
人工智能是一項能讓電腦和機器學習、理解、建立、解決問題、預測結果及作出決策的技術。
目錄
從最基本層面來看,人工智能是指電腦或機器系統能利用機器學習、神經網絡、認知架構等技術來執行人類之前能完成的複雜工作,
包括建立內容、規劃、推理、溝通、從經驗中學習及作出複雜決策等。儘管如此,由於人工智能系統與工具非常廣泛且各有不同,因此沒有任何單一定義可以完美應用在所有事情身上。
自從 1950 年代推出人工智能以來,它幾乎徹底改變了現代生活、社會和技術的各個層面。人工智能可以分析大量資料、掌握模式並取得新的知識,因此幾乎成為人類活動不可或缺的工具,從商業、交通運輸、醫療到網絡資訊保安。
除了其他應用程式之外,企業還可運用人工智能來:
- 降低成本
- 推動創新
- 授權團隊
- 簡化運作
- 加快決策
- 整合並分析研究發現
- 提供即時的客戶支援與服務
- 自動化重複性工作
- 協助產生創意
人工智能簡史
一台能夠自行思考的機器,其概念可追溯至數千年前。在現代化情境下,人工智能是一個明確的概念,可追溯至 1950 年,當時知名技術「Turing Test」的創作者 Alan Turing 發表了一份有關人工智能、計算機與智能等概念的論文。
自從 Turing 發表論文以來,人工智能的應用範圍和功能因為運算力提高、演算法更精密、資料可用提昇,以及出現機器學習、資料探勘和神經網絡等技術所帶動而出現急劇演變。
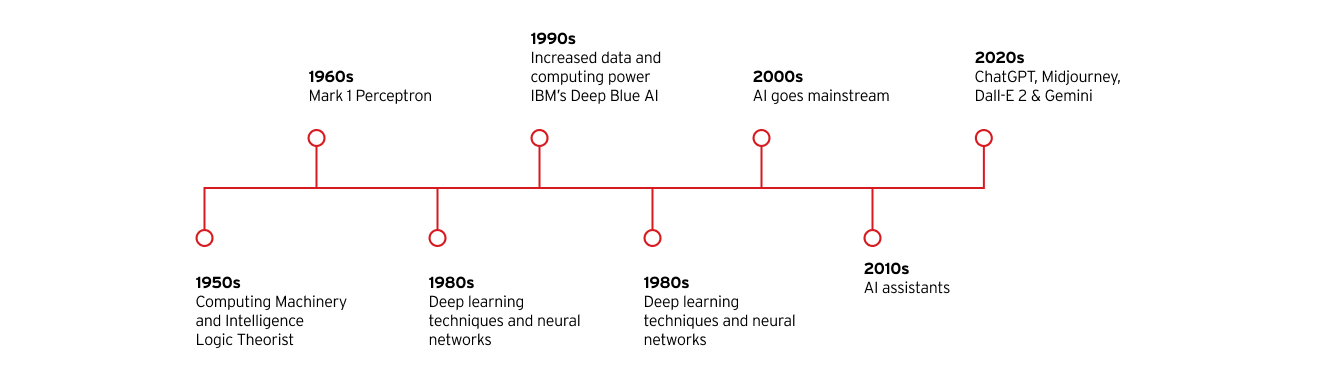
人工智能演變的重要里程碑
年度
里程碑
50 年代
- Alan Turing 發表「運算機械與智能」
- John McCarthy 發表「人工智能」一詞
- 成立第一個人工智能電腦程式 Logic Theorist
60 年代
- 建立第一台在反覆嘗試錯誤中學習的電腦 Mark 1 Perceptron
80 年代
- 深度學習技術與神經網絡的成長
90 年代
- 提升資料與運算能力,加速人工智能的成長與投資
- IBM 的 Deep Blue 人工智能擊敗世界圍棋冠軍 Garry Kasparov
2000 年代
- 人工智能因 Google 人工智能搜尋引擎、Amazon 產品推薦引擎、Facebook 臉部辨識系統及第一輛自動駕駛汽車的問世而成為主流。
2010 年代
- 推出像 Apple 的 Siri 和 Amazon 的 Alexa 這樣的人工智能助理
- Google 推出開源機器學習框架 TensorFlow
- AlexNet 神經網絡利用圖形處理器來訓練人工智能模型
2020 年代
- OpenAI 發表大受歡迎的第三代 ChatGPT 大型語言模型生成式人工智能。
- 生成式人工智能熱潮繼續,Midjourney 和 Dall-E 2 影像產生器及像 Google Gemini 這樣的大型語言模型聊天機器人陸續推出。
人工智能如何運作?
