Künstliche Intelligenz (KI)
Rogue AI: Was der Sicherheitsgemeinschaft fehlt
Bekannte Organisationen wie OWASP, MITRE und MIT beschäftigen sich alle mit dem Risiko durch AI und haben bereits Frameworks dazu veröffentlicht. Wir stellen die unterschiedlichen Sichtweisen, aber auch fehlenden Aspekte vor.


Save to Folio
Rogue AI stellt eine längerfristige Bedrohung dar, denn solche Systeme handeln gegen die Interessen ihrer Schöpfer. Hier kann der ganzheitliche Ansatz von Zero-Trust helfen, der jede von AI-Modellen verwendete Daten- und Computerebene schützt. Die Community arbeitet laufend an Möglichkeiten zur Bewertung des KI-Risikos. Auch wenn hier großartige Arbeit geleistet wird, fehlt aber bisher die Idee, Kausalität (Absicht oder nicht) mit dem Kontext von Angriffen zu verknüpfen.
Verschiedene Organisationen der Sicherheits-Community haben unterschiedliche Blickweisen auf Rogue AI:
- OWASP konzentriert sich auf Schwachstellen und deren Behebung mit seinem Top 10 for LLM Applications-Report und einer allgemeinen Anleitung in seiner LLM AI Cybersecurity and Governance Checklist
- MITRE befasst sich mit Angriffstaktiken und -techniken über eine ATLAS-Matrix, die MITRE ATT&CK auf KI-Systeme erweitert
- Ein neues AI Risk Repository vom MIT bietet eine Online-Datenbank mit über 700 AI-Risiken, die nach Ursache und Risikobereich kategorisiert sind
OWASP
Rogue AI hat Bezug zu allen Top 10-Risiken großer, von OWASP genannter Sprachmodelle (LLM), mit Ausnahme von LLM10 (d.h. an 10. Stelle genanntes Risiko): Dort geht es um Modelldiebstahl, und das bedeutet „unbefugten Zugriff, Kopieren oder Exfiltrierung von proprietären LLM-Modellen“.
Es gibt auch keine Schwachstelle im Zusammenhang mit „Misalignment“, d. h. wenn eine KI kompromittiert wurde oder sich auf nicht vorhergesehene Weise verhält.
Fehlausrichtung (Misalignment) kann:
- durch Prompt Injection, Modellmanipulation, Lieferkette, unsichere Ausgabe oder unsichere Plugins verursacht werden.
- in einem Szenario von LLM09 (übermäßiges Vertrauen) größere Auswirkungen haben
- zu Denial of Service (LLM04), Offenlegung sensibler Informationen (LLM06) und/oder übermäßiger Agency (LLM08) führen
So genannte „exzessive Agency“ (LLM08) ist besonders gefährlich. Der Ausdruck benennt Situationen, in denen LLMs „Handlungen ausführen, die ungewollte Folgen haben,“ und ist auf übermäßige Funktionalität, Berechtigungen oder Autonomie zurückzuführen. Die Gefahr könnte durch die Gewährleistung eines angemessenen Zugriffs auf Systeme, Fähigkeiten und die Nutzung von Human-in-the-Loop gemildert werden.
OWASP schlägt in den Top 10 zwar vor, wie man das Risiko durch Rogue AI eindämmen kann, geht aber nicht auf die Kausalität ein, d. h. ob ein Angriff beabsichtigt ist oder nicht. Das Governance-Dokument bietet außerdem eine praktische und umsetzbare Checkliste zur Absicherung der LLM-Einführung in verschiedenen Risikodimensionen. Es hebt Schatten-KI als die „dringlichste, nicht feindliche LLM-Bedrohung“ für viele Organisationen hervor. Betrügerische Systeme gedeihen im Verborgenen, und nicht vorhandene KI-Governance bedeutet bereits, dass KI außerhalb der Richtlinien eingesetzt wird. Der Mangel an Transparenz bei Schatten-KI-Systemen verhindert Einblicke in ihre Ausrichtung.
