Cyberbedrohungen
RAG-Komponenten: Eine exponierte Grundlage
Retrieval Augmented Generation erlaubt es Unternehmen, effiziente und kostengünstige Anwendungen auf der Basis privater Daten zu erstellen. Doch wie immer gibt es für die Komponenten von RAG auch Sicherheitsrisiken, die zu beachten sind.


Save to Folio
Kernaussagen
- Retrieval Augmented Generation (RAG) ermöglicht es Unternehmen, maßgeschneiderte, effiziente und kostengünstige Anwendungen auf der Grundlage privater Daten zu erstellen. Untersuchungen zeigen jedoch erhebliche Sicherheitsrisiken auf, wie z. B. ungeschützte Vektorspeicher und LLM-Hosting-Plattformen, die zu Datenlecks, unbefugtem Zugriff und potenzieller Systemmanipulation führen können, wenn sie nicht ordnungsgemäß gesichert sind.
- Sicherheitsprobleme wie Fehler bei der Datenvalidierung und Denial-of-Service-Angriffe sind bei allen RAG-Komponenten weit verbreitet. Dies wird durch ihren schnellen Entwicklungszyklus noch verstärkt und erschwert die Verfolgung und Behebung von Schwachstellen.
- Unsere Forschung identifizierte 80 exponierte llama.cpp-Server, von denen 57 keine Authentifizierung forderten. Die exponierten Server konzentrierten sich auf die Vereinigten Staaten, gefolgt von China, Deutschland und Frankreich.
- Über die Authentifizierung hinaus müssen Unternehmen TLS-Verschlüsselung implementieren und Zero-Trust-Netzwerke aufsetzen, um sicherzustellen, dass generative KI-Systeme und ihre Komponenten vor unbefugtem Zugriff und Manipulation geschützt sind.
Seit der Einführung von ChatGPT 2022 scheint jeder auf den KI-Zug aufspringen zu wollen. In einigen Bereichen gaben die Nutzer sich bisher damit zufrieden, einfach die Angebote von OpenAI zu nutzen. Aber viele Unternehmen haben spezielle Anforderungen. Nick Turley, Produktleiter von OpenAI, bezeichnete LLMs kürzlich als „Taschenrechner für Wörter“, der viele Möglichkeiten eröffnet. Allerdings ist etwas Entwicklungsarbeit erforderlich, um diesen „Wortrechner“ effizient zu nutzen, und während wir auf geeignete agentenbasierte KI-Systeme warten, ist die derzeitige Technologie der Wahl die RAG (Retrieval Augmented Generation).
RAG benötigt einige Zutaten, um zu funktionieren: Eine Datenbank mit Textbausteinen und eine Möglichkeit, diese abzurufen sind erforderlich. Üblicherweise wird dafür ein Vektorspeicher eingesetzt, der den Text und eine Reihe von Zahlen speichert, die dabei helfen, die relevantesten Textbausteine zu finden. Mit diesen und einem entsprechenden Prompt lassen sich Fragen beantworten oder neue Texte verfassen, die auf privaten Datenquellen basieren und für die jeweiligen Bedürfnisse relevant sind. Tatsächlich ist RAG so effektiv, dass meist nicht die leistungsstärksten LLM benötigt werden. Um Kosten zu sparen und die Reaktionszeit zu verbessern, lassen sich die vorhandenen eigenen Server verwenden, um diese kleineren und leichteren LLM-Modelle zu hosten.
Den Vektorspeicher gleicht einem sehr hilfreichen Bibliothekar, der nicht nur relevanten Bücher findet, sondern auch die entsprechenden Passagen hervorhebt. Das LLM ist dann der Forscher, der diese Textstellen nimmt und sie dafür nutzt, um ein Whitepaper zu schreiben oder die Frage zu beantworten. Zusammen bilden sie eine RAG-Anwendung.
Vektorspeicher, LLM-Hosting, Schwachstellen
Vektorspeicher sind nicht ganz neu, erleben aber seit zwei Jahren eine Renaissance. Es gibt viele gehostete Lösungen wie Pinecone, aber auch selbst gehostete Lösungen wie ChromaDB oder Weaviate (https://weaviate.io). Sie unterstützen einen Entwickler dabei, Textbausteine zu finden, die dem eingegebenen Text ähneln, wie z. B. eine Frage, die beantwortet werden muss.
Das Hosten eines eigenen LLM erfordert zwar eine nicht unerhebliche Menge an Arbeitsspeicher und eine gute GPU, aber das ist nichts, was ein Cloud-Anbieter nicht bereitstellen könnte. Für diejenigen, die einen guten Laptop oder PC haben, ist LMStudio eine beliebte Option. Für den Einsatz in Unternehmen sind llama.cpp und Ollama oft die erste Wahl. Alle diese Programme haben eine rasante Entwicklung durchgemacht. Daher sollte es nicht überraschen, dass es noch einige Fehler in RAG-Komponenten zu beheben gilt.
Einige dieser Bugs sind typische Datenvalidierungs-Fehler, wie CVE-2024-37032 und CVE-2024-39720. Andere führen zu Denial-of-Service, etwa CVE-2024-39720 und CVE-2024-39721, oder sie leaken das Vorhandensein von Dateien, wie CVE-2024-39719 und CVE-2024-39722. Die Liste lässt sich erweitern.