人工智能系統的運作方式是通過輸入或擷取大量資料,並使用類似人類的認知流程來分析及評估資料。如此一來,人工智能系統就能發掘並分類規律,並利用這些規律來執行任務或預測未來的成果,而不需人為監督或指示。
例如,像 Midjourney 這樣的影像生成人工智能程式,如果收到了大量的照片,就能學習如何根據用戶輸入的提示來製作「原始」影像。同樣地,受過大量文字訓練的客戶服務人工智能聊天機器人,也能學習如何模仿客服人員來與客戶互動。
儘管每套系統都不同,但人工智能模型的程式設計通常都採用相同的五個步驟:
- 訓練:人工智能模型會匯入大量資料,並使用一系列演算法來分析和評估資料。
- 合理性:人工智能模型會將所收到資料分類,並找出其中的任何規律。
- 微調:當人工智能模型嘗試了不同的演算法時,就會了解哪些演算法最成功,並據此調整動作。
- 創作:人工智能模型會運用所學到的知識來執行指派的任務、作出決策,或是製作音樂、文字或影像。
- 改善,最終,人工智能模型會不斷調整以改善其準確性,並從經驗中有效學習。

機器學習與深度學習
大多數現代化人工智能系統都採用各種不同的技術來模擬人類智慧的流程。其中最重要的就是深度學習與機器學習。雖然機器學習和深度學習的用詞有時可互換使用,但其實它們在人工智能訓練的情境下都是各自獨特的流程。
機器學習使用演算法來分析、分類、排序、學習及理解大量資料,進而產生精確模型並預測結果,而不必確切被指示該如何做。
深度學習是一種機器學習的子類別,它利用神經網絡模擬人類大腦的結構和功能來達成相同的目標。以下我們將詳細說明這兩個概念。
機器學習的基本原則
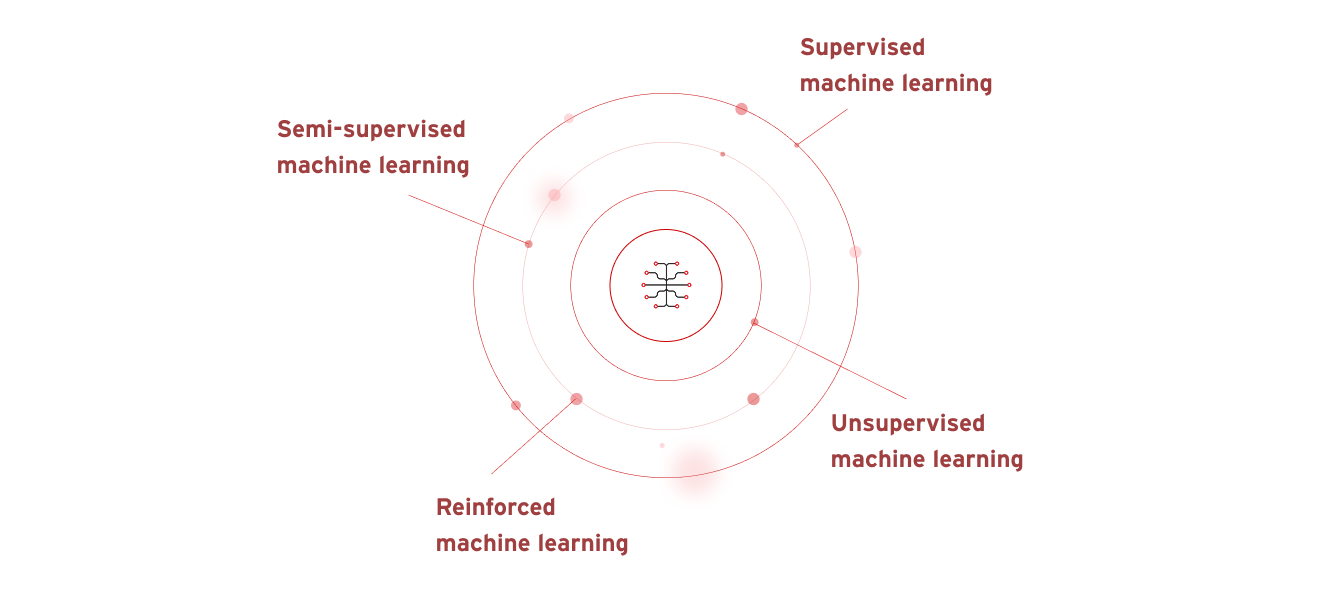
機器學習有四種主要類型:
- 監督式機器學習:人工智能會使用已知、已建立及分類的資料集來發掘規律,然後再將它們匯入演算法。
- 半監督式機器學習:人工智能利用少為人知及標記的資料集進行訓練,然後套用至大型、未標記及未知的資料集。
- 非監督式機器學習:人工智能從未知、未標記、未分類的資料集中學習。
- 強化機器學習:人工智能模型一開始並未經過任何資料集的訓練,所以會先從實驗中學習錯誤,然後再修改其行為直到成功為止。
機器學習是讓自動駕駛汽車能夠妥善因應環境變化,讓乘客安全抵達選定的目的地。其他機器學習應用程式則從影像和語音辨識程式、語言翻譯程式、角色導向人工智能代理程式、資料探勘到信用卡詐騙偵測、醫療診斷,以及社交媒體、產品或品牌推薦等。
深度學習與神經網絡
深度學習是機器學習的其中一種,是以進階神經網絡為基礎,以機器學習演算法模擬人類大腦中的神經元如何運作,進而從大量資料識別複雜的規律。