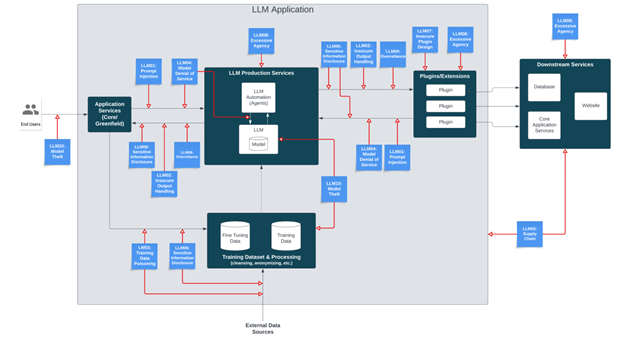
MITRE ATLAS
Die Taktiken, Techniken und Verfahren (TTPs) von MITRE sind eine unverzichtbare Ressource für alle, die sich mit der Aufklärung von Cyberbedrohungen befassen. Sie helfen dabei, die Analyse der vielen Schritte in der Kill Chain zu standardisieren und ermöglichen es, bestimmte Kampagnen zu identifizieren. Obwohl ATLAS das ATT&CK-Framework auf KI-Systeme erweitert, befasst es sich nicht direkt mit Rogue AI. Allerdings können Prompt Injection, Jailbreak und Model Poisoning, die alle zu den ATLAS-TTPs gehören, auch dazu verwendet werden, KI-Systeme zu unterwandern und so Rogue AI zu erzeugen.
Diese manipulierten Rogue-AI-Systeme selbst sind auch TTPs: Agentenbasierte Systeme können jede der ATT&CK-Taktiken und -Techniken (z. B. Erkundung, Ressourcenentwicklung, Erstzugriff, Zugriff auf ML-Modelle, Ausführung) für jede Einwirkung ausführen. Glücklicherweise sind derzeit nur raffinierte Akteure in der Lage, KI-Systeme für ihre spezifischen Ziele zu manipulieren, aber die Tatsache, dass sie bereits nach Zugriffsmöglichkeiten auf solche Systeme suchen, sollte Anlass zur Sorge geben.
Obwohl sich MITRE ATLAS und ATT&CK mit manipulierten Betrugs-KI-Systemen befassen, beschäftigen sie sich noch nicht mit böswilligen Rogue KIs. Bisher gibt es kein Beispiel dafür, dass Angreifer bösartige KI-Systeme in Zielumgebungen installieren, obwohl dies sicherlich nur eine Frage der Zeit ist: Wenn Organisationen beginnen, KI-Agenten einzusetzen, werden dies auch Bedrohungsakteure tun. Auch hier ist der Einsatz einer KI auf diese Weise für einen Angriff eine eigene Technik. Der Einsatz aus der Ferne ist wie KI-Malware, und mehr noch – genauso wie die Verwendung von Proxys mit KI-Diensten für Angreifer wie ein KI-Botnet ist, ist es aber auch ein bisschen mehr.
MIT AI Risk Repository
Schließlich gibt es noch das Risk Repository vom MIT, eine Online-Datenbank mit Hunderten von KI-Risiken sowie eine Themenkarte mit der neuesten Literatur zu diesem Thema. Als erweiterbarer Speicher für die Sichtweisen der Community auf KI-Risiken ist es ein wertvolles Artefakt. Die gesammelten Risiken ermöglichen eine umfassendere Analyse. Wichtig ist, dass es das Thema Kausalität einführt und sich dabei auf drei Hauptdimensionen bezieht:
- Wer hat das Risiko verursacht (Mensch/KI/unbekannt)
- Wie es bei der Bereitstellung des KI-Systems verursacht wurde (versehentlich oder absichtlich)
- Wann es verursacht wurde (vorher, nachher, unbekannt)
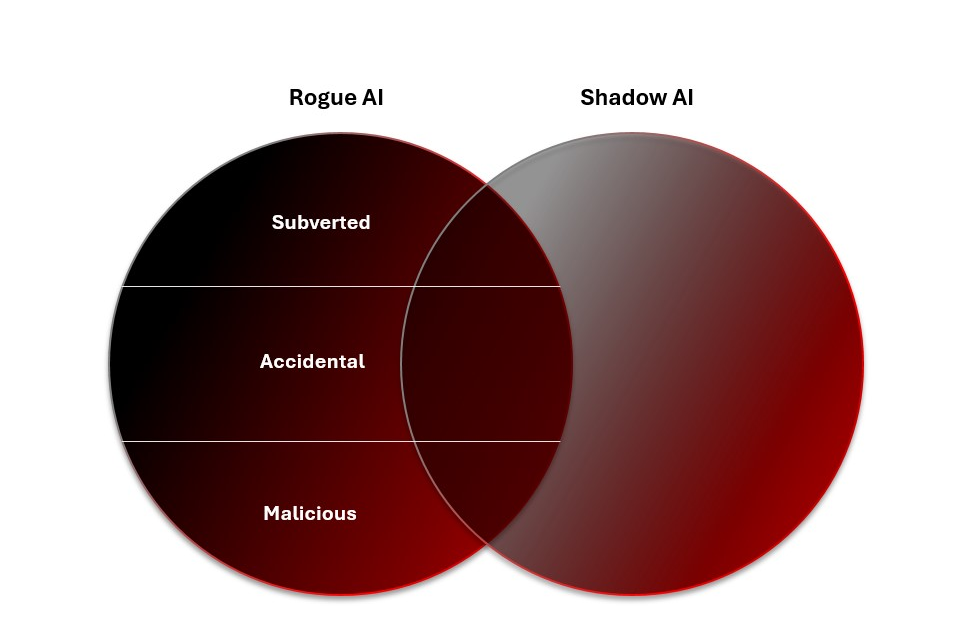
Die Absicht zu berücksichtigen ist besonders nützlich, um Rogue AI zu verstehen, obwohl sie nur an anderer Stelle in der OWASP-Sicherheits- und Governance-Checkliste behandelt wird. Das versehentliche Risiko ist oft eher auf eine Schwachstelle als auf eine MITRE ATLAS-Angriffstechnik oder eine OWASP-Schwachstelle zurückzuführen.
