甚麼是機器學習?
這是人工智能的一種,系統會利用多種演算法從重複的數據中學習,並利用可產生精確模型的訓練用數據來預測結果。
機器學習介紹
一直以來人類都有幻想,希望電腦可以在無須得到明確指示情況下就能自行決定採取甚麼行動。
其中一個夢想就是自動駕駛車輛,人們期望它懂得辨認行人及路上的坑洞,會因應環境快速及有效率地作出反應,並最終將您安全送達目的地。這亦是機器學習的實用例子。
它如何運作? 讓我們先從分析商業數據開始。
機器學習是人工智能的一種,讓機構可以從大量數據中理解形勢及學習經驗。以 Twitter 為例,根據 Internet Live Stats,Twitter 用戶每日發出約5 億條 Tweets,即是每年發文會達到約 2000 億條。人力是無法對這麼大量的推文進行分析、分類、整理、學習及作預測。
機構需要進行大量工作來從機器學習中取得寶貴資訊。而要取得最大成效,您必須擁有無雜質的數據及清楚需要解答的問題,然後您可以選擇對機構最合適的模型及演算法。機器學習並不是一個簡單或容易的過程,要達致成功須經歷認真而刻苦的工序。
機器學習的週期為:
- 了解—— 為何要採用機器學習,與及希望用來做甚麼及學習甚麼。
- 數據採集及清理—— 您要擁有所需的鉅量數據,它們應盡量不含雜質才可以提供需要的啟示。
- 功能選擇—— 包括決定將甚麼數據傳送至機器學習以建立模型。視乎所用的演算法而定,您可以採用不同方式來協助選擇功能。例如,假如您採用決策樹演算法(decision tree algorithm),分析師或建模工具就可應用一個「興趣度分數」來決定數據庫內某一欄目的數據是否可用於建立模型。
- 選擇模型—— 選擇已被訓練作處理的檔案(模型)及在數據中尋找某些物件。模型會和演算法相配合,而測試數據會將兩者結合來作出結論。
- 培訓及調校—— 這個結論也可以確保您取得所需的答案。
- 評估模型及演算法以決定它是否可用,或是重複之前的步驟來重新訂定模型、功能、演算法或數據,以達致目標。
- 將經過訓練的模型部署至作業。
- 在作業過程中審視現有模型的成品。
機器學習用來做甚麼? 機器學習應用程式
機器學習讓機構了解其數據及從數據中學習。商業機構可以在很多不同範疇應用此技術,包括改善營銷、提供搜尋功能、整合語音指令至產品或是建造自動駕駛汽車等。
機器學習分支領域
在今天的商業社會,機器學習已經被應用於不同領域,而這些應用也會隨時間而增加及改善。機器學習的分支領域包括社交媒體及產品建議、影像辨識、健康診斷、語言翻譯、話音識別及數據發掘等。