Weniger bekannt ist llama.cpp, doch dort fand man in diesem Jahr CVE-2024-42479. CVE-2024-34359 betrifft die von llama.cpp genutzte Python-Bibliothek. Vielleicht liegt der Mangel an Informationen über llama.cpp auch an dessen ungewöhnlichem Release-Zyklus. Seit seiner Einführung im März 2023 gab es über 2.500 Releases, also etwa vier pro Tag. Bei einem sich ständig ändernden Ziel wie diesem ist es schwierig, dessen Schwachstellen zu verfolgen.
Im Gegensatz dazu hat Ollama einen gemächlicheren Release-Zyklus von nur 96 Releases seit Juli 2023, also etwa einmal pro Woche. Als Vergleich, Linux hat alle paar Monate ein neues Release und Windows erlebt jedes Quartal neue „Momente“.
ChromaDB gibt es seit Oktober 2022 und fast zweiwöchtentlich erscheint ein neues Release. Interessanterweise sind keine CVEs für diesen Vektorspeicher bekannt. Weaviate, ein weiterer Vektorspeicher, weist ebenfalls Schwachstellen auf (CVE-2023-38976 und CVE-2024-45846 bei Verwendung mit MindsDB). Weaviate existiert seit 2019 und ist damit ein wahrer Großvater dieses Technologie-Stacks, der jedoch immer noch einen wöchentlichen Veröffentlichungszyklus hat. Diese Veröffentlichungszyklen sind nicht in Stein gemeißelt, aber sie bedeuten doch, dass gefundene Bugs schnell gepatcht werden, wodurch die Zeit ihrer Verbreitung begrenzt wird.
LLMs für sich genommen erfüllen wahrscheinlich nicht alle Anforderungen und werden nur schrittweise verbessert, da ihnen die öffentlichen Daten zum Trainieren ausgehen. Die Zukunft gehört wahrscheinlich einer agentenbasierten KI, die LLMs, Speicher, Tools und Workflows in fortschrittlicheren KI-basierten Systemen kombiniert, so Andrew Ng, für seine Arbeiten zur Künstlichen Intelligenz und Robotik bekannter Informatiker. Es geht im Wesentlichen um einen neuen SoftwareeEntwicklungs-Stack, wobei die LLMs und dieVektorspeicher hier weiterhin eine wichtige Rolle spielen werden.
Doch Achtung: Unternehmen können auf dem Weg in diese Richtung Schaden nehmen, wenn sie nicht auf die Sicherheit ihrer Systeme achten.
Exponierte RAG-Komponenten
Wir befürchten, dass viele Entwickler diese Systeme in ihrer Eile dem Internet ungeschützt aussetzen könnten, und suchten deshalb im November 2024 nach öffentlich sichtbarenInstanzen einiger dieser RAG-Komponenten. Im Fokus standen dabei die vier wichtigsten Komponenten, die in RAG-Systemen zum Einsatz kommen: llama.cpp, Ollama, das LLMs hostet, sowie ChromaDB und Weaviate, die als Vektorspeicher dienen.
llama.cpp
llama.cpp wird zum Hosten eines einzelnen LLM-Modells verwendet und ist ein REST-Dienst, d. h. der Server kommuniziert mit dem Client über POST-Anfragen, wie im HTTP-Protokoll definiert. Bei unseren Tests gab es einige Schwankungen bezüglich der Zahlen, doch letztendlich fanden wir 80 exponierte Server, und 57 von ihnen schienen keinerlei Authentifizierung zu haben. Es ist gut möglich, dass diese Zahlen zu niedrig sind und dass mehr Server besser versteckt, aber ebenso offen vorhanden sind. Die Modelle, die auf den Servern von llama.cpp gehostet wurden, waren hauptsächlich von Llama 3 abgeleitete Modelle, gefolgt von Mistral-Modellen. Viele davon sind als Jailbreak-Modelle bekannt. Die meisten nicht so bekannten waren wahrscheinlich auch für bestimmte Zwecke optimiert worden.