例如,即使是年幼的孩子也能辨認出家長與其他人的分別,因為他們的大腦可以在一眨眼之間分析並比較數百種獨特或與眾不同的細節,從眼睛和頭髮的顏色到獨特的表情或臉部表情。
神經網絡會模仿人類大腦的運作方式,同樣分析了數千或數百萬個資料中的細節,進而偵測並辨識它們之間的大規律。例如,包括 OpenAI 的 ChatGTP 或 Midjourney 影像產生器這類生成式人工智能系統,會利用深度學習來擷取並分析大量的影像或文字,接著再利用這些資料來產生與原始資料相似但有所不同的新文字或影像。
人工智能的最新發展是什麼?
近年來,自然語言處理、電腦視覺、強化學習,以及尖端創新技術如生成對抗網絡(GAN)、轉型模型及真正採用人工智能技術的機器(AIEM)等技術的演進已大幅擴大了人工智能系統功能,可更仔細地模擬人類的智慧流程,產生更真實的內容,並執行日益複雜的工作。
機器學習與深度學習的突破
近年來,自然語言處理、電腦視覺、強化學習,以及尖端創新技術如生成對抗網絡(GAN)、轉型模型及真正採用人工智能技術的機器(AIEM)等技術的演進已大幅擴大了人工智能系統功能,可更仔細地模擬人類的智慧流程,產生更真實的內容,並執行日益複雜的工作。
機器學習與深度學習的突破
機器學習與深度學習演算法的革命性突破,讓研究人員和開發人員為各種真實世界應用程式打造出極為精密的人工智能系統。
例如,人工智能聊天機器人每天都由數百萬家企業用來回答問題、銷售產品,以及與客戶互動。此外,企業也會運用人工智能演算法來發掘客戶購物的趨勢,並且針對新產品、品牌或服務提供個人化建議。
在自動語音辨識領域,Siri 和 Alexa 這類人工智能服務會使用自然語言處理來將人類語音轉換成書面內容。同樣地,人工智能導向的「電腦視覺」神經網絡的進步也讓人們更容易在社交媒體上標記照片,進而讓自動駕駛汽車更安全。
其他採用機器學習或深度學習的人工智能範例包括自動化股票交易演算法、可在工廠或組裝線上重複執行任務的智能機器人,以及運用機器學習來協助銀行偵測可疑交易並防範金融詐騙。
人工智能在網絡資訊保安領域的角色不斷演進
談到人工智能在網絡資訊保安領域所扮演的角色時,有兩個不同但相互關聯的領域需要考慮:人工智能防護與人工智能網絡資訊保安。
人工智能防護是指採用資訊保安措施來保護企業的人工智能組合、降低或消除人工智能資訊保安風險,以及保護網絡從端點到人工智能模型的所有人工智能系統、元件及應用程式。包括:
- 保護人工智能組合、基礎架構、模型及訓練資料免受攻擊
- 維持機器學習與深度學習流程的資料完整性
- 解決人工智能意識偏差、透明度、可解釋性及其他道德疑慮的問題
確保人工智能的使用或開發完全符合所有相關法律、政策和法規。
人工智能網絡資訊涵蓋了人工智能工具主動強化企業資訊防護的所有不同方式,而且比任何人力網絡資訊保安團隊或資訊保安運作中心都能更快、更準確、更有效。包括使用人工智能來:
