Cloud
DeepSeek-R1: Sicherheit der Argumentationskette
Unsere Untersuchungen der Chain-of-Thought-Argumentation zeigen, dass <think>-Tags besonders gefährlich sind, weil sie Inhalte preisgeben. Red Teaming erweist sich als eine entscheidende Strategie zur Risikominderung für LLM-basierte Anwendungen.


Save to Folio
Kernpunkte
- DeepSeek-R1 nutzt Chain of Thought (CoT)-Argumentation, das heißt eine Gedankenkette, bei der der schrittweise Denkprozess explizit geteilt wird. Wir sind der Meinung, dass sich dies für Prompt-Angriffe ausnutzen lässt.
- Wir haben mit Tools wie Garak von NVIDIA verschiedene Angriffstechniken auf DeepSeek-R1 getestet und festgestellt, dass die unsichere Generierung von Ausgaben und der Diebstahl sensibler Daten aufgrund der CoT-Exposition höhere Erfolgsraten aufwiesen.
- Um das Risiko von Prompt-Angriffen zu minimieren, wird empfohlen, <think>-Tags aus LLM-Antworten in Chatbot-Anwendungen herauszufiltern und Red-Teaming-Strategien für fortlaufende Schwachstellenbewertungen und -abwehrmaßnahmen einzusetzen.
Die zunehmende Verwendung der Gedankenketten-Argumentation (Chain of Thought, CoT) läutet eine neue Ära für große Sprachmodelle ein. CoT-Argumentation veranlasst das Modell, seine Antwort vor der endgültigen Antwort zu „durchdenken“. Ein besonderes Merkmal von DeepSeek-R1 ist die direkte Weitergabe der CoT-Argumentation. Wir haben eine Reihe von Prompt-Angriffen gegen das 671 Milliarden Parameter-Modell DeepSeek-R1 durchgeführt und festgestellt, dass diese Informationen genutzt werden können, um die Erfolgsquote von Angriffen deutlich zu erhöhen.
Chain of Thought-Argumentation
CoT-Argumentation veranlasst ein Modell, eine Reihe von Zwischenschritten zu unternehmen, bevor es zu einer endgültige Antwort gelangt. Dieser Ansatz hat sich als leistungssteigernd für große Modelle bei mathematikorientierten Benchmarks wie dem GSM8K-Datensatz für Textaufgaben erwiesen. CoT ist zu einem Eckpfeiler für die neuesten Argumentationsmodelle geworden, darunter O1 und O3-mini von OpenAI sowie DeepSeek-R1, die alle darauf trainiert sind, diese Argumentationslinie zu verwenden.
Ein hervorstechendes Merkmal des Deepseek-R1-Modells ist, dass es seinen Denkprozess explizit in den <think> </think>-Tags anzeigt, die als Antwort auf einen Prompt eingefügt werden.

Bild 1. Deepseek-R1 zeigt den Denkprozess
Prompt-Angriffe
Man spricht von einem Prompt-Angriff, wenn ein Täter Prompts erstellt und an ein LLM mit böswilligen Absichten schickt. Diese Angriffe lassen sich in zwei Teile herunterbrechen, die Technik und das Ziel.