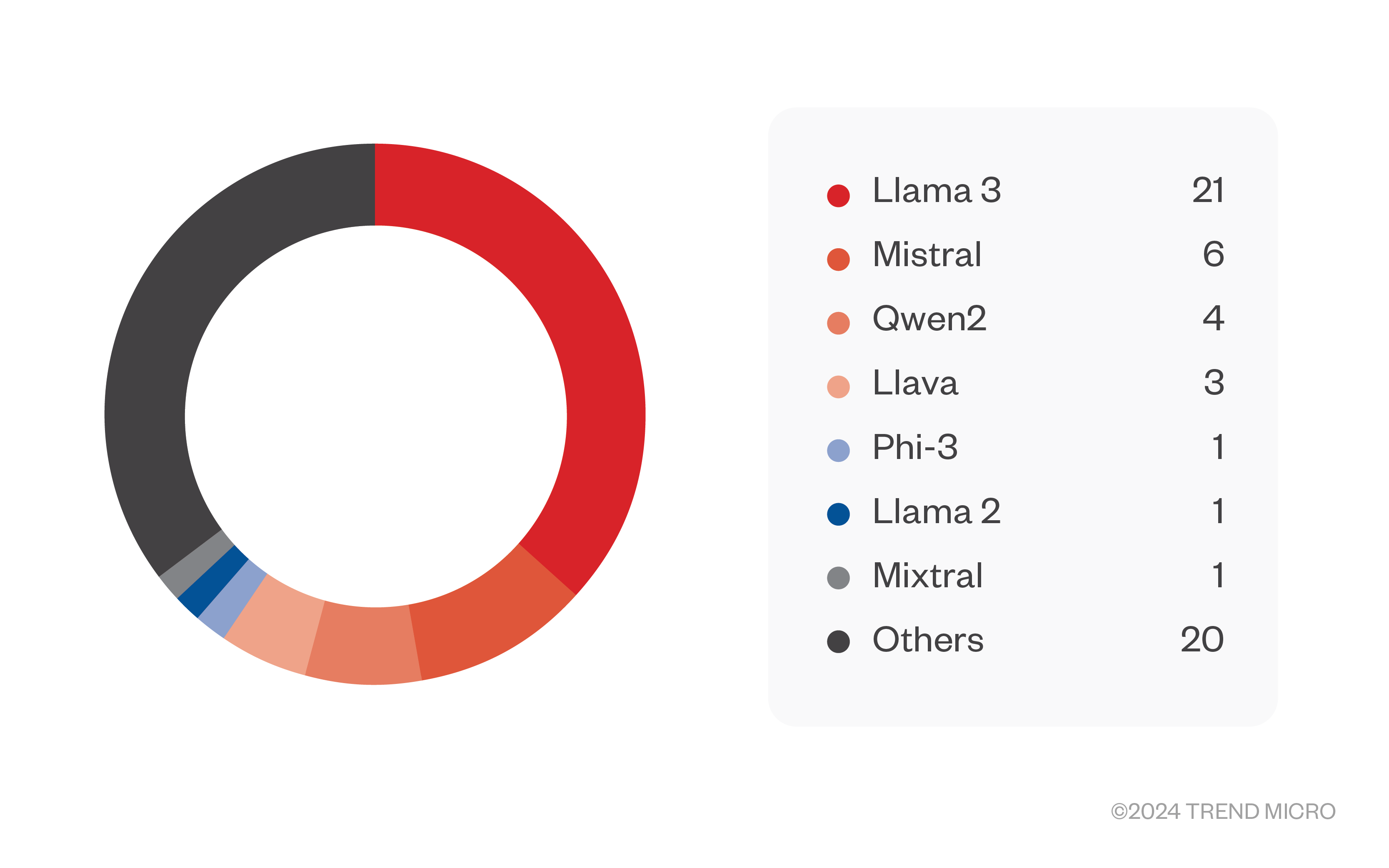
Die Länder, die am häufigsten diese exponierten Systeme hosten, waren die USA (24 Server), gefolgt von China, Deutschland und Frankreich.
Die Schnittstelle zu llama.cpp ist darauf beschränkt, LLM-Vervollständigungen, Einbettungen, Tokenisierung und einige andere Metriken zu erhalten. Abgesehen von dem Missbrauch der Berechnungen, die diese Server für Dritte bereitstellen, besteht die größte Sorge darin, dass es Schwachstellen geben könnte, die nicht dokumentiert sind und von Kriminellen ausgenutzt werden könnten.
Ollama
Im Gegensatz zu lama.cpp kann Ollama dazu genutzt werden, um viele Modelle gleichzeitig zu hosten, die man mit dem REST-Dienst auswählt. Außerdem, und das ist noch beunruhigender, lässt sich über HTTP GET-, POST- und DELETE-Anfragen mit dem Server interagieren. Wir können also nicht nur eine Chat-Antwort von einem gehosteten Modell erhalten, sondern auch alle gehosteten Modelle auflisten, neue Modelle erstellen, Modelle kopieren oder löschen, sowie auf den Server übertragen, herunterladen und Einbettungen erstellen. Dies geht weit über die Möglichkeiten von llama.cpp-Servern hinaus.