- 即時發掘網絡威脅並防範網絡攻擊
- 更快、更精準地消除網絡資訊保安落差與漏洞。
- 將威脅偵測及回應及其他網絡資訊保安工具自動化,加快事件回應速度。
- 提升威脅情報,支援更有效率的威脅管理。
- 自動化漏洞掃描和資料記錄檔分析等日常作業,讓網絡資訊保安團隊能解決更複雜的威脅。
網絡資訊保安人工智能應用程式範例
企業已經開始運用人工智能來提升網絡資訊保安狀況、偵測與回應網絡攻擊,並且保護自己的網絡,防範資料外洩 、分散式阻斷服務攻擊、勒索程式、惡意程式、網絡釣魚攻擊及身份威脅。
在威脅偵測與回應方面,人工智能可偵測及預測網絡威脅、分析活動記錄檔與網絡流量的規律、認證及保護密碼與用戶登入、使用臉容識別與 CAPTCHA 登入、模擬網絡攻擊、掃瞄網絡漏洞,以及建立自動化的網絡資訊保安防禦來防範最新或新興的威脅。包括以下工具:
- 採用人工智能技術的次世代防火牆
- 人工智能安全資訊和事件管理
- 人工智能雲端與端點防護系統
- 人工智能網絡偵測與回應
- 人工智能擴展式偵測與回應
當攻擊確實發生時,人工智能還可根據企業預先設定的政策和程序手冊來提供有效的修正策略,或者自動回應資訊保安事件。如此有助於降低成本、減低攻擊所造成的損害,讓企業更快復原。
人工智能的開發與使用需要哪些道德考量?
與其他類型的運算系統相比,人工智能顯然提供了更多強大的優勢。但如同任何新技術一樣,人工智能的開發、採用和使用,也有一些風險、挑戰和道德問題需要考慮。
意識偏差與公平
人工智能模型是由人類使用現有內容所擷取的資料來訓練。這樣就有可能讓模型反映出或強化內容中包含的任何隱含偏見。這些偏見可能導致演算法、預測及模型的決策出現不平等、歧視或不公平的情況。
此外,由於生成式人工智能工具所製作的內容非常真實,因此有可能遭到濫用,進而產生或散播錯誤資訊、不實資訊、有害內容,以及深偽影片、音訊和影像。
私隱權疑慮
此外,人工智能的開發和使用也存在著許多私隱權問題,尤其是醫療、銀行、法律服務等專門處理高度個人、敏感或機密資訊的產業。
為了保護這些資訊,人工智能導向的應用程式必須遵循一系列關於資料安全、私隱與資料的良好守則。包括採用資料匿名化技巧、建置強大的資料加密,以及採用進階網絡資訊保安防禦來防範資料失竊、外洩及黑客攻擊。
合規
許多主管機關和架構,如歐盟通用資料保護法規都要求企業在保護個人資訊、確保透明度和責任感、保護私隱時,必須遵守一套明確的規則。
為了遵守這些法規,企業應確實制定合適的人工智能政策來監控和控制用來開發全新人工智能模型的資料,並且保護任何可能含有敏感或個人資訊的人工智能模型,以免遭到黑客攻擊。
人工智能技術的未來是什麼?
