werden können.
Evolution ist das Spiel von Malware. Vor einigen Jahren verwendeten Angreifer dieselbe Malware mit demselben Hash-Wert – dem Fingerabdruck einer Malware – mehrmals, bevor sie sie dauerhaft parkten. Heutzutage verwenden diese Angreifer einige Malware-Typen, die häufig einzigartige Hash-Werte generieren. Zum Beispiel kann die Ransomware von Cerber eine neue Malware-Variante generieren – mit einem neuen Hash-Wert alle 15 Sekunden. Das bedeutet, dass diese Malware nur einmal verwendet werden, was sie mit alten Techniken extrem schwer zu erkennen macht. Geben Sie maschinelles Lernen ein. Mit der Fähigkeit von maschinellem Lernen, solche Malware-Formulare basierend auf dem Familientyp zu erfassen, ist es zweifellos ein logisches und strategisches Cybersicherheitstool.
Maschinenlernalgorithmen sind in der Lage, genaue Vorhersagen basierend auf früheren Erfahrungen mit bösartigen Programmen und dateibasierten Bedrohungen zu treffen. Durch die Analyse von Millionen verschiedener Arten bekannter Cyberrisiken kann maschinelles Lernen brandneue oder nicht klassifizierte Angriffe identifizieren, die Ähnlichkeiten mit bekannten aufweisen.
Von der Vorhersage neuer Malware basierend auf historischen Daten bis hin zur effektiven Verfolgung von Bedrohungen, um sie zu blockieren, zeigt maschinelles Lernen seine Wirksamkeit bei der Unterstützung von Cybersicherheitslösungen, die die allgemeine Cybersicherheitshaltung stärken.
Und obwohl maschinelles Lernen in letzter Zeit zu einem wichtigen Gesprächspunkt in der Cybersicherheit geworden ist, ist es bereits seit 2005 ein integriertes Tool in den Sicherheitslösungen von Trend Micro – lange bevor die Begeisterung überhaupt begann.
Trend Micro's AI Solution-Lösungen
Der KI-Hub von Trend bringt innovative Technologie und erstklassige Sicherheit zusammen. Informieren Sie sich, wie KI Sicherheitsteams in die Lage versetzt, Bedrohungen zügig zu prognostizieren, zu antizipieren und zu erkennen. Prüfen Sie regelmäßig, welche aktuellen Ressourcen zum transformativen Einfluss von KI auf die Cybersicherheit es gibt. Sie helfen Ihnen dabei, neuen Bedrohungen einen Schritt voraus zu bleiben und KI-Lösungen sicher zu implementieren.