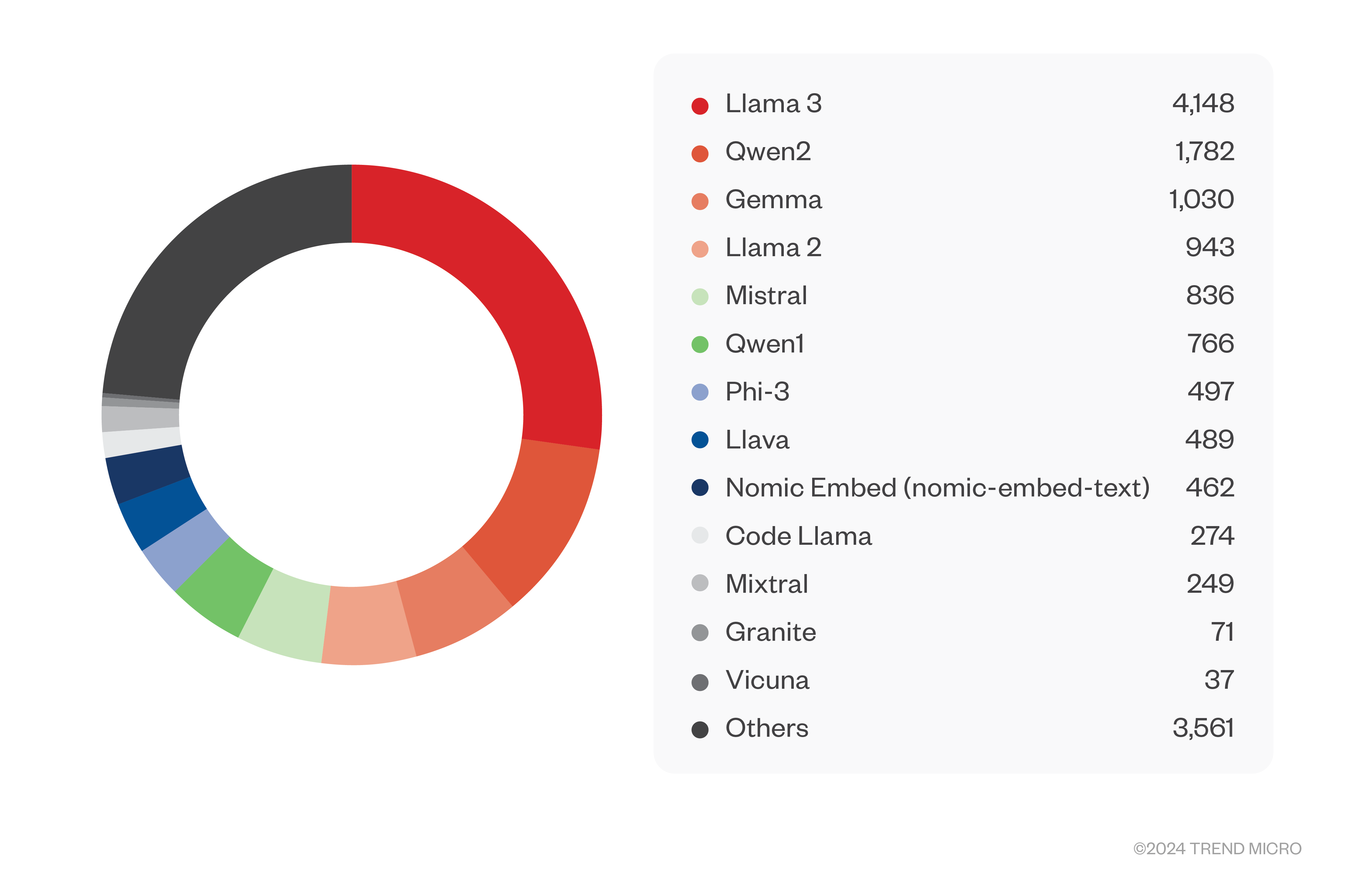
Leider geht mit einer so großen Macht keine Verantwortung einher. Wir fanden über 3.000 Server, die völlig frei zugänglich waren, und nur weitere acht, die eine Authentifizierung verlangten. Wie bereits erwähnt, sind diese Zahlen wahrscheinlich auch eher niedrig, aber dennoch alarmierend. Auf diesen Servern wurden unglaubliche 15.000 Modelle gehostet. Die große Mehrheit davon basierte auf dem beliebten Modell Llama 3 (mit mehr als 4.000 Modellen), gefolgt von Qwen2, Gemma und vielen anderen. Den Namen nach zu urteilen, scheinen die meisten Modelle feinjustierte Modelle zu sein, von denen viele für Jailbreaking bekannt sind.