Es kann auch hilfreich sein zu analysieren, von wem das Risiko ausgeht, um Rogue-KI-Bedrohungen zu analysieren. Sowohl Menschen als auch KI-Systeme können versehentlich Rogue-KI verursachen, während böswillige Rogues von vornherein für Angriffe ausgelegt sind. Böswillige Rogues könnten theoretisch auch versuchen, bestehende KI-Systeme zu unterwandern, um zu Rogue-KI zu werden, oder darauf ausgelegt sein, „Nachwuchs“ zu produzieren – obwohl wir derzeit davon ausgehen, dass Menschen die Hauptursache für Rogue-KI sind.
Für jeden Bedrohungsforscher sollte es ein Muss sein zu verstehen, wann das Risiko verursacht wird. Er muss zu jedem Zeitpunkt des Lebenszyklus des KI-Systems über Situations-Awareness verfügen. Das bedeutet, dass Systeme vor und nach der Bereitstellung evaluiert und Abgleichprüfungen durchgeführt werden, um böswillige, unterwanderte oder versehentliche Rogue-KI zu erkennen.
Das MIT unterteilt Risiken in sieben Hauptgruppen und 23 Untergruppen, wobei Rogue-KI direkt im Bereich „Sicherheit, Ausfälle und Einschränkungen von KI-Systemen“ behandelt wird. Es definiert sie wie folgt:
„KI-Systeme, die im Widerspruch zu ethischen Standards oder menschlichen Zielen oder Werten stehen, insbesondere zu den Zielen von Entwicklern oder Anwendern. Diese fehlgeleiteten Verhaltensweisen können von Menschen während des Entwurfs und der Entwicklung eingeführt werden, z. B. durch Belohnungs-Hacking und Fehlverallgemeinerung von Zielen, und können dazu führen, dass KI gefährliche Fähigkeiten wie Manipulation, Täuschung oder Situations-Awareness einsetzt, um Macht zu erlangen, sich selbst zu vermehren oder andere Ziele zu erreichen.“
Tiefgreifende Verteidigung durch Kausalität und Risikokontext
Unterm Strich vergrößert die Einführung von KI-Systemen die Angriffsfläche von Unternehmen möglicherweise erheblich. Risikomodelle sollten aktualisiert werden, um die Bedrohung durch Rogue AI zu berücksichtigen.
Das Thema Absicht ist hier entscheidend: Es gibt viele Möglichkeiten, wie versehentliche Rogue AI Schaden anrichten kann, ohne dass ein Angreifer anwesend ist. Und wenn der Schaden beabsichtigt ist, ist es wichtig zu verstehen, wer wen mit welchen Ressourcen angreift. Zielen Bedrohungsakteure oder böswillige Rogue AI auf Ihre KI-Systeme ab, um unterwanderte Rogue AI zu schaffen? Zielen sie auf Ihr Unternehmen im Allgemeinen ab? Und nutzen sie Ihre Ressourcen, ihre eigenen oder die eines Stellvertreters, dessen KI unterwandert wurde?
All dies sind Unternehmensrisiken, sowohl vor als auch nach der Bereitstellung. Und obwohl in der Security Community gute Arbeit geleistet wird, um diese Bedrohungen besser zu profilieren, fehlt bei Rogue AI ein Ansatz, der sowohl die Kausalität als auch den Angriffskontext einbezieht. Indem wir diese Lücke schließen, können wir beginnen, das Rogue-AI-Risiko umfassend zu planen und zu mindern.