人工智能未來將發生什麼事,當然是無法預測的。但根據當前人工智能的使用和技術趨勢,我們還是可以針對未來發展做出一些經過教育的假設。
人工智能研究的最新趨勢
就人工智能研究而言,自動化人工智能系統、元人工智能和元學習、開放源碼大型語言學習模型、數碼分身及風險驗證紅隊演練,以及人和人工智能聯合決策都可能徹底改變人工智能的開發方式。
複雜的新系統,如神經對稱式人工智能、真正的人工智能機器及量子機器學習,也很可能進一步提升人工智能模型、工具和應用程式的觸及率和功能。
另一項可能改變人工智能運作方式的技術,就是改用新一代代理式人工智能,也就是能夠自行做出決策並採取行動的人工智能,而不需人為指導、監督或介入。
根據 Gartner 技術分析師指出,到了 2028 年,代理式人工智能就能佔所有日常工作決策的 15%。此外,代理人工智能用戶介面也可能變得更加主動,也更容易成為人性化的代言人,他們學習如何像人一樣行動,並執行更複雜的任務、做出更重要的業務決策,以及提供更個人化的客戶建議。
人工智能對員工的潛在影響
隨著人工智能提升營運效率並接管日常工作,而像 ChatGPT 和 Midjourney 這樣的生成式人工智能引擎也越來越強大及越來越普及,已對許多產業崗位可能產生的衝擊帶來相當程度的疑慮。
但如同過去的網絡、個人電腦、手機以及其他典型的技術轉換一樣,人工智能也很可能創造了新的商機,甚至創造了需要專業人才的全新產業。
因此,與其專注於工作崗位損失,更大的挑戰是要如何更好地訓練員工,讓他們獲得新的機會,並促進從人才縮減到職業成長的轉變。
人工智能在解決全球挑戰時扮演的角色
除了提升營運效率並提升網絡資訊保安之外,人工智能也有機會協助解決今日人類所面臨的一些重大挑戰。
在醫療領域,人工智能能協助醫師更快、更準確地診斷、追蹤未來疫情的蔓延,並加速發現新的藥物、治療和疫苗。
人工智能技術可提升緊急應變速度與效率,因應自然與人為災害及惡劣天氣事件。
此外,人工智能還能協助解決氣候變遷的問題,將再生能源的使用最佳化、減少企業的碳足跡、追蹤全球森林砍伐與海洋污染的程度,以及提升回收、廢水處理與廢棄物管理的效率。
其他可能的趨勢和發展
其他人工智能的可能未來趨勢、功能和應用程式包括:
- 大型語言模型防護,保護大型語言模型免於惡意攻擊、一般誤用、未經授權的存取以及其他網絡威脅,包括保護大型語言模型資料、模型及相關系統與元件的措施。
- 以用戶為中心的個人化人工智能,提供更客製化、更智慧的個人化客戶服務,包括電郵端點行銷。
- 運用人工智能模型來模擬企業資訊科技系統的攻擊,進而促進紅隊演練與數碼分身練習,測試漏洞並防範任何漏洞或弱點。
哪裡可以取得人工智能和網絡資訊保安方面的協助?