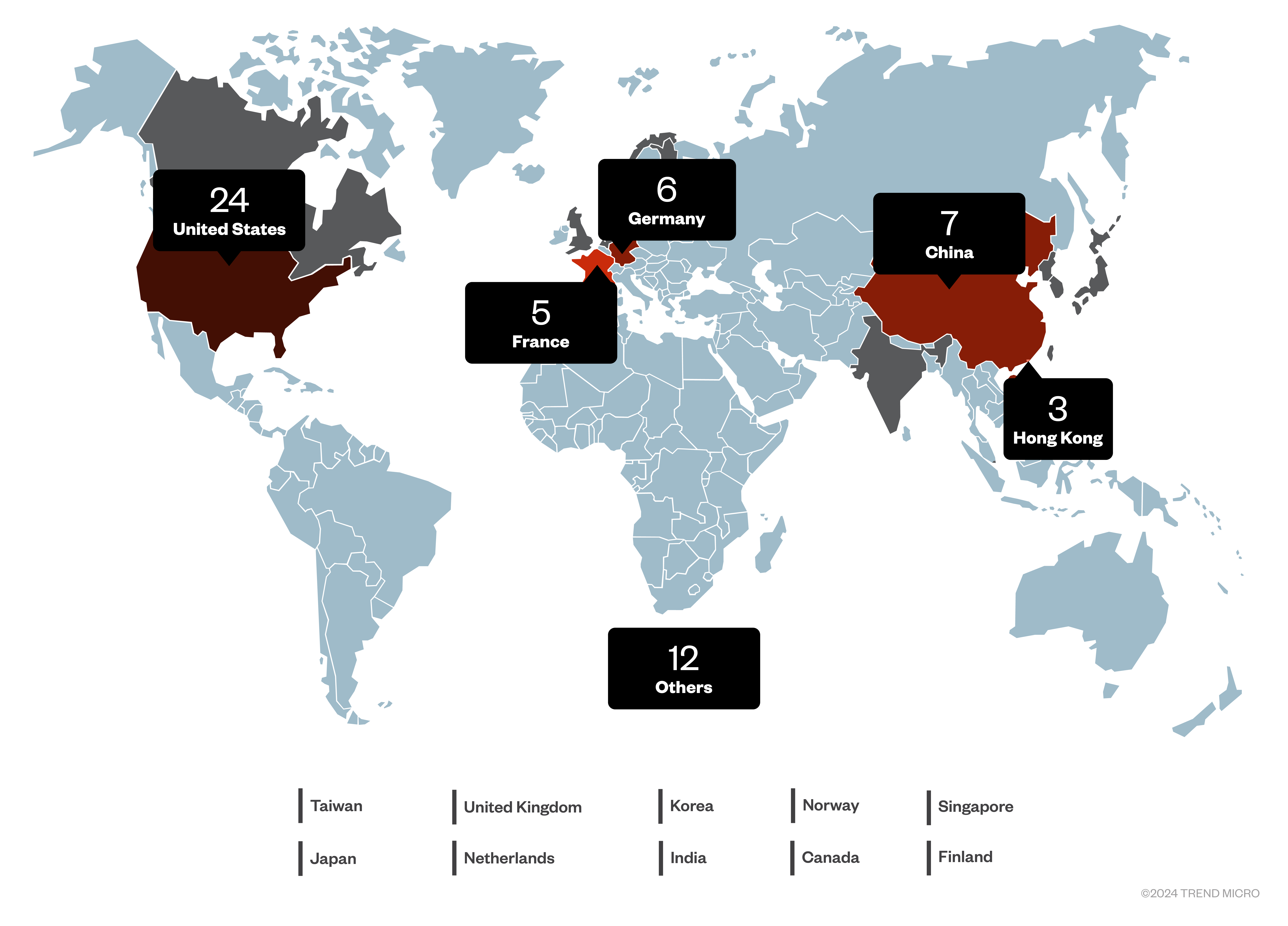
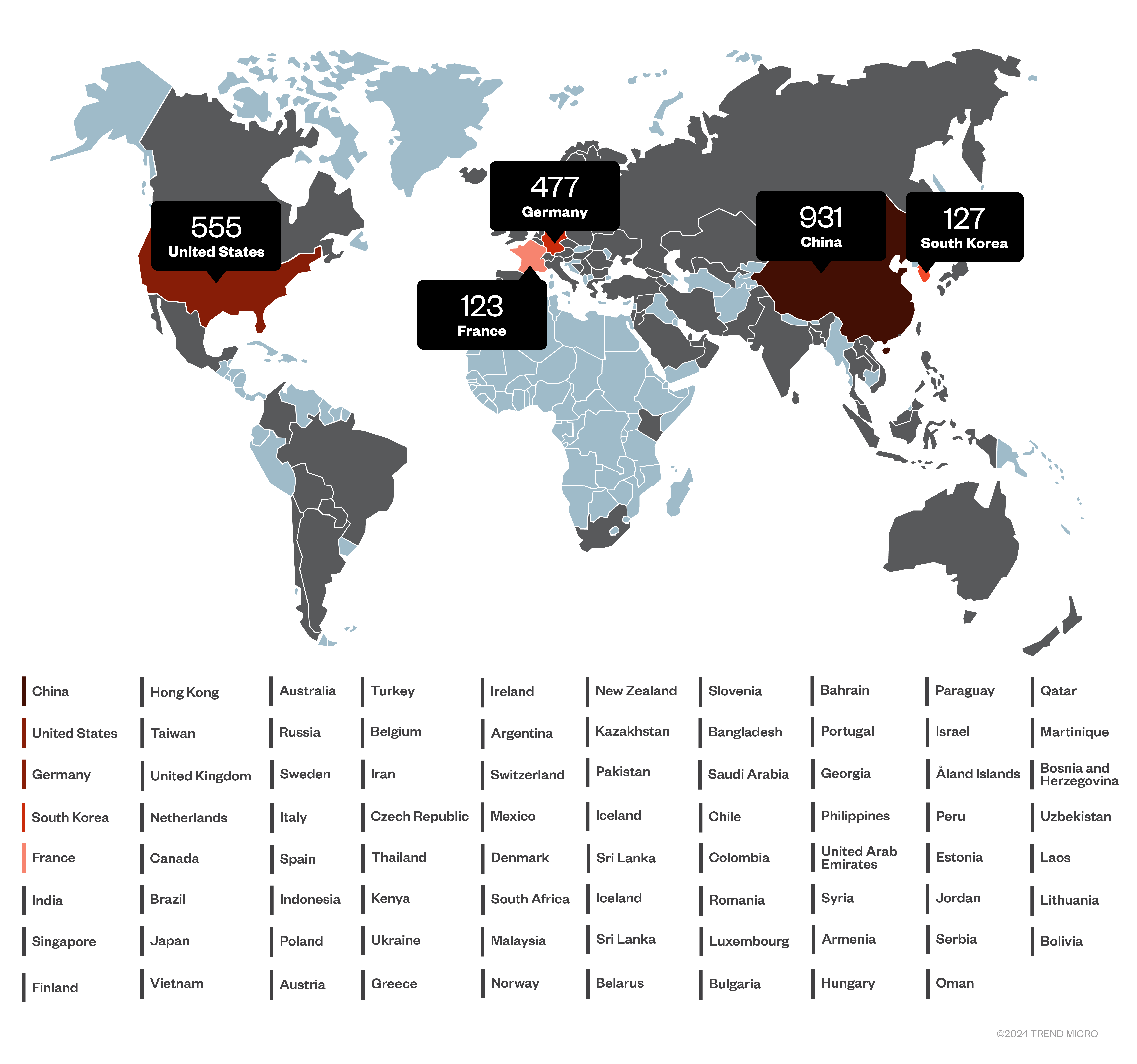
Ollama ermöglichte es auch, den System-Prompt der gehosteten Modelle zu überprüfen. In den meisten Fällen wird der Standard-Systemprompt für das Modell verwendet, aber manchmal verrät der Eigentümer seine Absichten mit einer benutzerdefinierten Eingabeaufforderung.Die Länderverteilung für Ollama unterscheidet sich von der für llama.cpp. In diesem Fall ist China mit weit über 900 Servern am stärksten vertreten, gefolgt von den USA, Deutschland, Südkorea und Frankreich.