社交媒體平台如 Facebook、Instagram 或 LinkedIn 都在利用人工智能,根據您讚好的貼文來建議追蹤某些專頁或群組。它會參考歷史數據,看其他人讚好的貼文,或是根據與您讚好貼文相類似的貼文來作出建議,或將之推送給您。
同樣地,電子商貿平台也會應用機器學習來分析用戶的購買及搜尋紀錄,與及其他用戶的類似行為來為您作產品建議。
今時今日,機器學習的另一個主要用途是影像辨識。社交媒體平台已利用機器學習建議用戶在照片中標記某些人物,而警察也利用這科技在照片及影片中搜尋嫌疑犯,因為現時在機場、商店甚至住宅門口安裝的大量錄像鏡頭已令干犯法律的犯罪份子無所遁形。
健康診斷也在利用機器學習作好用途。例如在心臟病發作後,醫生可回溯之前被忽略的警告訊號。醫生或醫院使用的系統可以輸入過去的醫療記錄,並學習查找輸入數據(行為、測試結果及癥狀)和結果(心臟病發作)間的聯繫。在日後醫生輸入筆記及測試結果的時候,系統就可以比人類更可靠地察覺心臟病發作的癥狀,讓病人及醫生採取行動防止病發。
在網站及流動應用程式作語言翻譯是機器學習的另一用途,而不同應用程式使用的機器學習模式、技巧及演算法都影響它們的表現。
在日常生活中,銀行及信用卡都在使用機器學習 來快速偵測欺詐跡象。這運作換成人手偵查可能需要更長的時間,甚至可能偵測不到。在檢查及標記大量交易(是否欺詐)後,機器學習可以學到在日後的每一宗交易中察覺欺詐行為。這運作透過數據發掘來取得更佳成效。
數據發掘
數據發掘是機器學習的一種,利用分析大數據來作出預測及辨認其規律。雖然這名稱有些誤導,因為它無須深入您的根源數據來尋找有用的數據。事實上,這程序只包括發現數據的規律,以協助將來的決策。
以信用卡公司為例,假如您擁有信用卡,您有可能會收到銀行通知說您的信用卡發生了可疑行為。到底銀行為何能這麼快速的察覺這些行為並幾乎馬上發出警示? 這就是持續數據發掘支援的欺詐防護的成果。在 2020 年初,單在美國已發出超過 1 萬 1 千億張信用卡。這些信用卡的交易產生了大量數據可作發掘、搜尋規律及學習之用,以辨識日後的可疑交易。
深層學習(Deep Learning)
基於神經網絡,深層學習是一個特別種類的機器學習。神經網絡模擬人類腦部神經細胞的決策或了解事物功能,例如一個六歲孩童在見到一個臉容時,可以在瞬間透過腦部分析其頭髮顏色、臉部特徵、疤痕及其他表徵決定這人是否他的母親。機器學習透過深層學習複製這個功能。