Trend Vision One™ 在單一、整合的人工智能平台中,為整個人工智能組合提供無可匹敵的端對端防護。
Trend Cybertron 是全球首創的主動式網絡資訊保安人工智能,它具備了豐富的功能。Trend Vision One 內含一整套代理式人工智能功能,根據真實世界的情報與資訊保安營運而不斷演進。
如此就能迅速因應新興威脅,提升企業的資訊保安狀況、提升營運效率、將資訊保安營運從被動轉型成主動,並且保護人工智能基礎架構的每一層。


Fernando Cardoso 是趨勢科技產品管理副總裁,專長於不斷演進的人工智能與雲端世界。他的職業生涯由擔任網路與銷售工程師開始,並在數據中心、雲端、DevOps 及網絡資訊保安領域都具備優異技能,而他對這些領域依然煥發了無比熱情。
常見問題
甚麼是人工智能?
人工智能是一套運用科技來模仿人類思考、運作及決策方式的電腦。
人工智能真正能做些甚麼?
人工智能模型使用複雜的演算法,並利用大量「從學習而來」的資訊來計算用戶問題的答案,或者根據用戶提示產生內容。
Siri 是人工智能嗎?
Siri 是一種簡單的人工智能形式,使用機器學習和語音辨識等技術來了解及回應人類語音。
人工智能是好是壞?
如同所有技術一樣,人工智能本身並不自帶良性或惡性。這工具可用於正面和負面目的。
甚麼是人工智能的主要目標?
人工智能的主要目標是讓電腦做出更聰明的決策、完成更困難的工作,並且學習經驗,而不需人為投入。
為何要開發人工智能?
人工智能的開發目的是為了協助自動化重複性工作、解決複雜的問題,並且讓不同產業擁有更先進的研究與創新能力。
人工智能有哪些風險?
人工智能所帶來的一些風險包括偏差與公平性、私隱風險、網絡保安風險,以及取代職位的可能性。
人工智能是由誰製作的?
電腦科學家 Alan Turing(1912 – 1954 年)和 John McCarthy 1927 – 2011 年)通常被視為非官方的「人工智能之父」。
現實生活中的人工智能是甚麼?
在我們的日常生活中,有許多人工智能的範例,從智能手機上的軟件到能回應常見客戶問題的聊天機器人。
甚麼是簡單的人工智能?
一些簡單的人工智能範例包括像 Siri 或 Alexa 這樣的語音助理、像 Google 這樣的智能搜尋引擎、客戶服務聊天機器人,甚至是機器人吸塵機。
甚麼是人工智能的缺點?
人工智能的缺點包括私隱與偏見、網絡保安風險,以及在某些領域對職位的潛在影響。
甚麼是人工智能的五大缺點?
視其使用方式,人工智能可能造成職位流失、產生錯誤資訊、竊取私人資訊、降低創造力,以及過度依賴技術。
如何開啟人工智能?
大多數的人工智能工具都可以在手機、電腦、應用程式或網站的設定功能中開啟或關閉。
我可以免費使用人工智能嗎?
許多人工智能工具,如搜尋引擎或 Alexa 都是完全免費的。其他,如 ChatGPT,則同時提供免費和付費選項。商業級人工智能通常只有付費選項。
哪一種人工智能完全免費?
絕大多數的人工智能廠商都提供免費的入門版,包括 Microsoft Copilot、Grammarly、Google Gemini 及 ChatGPT。
目前最熱門的人工智能應用程式是甚麼?
目前,最熱門的人工智能應用程式包括 ChatGPT、Google Maps、Google Assistant、Microsoft Copilot 和 Google Gemini。
每個人使用的人工智能寫作應用程式為何?
一些最熱門的人工智能輔助寫作應用程式包括 Grammarly、ChatGPT、Wresonic、Jasper 和 Claude。
每個人都免費使用甚麼人工智能應用程式?
Google Gemini、Microsoft 的 Copilot 以及 ChatGPT 都是目前最普遍使用的免費人工智能應用程式之一。
目前最好的人工智能聊天機器人是甚麼?
雖然聊天機器人是否「最佳」完全取決於您的需求,而一些最受歡迎的人工智能聊天機器人包括 Perplexity、Google Gemini、Jasper 和 ChatGPT。
人工智能在日常生活中的範例為何?
日常生活中常見的人工智能範例包括智能手機、人工智能搜尋引擎、客戶服務聊天機器人,以及 Siri 和 Alexa 等數碼語音助理。