Wenn Modelle abgerufen werden können und wir verschiedene Attribute wie die Systemprompts angezeigt bekommen, bedeutet dies auch, dass Modelle ersetzt oder gelöscht werden können mit unvorhersehbaren Ergebnissen, wenn das Modell Teil eines RAG- oder agentenbasierten KI-Systems ist. Wir können diese Szenarien zwar nicht testen, aber durch die Installation von Ollama konnten wir all diese Dinge tun. Dies lässt uns vermuten, dass alle diese exponierten Server gleichermaßen anfällig sind.
ChromaDB
Seitdem die Bedeutung von RAG für den Nutzen von LLMs erkannt worden ist, haben viele Datenbanken ihre Systeme um Vektorspeicherfunktionen erweitert. Es gibt unzählige Varianten von PostgresQL mit zusätzlicher Vektorspeicherfunktionalität. Es gibt jedoch auch einige speziell entwickelte Vektorspeicher, und einer der am häufigsten genannten ist ChromaDB.
ChromaDB basierte ursprünglich auf Clickhouse und DuckDB, aber als diese Abhängigkeiten zu einer Belastung wurden, kam die Datenbank nach einer Überarbeitung 2023 als Open-Source-Software neu heraus. Technisch basiert sie nun auf SQLite3 und übernimmt damit die Vorteile und Einschränkungen. Sie wird häufig in Abhängigkeit zu einer KI-Anwendung eingesetzt, kann aber auch als Server ausgeführt werden.
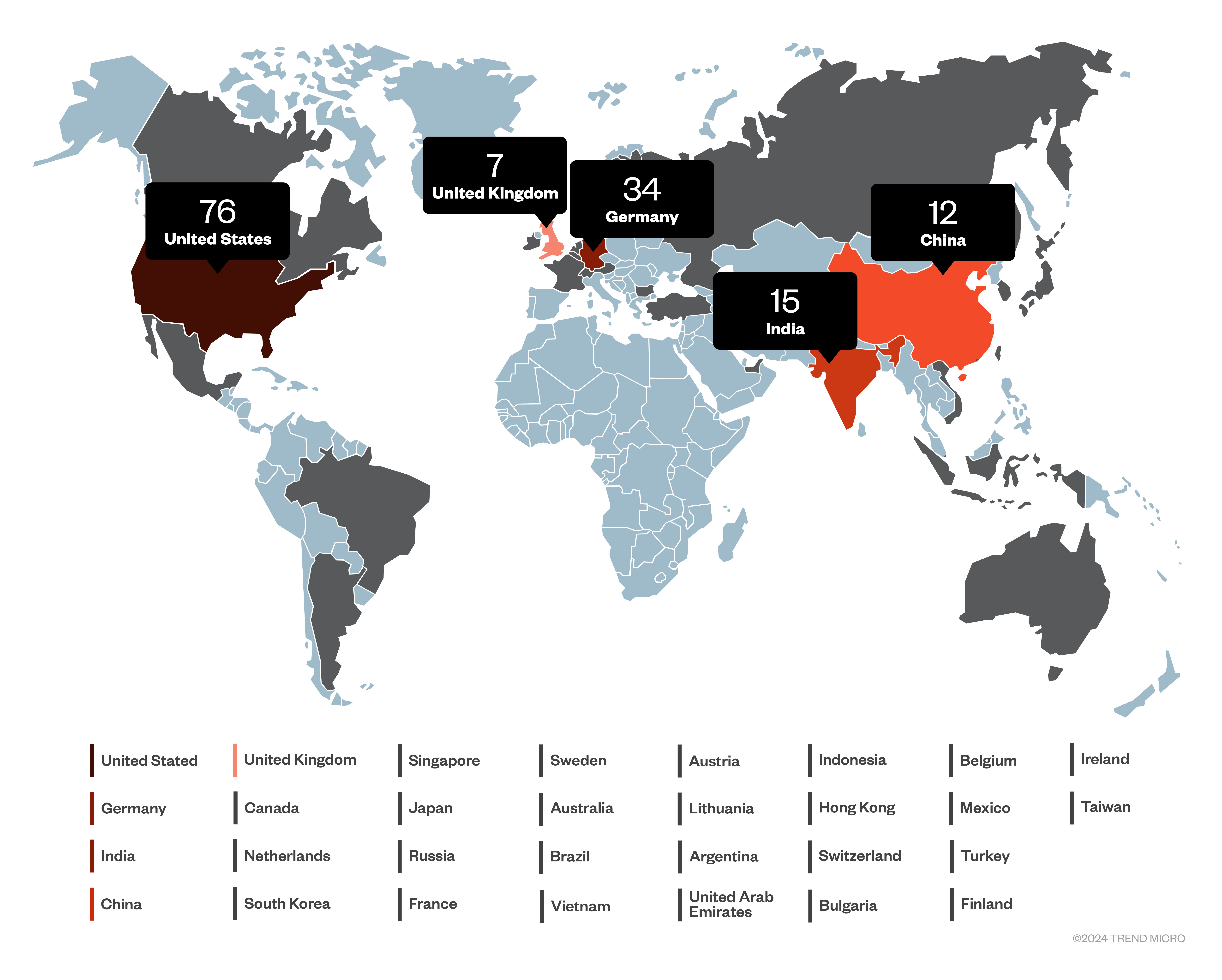
Wir konnten etwa 240 Instanzen von ChromaDB verifizieren, die frei zugänglich im Internet laufen. Die aktuelle Serverversion ist die beliebteste.