神經網絡有三至五個層面:輸入層、一至三個隱蔽層、與及一個輸出層。隱蔽層作出的決定將逐一透過輸出層作出。頭髮是甚麼顏色? 眼睛是甚麼顏色? 是否有疤痕? 由於這些層面可以增至數以百計,因此它被稱為深層學習。
機器學習的種類
機器學習演算法的四大基本種類為:監督式、半監督式、非監督式及強化式。機器學習專家相信,約 70% 在使用的機器學習演算法都是受監督的。它們配合已知或已標籤的數據集運作,例如貓狗圖片等。這兩種動物的圖片都是已知的物件,因此管理員可以標籤圖片然後轉交予演算法。
非監督式機器學習演算法可以從未知的數據集學習,以 TikTok 為例,由於有很多不同題材的短片,加上數據未被標籤,基本上沒有可能以監督方式訓練演算法。
而局部受監督的機器學習演算法就會利用少量已知及已標籤的數據集來進行初步訓練,然後再利用較大量未被標籤的數據集來繼續訓練。
強化式機器學習演算法並不會進行初步訓練,但會在整個過程中以試誤法進行學習。試想像一個機械人在學習攀石,每次跌倒它都可以學習到甚麼是錯誤的,並會不斷改變行動直至成功為止。又以訓練狗隻為例,訓練員會利用獎賞來訓練犬隻學習遵從指令,這個正面強化的作用令犬隻會持續遵從指示,並會改變一些不能帶來有利回報的行為。
比較監督式與非監督式的機器學習
監督式機器學習
它採用已知、被確認及已分類的數據集來尋找其特有規律。讓我們以之前的貓狗圖片為例,您可以在一個大型的數據集內包含不同種類動物、數以百萬計的圖片,由於動物種類是已知的資訊,它們將被分組及標籤,然後送交監督式機器學習演算法來學習及了解。
監督式演算法會比較輸入和輸出的數據,與及圖片和動物種類標籤,並最終學習到在接收的新圖片中辨識某一種動物。
非監督式機器學習
非監督式機器學習演算法就像垃圾電郵過濾一樣,在開始時管理員會設定過濾程式來搜尋電郵內的特定字句,以決定它是否垃圾電郵。不過此方法己不再有效,而非監督式就更能有效達致目標。非監督式機器學習演算法會接收未被標籤的電郵並尋找其特定規律。當發現這些特定規律時,它會學習到垃圾電郵的面貌及可以在運作環境中辨識它們。
機器學習技巧
機器學習技術可以協助解決問題,但需要視乎所面對的問題來選擇某一特定的機器學習技術。以下是六個常見情況:
迴歸技巧(regression technique)
迴歸技巧可用於預測國內市場價格或決定在特定時間及特定地區銷售某一產品的最佳價格。根據迴歸理論,即使價格出現浮動,它最終都會回歸至平均價格。例如樓房價格雖然在不斷上昇,但平均價始終會重現,您可以將在一段時間內的價格繪製成圖表,並從中找出平均值。當紅線不斷在圖表中向上移動,就顯示出對未來的預測。