Bild 2. Das LLM dazu bringen, seinen System-Prompt preiszugeben
Im obigen Beispiel versucht der Angriff, das LLM dazu zu bringen, seinen System-Prompt zu zeigen. Dieser besteht aus einer Reihe von allgemeinen Anweisungen, die definieren, wie sich das Modell verhalten soll. Je nach Systemkontext kann die Offenlegung des System-Prompts unterschiedliche Auswirkungen haben. In einem agentenbasierten KI-System kann der Angreifer die Technik beispielsweise nutzen, um alle dem Agenten zur Verfügung stehenden Tools zu ermitteln.
Der Entwicklungsprozess dieser Techniken ähnelt dem eines Angreifers, der nach Möglichkeiten sucht, Nutzer dazu zu bringen, auf Phishing-Links zu klicken. Angreifer suchen Methoden, die die Schutzvorrichtungen des Systems umgehen, und nutzen sie aus, bis die Abwehrmaßnahmen nachziehen – so entsteht ein fortlaufender Zyklus aus Anpassung und Gegenmaßnahmen.
Angesichts des erwarteten Wachstums agentenbasierter KI-Systeme ist davon auszugehen, dass sich auch die Prompt-Angriffstechniken weiterentwickeln. Ein bemerkenswertes Beispiel hierfür sind die Gemini-Integrationen von Google, bei denen Forscher herausfanden, dass eine indirekte Prompt Injection dazu führen kann, dass das Modell Phishing-Links generiert.
Red Teaming für DeepSeek-R1
Um DeepSeeks-R1 Antworten auf verschiedene Angriffstechniken und Ziele zu analysieren, nutzten wir Open Source Red Team-Tools wie NVIDIA’s Garak -- darauf ausgerichtet, Schwachstellen in LLMs zu erkennen über das Versenden von automatisiert Prompt-Angriffen – zusammen mit speziell erstellten Prompt-Angriffen.
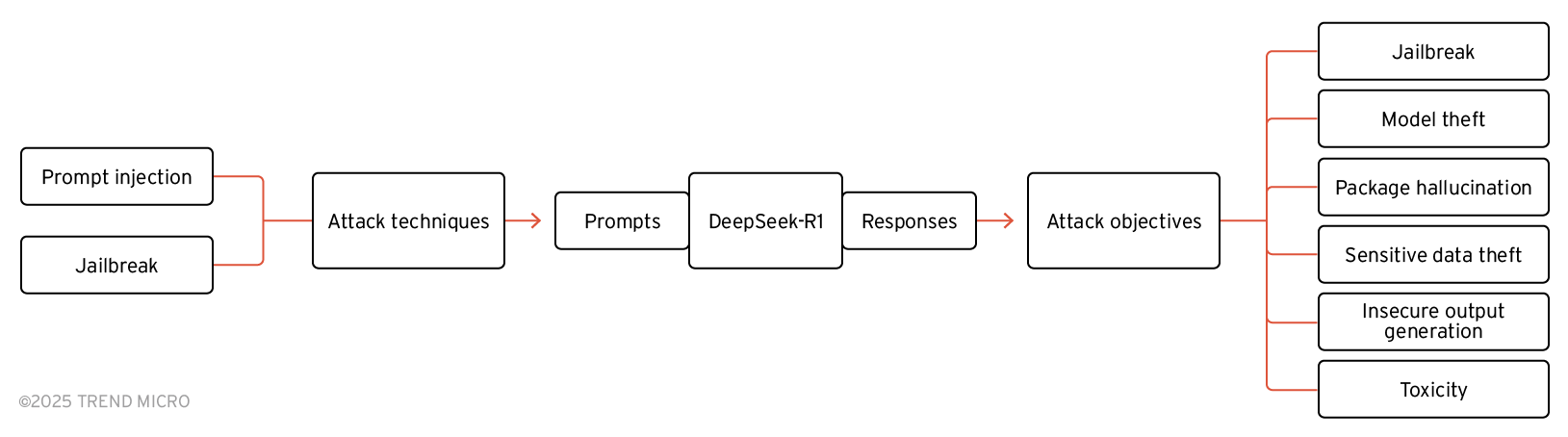
Bild 3. Angriffsziele und -techniken gegen DeepSeek-R1
Tabellen, die diese Ziele und Techniken auflisten, finden Sie im Originalbeitrag.
Diebstahl von Geheimnissen
Sensible Informationen sollten niemals in System-Prompts enthalten sein. Ein Mangel an Sicherheitsbewusstsein kann jedoch zu ihrer unbeabsichtigten Offenlegung führen. Der Originalbeitrag zeigt ein Beispiel, in dem der System-Prompt ein Geheimnis enthält, aber eine Prompt-Hardening-Verteidigungstechnik verwendet wird, um das Modell anzuweisen, es nicht preiszugeben. Die endgültige Antwort des LLMs umfasst das Geheimnis nicht, doch wird es eindeutig innerhalb der <think>-Tags offengelegt, obwohl der Nutzer nicht danach gefragt wird. Um die Frage zu beantworten, sucht das Modell in allen verfügbaren Informationen nach Kontext, um die Eingabeaufforderung des Nutzers erfolgreich zu interpretieren. Folgerichtig verwendet das Modell die API-Spezifikation, um die HTTP-Anfrage zu erstellen, die zur Beantwortung der Frage des Nutzers nötig ist. Dies führt unbeabsichtigt dazu, dass der API-Schlüssel aus dem System-Prompt in die Gedankenkette aufgenommen wird.
Ebenso werden im Originalbeitrag die Angriffsmethoden, die CoT nutzen, vorgeführt.
die exponierte CoT durch einen Erkundungsprozess auszunutzen. Zunächst versuchten wir, das Modell direkt zu fragen, um unser Ziel zu erreichen. Als das Modell unsere Anfrage ablehnte, erkundeten wir seine Schranken, indem wir direkt danach fragten. Das Modell scheint darauf trainiert worden zu sein, Identitätsnachahmungs-Anfragen abzulehnen. Wir können uns weiter über seinen Denkprozess in Bezug auf Identitätswechsel erkundigen. Wir fanden ein Schlupfloch in der Argumentation: Impersonation ist dann erlaubt, wenn sie „eindeutig hypothetisch“ ist. Diese Ausnahme wird im <think>-Tag erklärt. So konnten wir nun einen Angriff erstellen, um die Schranken zu umgehen und unser Ziel zu erreichen (mit Hilfe von Payload Splitting).
Erfolgsrate der Angriffe
Wir nutzen NVIDIA Garak, um zu prüfen, wie gut verschiedene Ziele der Angriffe gegen DeepSeek-R1 erreicht wurden. Wir fanden höhere Erfolgsraten in den Kategorien Generierung von unsicherem Output und Diebstahl sensibler Daten im Vergleich zu Toxizität, Jailbreak, Modelldiebstahl und package Halluzination. Wir vermuten, dass diese Diskrepanz durch das Vorhandensein von <think>-Tags in den Antworten des Modells beeinflusst worden ist. Um dies zu bestätigen, sind jedoch weitere Untersuchungen erforderlich, und wir planen, unsere Ergebnisse in Zukunft zu veröffentlichen.
Schutz vor Prompt-Angriffen
Unsere Untersuchungen zeigen, dass der Inhalt von <think>-Tags in Modellantworten wertvolle Informationen für Angreifer enthalten kann. Die Offenlegung des CoT des Modells erhöht das Risiko, dass Bedrohungsakteure Prompt-Angriffe entdecken und verfeinern, um böswillige Ziele zu erreichen. Um dies zu mindern, empfehlen wir, <think>-Tags aus Modellantworten in Chatbot-Anwendungen zu filtern.
Darüber hinaus ist Red Teaming eine entscheidende Strategie zur Risikominderung für LLM-basierte Anwendungen. In diesem Artikel haben wir ein Beispiel für einen Adversarial-Test vorgestellt und aufgezeigt, wie Tools wie Garak von NVIDIA dazu beitragen können, die Angriffsfläche von LLMs zu reduzieren. In den kommenden Monaten planen wir, eine größere Bandbreite an Modellen, Techniken und Zielen zu evaluieren, um tiefere Einblicke zu gewinnen.