Nur etwa 40 der gefundenen Server verlangten eine Authentifizierung. Dieser Mangel hat Konsequenzen, denn man kann alle Dokumentensammlungen auflisten, und, wie wir testen konnten, die auf dem Server gespeicherten Dokumente lesen.
Die Folgen sind schwerwiegend, wenn die Dokumente private Unternehmensinformationen oder personenbezogene Daten (PII) enthalten. Schließlich will man zum Beispiel ein RAG-System verwenden, um einem Agenten bei der Entscheidung für einen Preis bei einem Kunden zu helfen, indem man die internen Preislisten in einem Vektorspeicher speichert.
Die Daten auf diesen Servern sind auch lösch- und beschreibbar. Das Löschen sollte kein großes Problem darstellen. Ein Angreifer könnte jedoch die Ergebnisse eines RAG- oder agentenbasierten KI-Systems manipulieren, indem er die Daten im Vektorspeicher ändert. Schließlich werden die in einem solchen System getroffenen Entscheidungen weitgehend von den Daten im Vektorspeicher und der gestellten Frage bestimmt.
In diesem Fall führen die USA die Länderverteilung an, gefolgt von Deutschland und Indien.
Weaviate
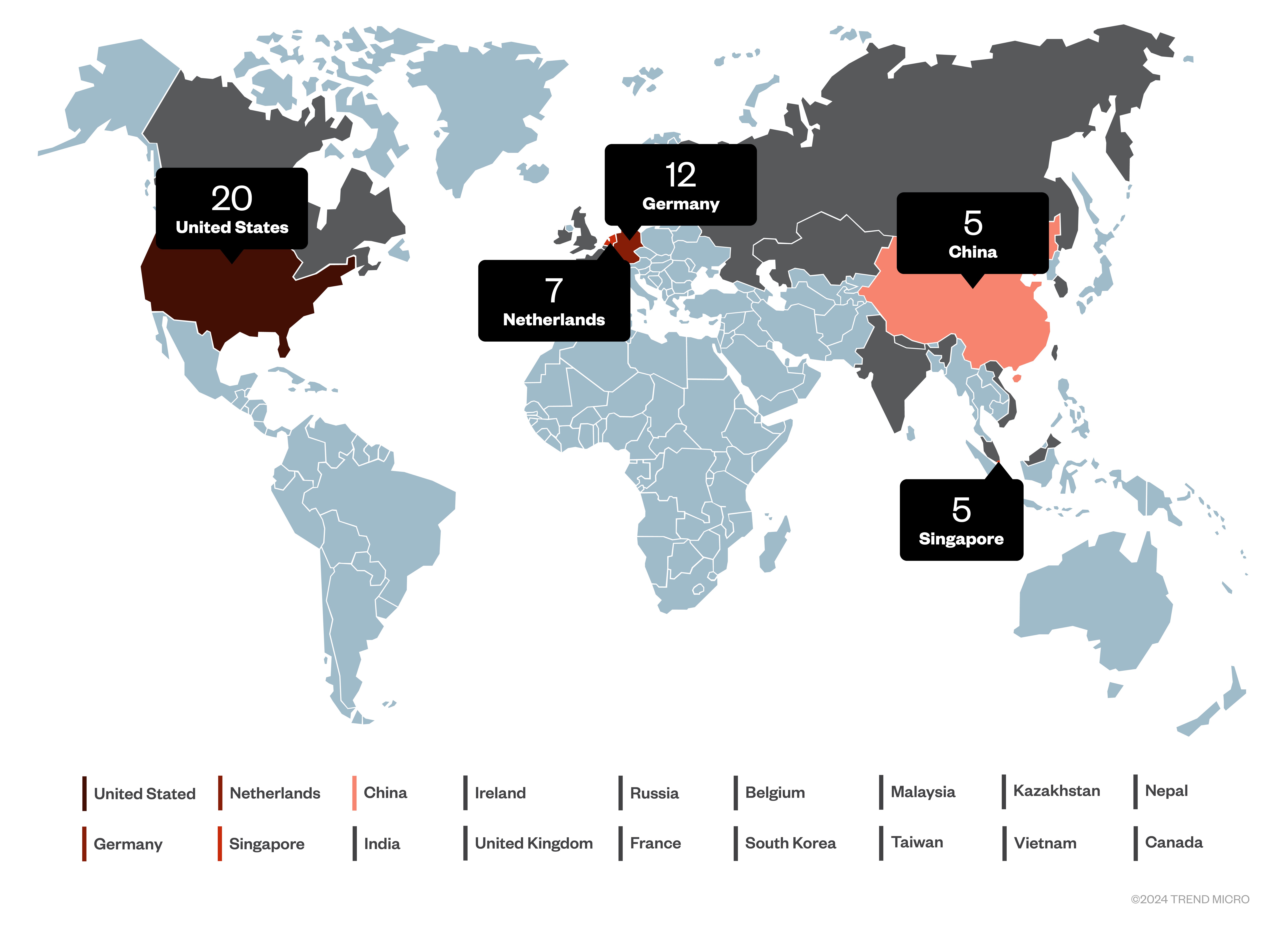
Weaviate ist ein viel älterer Vektorspeicher als ChromaDB. In KI-Jahren wäre er ein Jahrhundert alt. Seine Entwicklung begann 2016, er wurde aber erst 2019 der Welt vorgestellt. Er ist Open Source und kann als Server installiert werden. Trotzdem konnten wir nur wenige Server finden, nämlich etwas über 70 Server, auf die ohne Authentifizierung zugegriffen werden konnte, und etwas mehr als 40, für die eine Authentifizierung erforderlich war. Meistens handelte es sich bei den installierten Versionen um aktuelle.