分類
分類就是將數據歸類至已知的類別,您可以尋找相信是好的顧客(會再次光顧及增加購物額)或預測某些客戶會轉至其他地方購物。參考歷史數據可以預測不同類別顧客的行為,您亦可以將之應用至現有顧客及預測他們屬於那一組別,從而更有效率地進行市場活動,並將有機會離開的顧客轉為再次光顧。這亦是監督式機器學習的一個好例子。
聚類分析
與分類技巧不同,聚類分析是非監督式機器學習的一種。在聚類分析中,系統會將您不知怎樣分類的數據歸類,這種機器學習對分析醫療影像、社交網絡及尋找異常情況十分有用。
Google 使用聚類分析為其產品作歸納、壓縮數據及保護私隱,包括 YouTube 影片、Play 應用程式及 Music 的音樂。
偵測異常
異常偵測是用作尋找異常值的方法,就如在羊群中找出黑羊一樣。在面對大量數據的時候,以人手找出這些異常值是不可能的事。但採用異常偵測就可以解決問題,例如數據科學家處理不同醫院輸入的醫療帳單數據時,異常偵測就可以找出方法將帳單歸類,並有機會會發現一些可能與欺詐有關的異常值。
購物籃分析
購物籃分析可用作預測顧客在未來的購買行為。例如,假如顧客將碎牛肉、蕃茄及烘玉米餅放入購物籃,您會預期該顧客也會購買芝士及酸乳酪。透過向網上購物者建議他們可能忘記的產品或將店內產品歸類,這些預測可以用作帶來額外營業額。
兩位麻省理工教授更利用此方法發現了「harbinger of failure」理論,顯示顧客會喜歡失敗的產品。假如您能察覺此點,您可以決定是否繼續銷售一個產品,或是應用甚麼市場策略來增加營業額。
時間序列資料
時間序列資料一般指從很多人戴在手上的健身監測器所搜集的數據,包括心跳率、每分鐘/每小時步行的步數,甚至血氧飽和度等。這些數據可用作預測某人在日後跑步的可能性,亦可用來搜集機械的數據,包括震動、噪音及壓力程度來預測故障的時間。
機器學習演算法
假如機器學習的目的是要從數據中學習,您要如何設計一個可以學習及尋找有意義統計學數據的演算法? 機器學習演算法支援監督式、非監督式及強化式機器學習的程序。
數據工程師會編寫演算法來讓一部機器學習及尋找數據中的意義。
讓我們看看一些常見的特別演算法,共有五種:
- 線性迴歸演算法(linear regression algorithm)將獨立及非獨立的變異值包含在圖表中,並繪畫直線找出平均值或趨勢。韋氏大字典將迴歸定義為「在一個或多個獨立變異值擁有指定數值的條件下,取得隨機變異值的平均值的功能」。此定義亦適用於邏輯迴歸(logistic regression)。
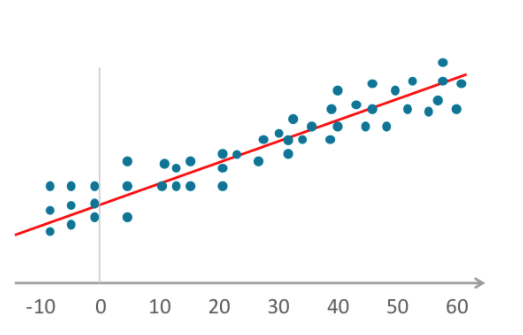
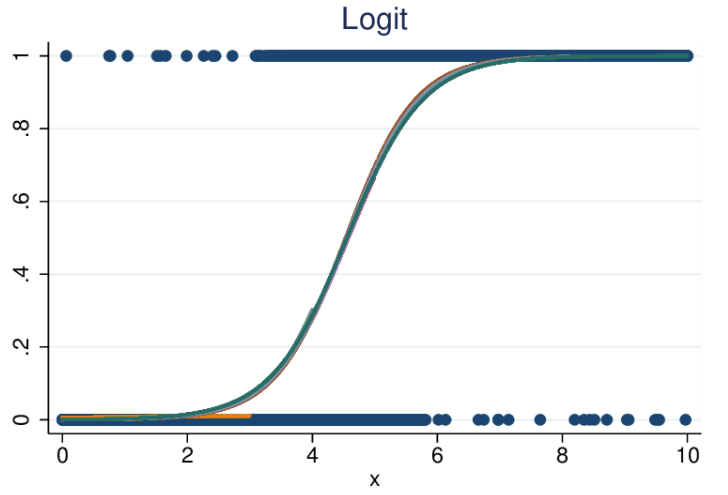
- 邏輯迴歸與線性迴歸一樣,亦會將變異值包含圖表上,但繪畫的線條並非直線,而是呈乙狀函數形狀。
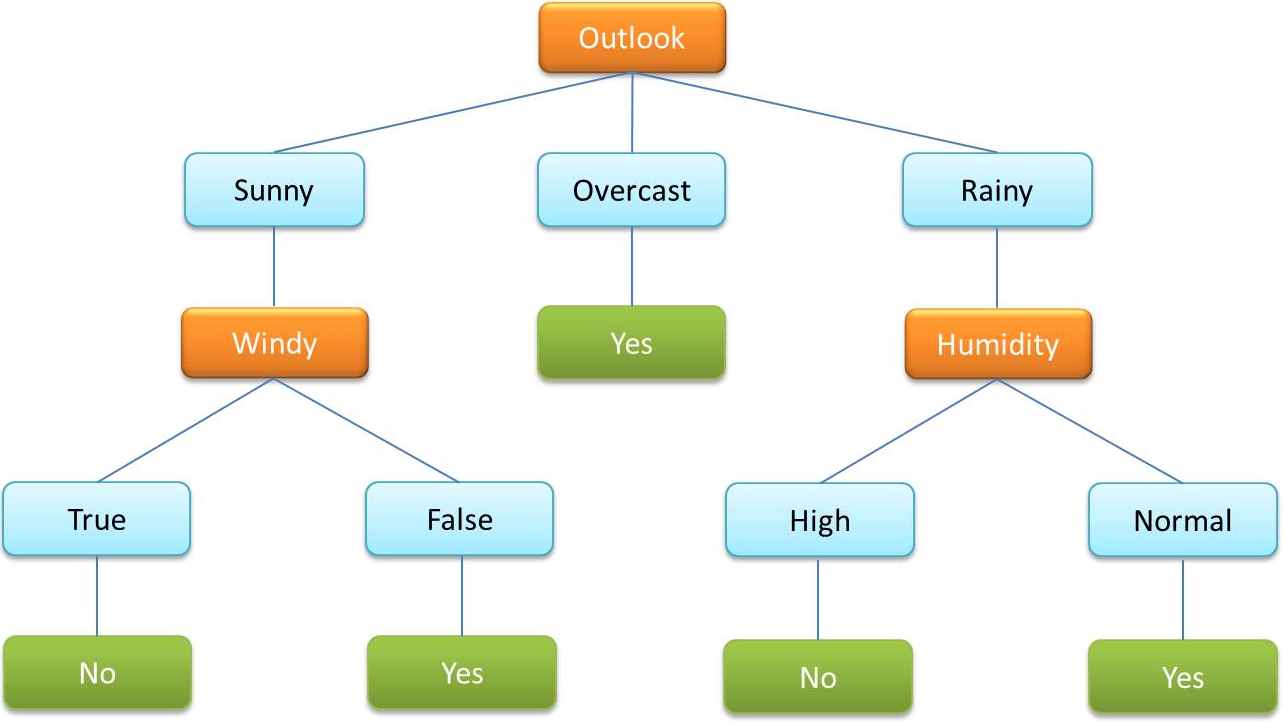
- 決策樹是監督式機器學習中常見的演算法,主要用來以種類及持續變異值來分類數據。
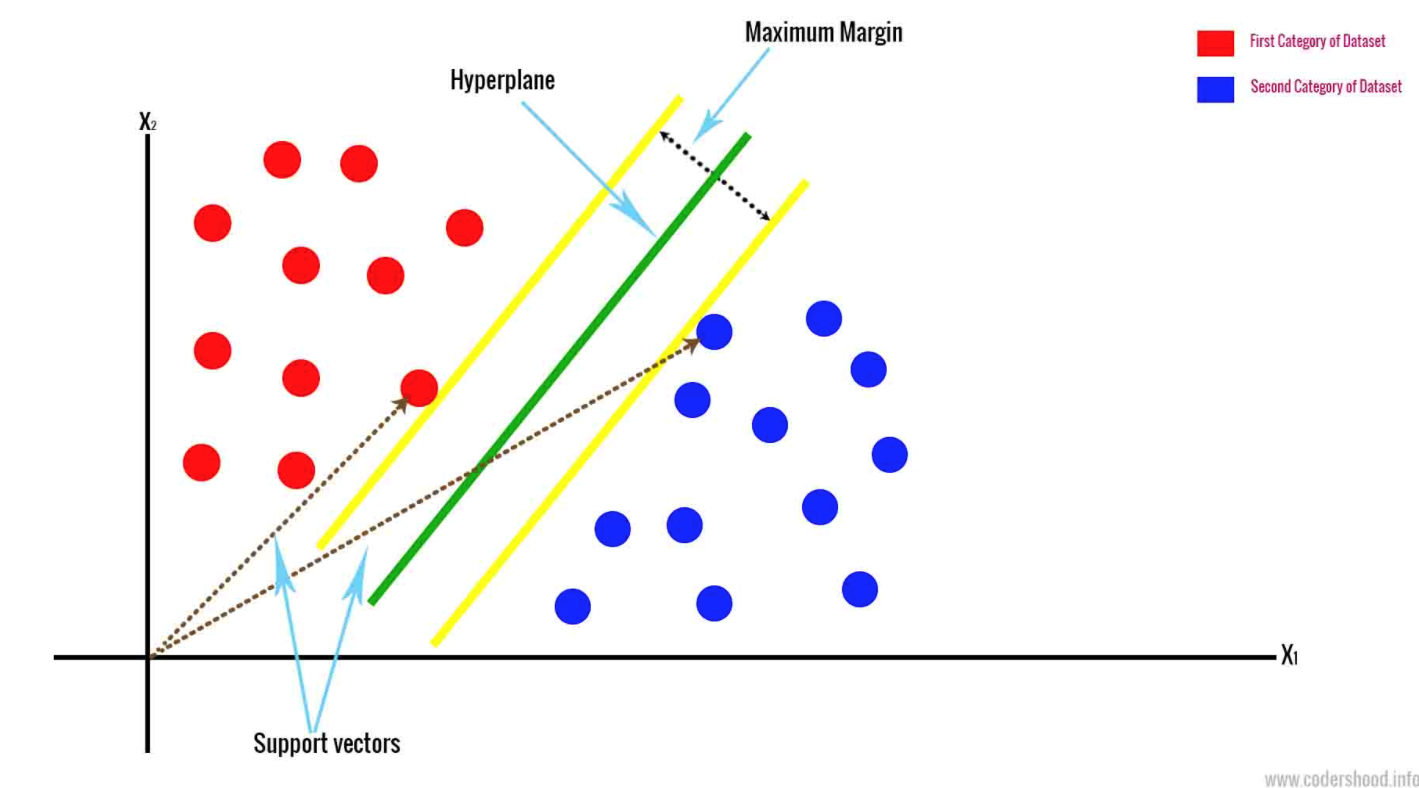
- 支援向量機(Support Vector Machine)在兩個最接近的數據點繪畫一個超平面,以邊緣化不同類別來分隔數據。它會根據 n 維空間來分類數據,而 n 代表您擁有不同功能的數量。
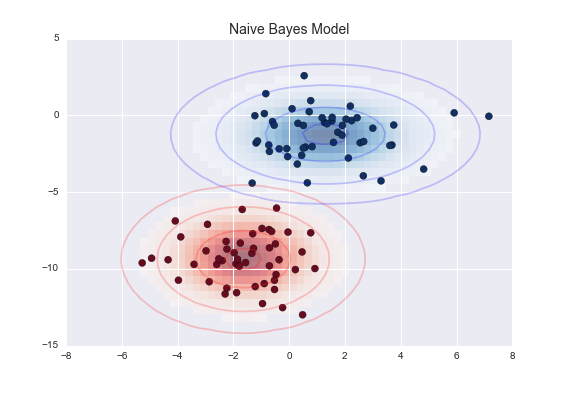
- 單純貝氏分類器(Naïve Bayes)用作計算達到某一結果的機率,是非常有效率的演算法,效能比其他尖端級模式更優勝。單純貝氏分類器模式說明了某一特性並不依附於另一特性的存在。
機器學習模式
在結合不同種類的機器學習(監督式、非監督式或其他)、技巧及演算法後,所得結果就是一個已受訓練的檔案。這檔案可以輸入新數據及能夠識別規律,並針對業務、管理人員及顧客作出預測或決策。
機器學習的最佳語言
機器學習語言就是讓系統懂得學習的指令,而每個語言都由一個用戶社群支援,提供互相學習及指引。每個語言會各自擁有圖書館供機器學習使用。
以下為根據 GitHub 2019 年 10 大調查所得的 10 種最常用語言:
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala 是一種用於與大數據互動的語言
Python 機器學習
Python 是最常用的機器學習語言,因此我們會深入探討這語言。
根據喜劇 Monty Python 命名,Python 是一種解釋型、開放源碼及物件導向的語言。由於它是解釋型語言,它在被 Python 虛擬機器執行前會先轉換為位元組碼。
Python 的一系列功能令它成為機器學習的優先之選:
- 可以即時使用的大量功能強大套件,包括 numpy、scipy 及 panda等。
- 簡單而快速地提供原型。
- 大量工具可用於協作。
- 即使數據科學家由抽取數據轉移至建模或是更新其機器學習方案,Python 仍然可以繼續作語言之用,亦即表示數據科學家在建構週期中並不需要更改語言。