Die gleichen Probleme mit exponierten und nicht authentifizierten Servern, die wir mit ChromaDB sahen, gelten auch hier. Wir können Dokumente lesen, löschen und schreiben, was zu unerwünschten Offenlegungen, Denial-of-Service-Angriffen oder Manipulationen des laufenden RAG- oder Agentensystems führen kann.
Es muss etwas an RAG-Systemen geben, das die USA und Deutschland zusammenbringt, denn genau wie bei ChromaDB teilen sie sich auch bei Weaviate die Spitzenplätze. Da Weaviate ein niederländisches Unternehmen ist, überrasch es nicht, dass die Niederlande auf dem dritten Platz landen.
Es gibt eine Reihe anderer LLM-Hosting-Plattformen und Vektorspeicher. Ein beliebter LLM-Server für den Desktop ist LMStudio, aber wir konnten im Internet keine überprüfbaren Systeme finden. Einige der anderen Vektorspeicher sind in geringer Anzahl verfügbar, und möglicherweise ist eine größere Anzahl hinter PostgresQL-Installationen verborgen.
Cybersicherheit und GenAI zusammenbringen
Kein System sollte ohne Authentifizierung zugänglich sein. Andere Sicherheitsvorkehrungen wie TLS-Verschlüsselung und ein Zero-Trust-Netzwerkmodell werden dringend empfohlen. Der Schaden, der durch die Exponierung eines LLM entsteht, hängt davon ab, wie proprietär das Fine-Tuning des Modells ist. Das Hosten und Eponieren eines weiteren Llama-3-Modells ist nicht besonders problematisch, abgesehen von den Kosten für die Bereitstellung eines öffentlichen Dienstes. Wenn jedoch ein Modell für eine bestimmte geschäftsrelevante Anwendung optimiert wurde, sollten alle Anstrengungen unternommen werden, um es zu schützen, da es Teil des geistigen Eigentums des Unternehmens ist.
Noch problematischer sind die exponierten Vektorspeicher. Diese leaken Daten, aber schlimmer noch, sie könnten dazu führen, dass ein böswilliger Akteur die Art der Anwendung, die die Daten verwendet, ändert. Generative KI-Systeme (GenAI) sind in einer Weise datengesteuert, die über herkömmliche Anwendungen hinausgeht. In Zukunft, wenn sich agentenbasierte KI-Systeme weiter verbreiten, wird der Schutz der Daten, die diese Systeme antreiben, oberste Priorität haben.
In dem Bestreben, schnell voranzukommen und auf den GenAI-Zug aufzuspringen, darf die Sicherheit nicht auf der Strecke bleiben. Es ist wichtig, bei der Bereitstellung jedes Systems, sei es in der Cloud oder vor Ort, stets die grundlegenden Sicherheitsprinzipien zu berücksichtigen. Ein leistungsstarkes Tool ist das Zero-Trust-Networking, bei dem nur zuvor genehmigte Verbindungen zugelassen werden. Die Cloud-Infrastruktur macht dies relativ einfach, indem sie die Konfiguration dieser Verbindungen in einer Infrastruktur-als-Code-Manier ermöglicht.
Unternehmen können KI für ihre Geschäfts- und Sicherheitsabläufe nutzen und sich gleichzeitig gegen ihre missbräuchliche Nutzung schützen. Es gibt Lösungen wie Trend Vision One™ – Zero Trust Secure Access (ZTSA), bei denen die Zugriffskontrolle beim Zugriff auf private und öffentliche GenAI-Dienste (z. B. ChatGPT und Open AI) mit Zero-Trust-Prinzipien durchgesetzt werden kann.
Durch die proaktive Umsetzung dieser Maßnahmen haben Unternehmen die Möglichkeit, mit GenAI innovativ zu sein und gleichzeitig ihr geistiges Eigentum, ihre Daten und ihre Betriebsabläufe zu schützen