
Forma sztucznej inteligencji (AI), która umożliwia systemom uczenie się wzorców na podstawie danych i poprawianie wydajności wykonywania zadań w miarę upływu czasu bez konieczności wyraźnego programowania.
Spis treści
Uczenie Maszynowe Definicja
Stworzenie komputerów, które wiedzą, co robić, bez wydawania im konkretnych poleceń, jest marzeniem ludzi od wielu lat.
Przykładem praktycznego wykorzystania technologii machine learning jest skonstruowanie samochodu, który samodzielnie bezpiecznie dowiezie pasażera (oczywiście siedzącego na fotelu kierowcy) do celu, rozpoznając pieszych i dziury w drodze oraz szybko i skutecznie reagując na zmiany otoczenia.
Jak to działa? Zacznijmy od analizy samych danych biznesowych.
Uczenie maszynowe (Machine Learning, ML) to rodzaj sztucznej inteligencji (SI), która umożliwia firmom zdobywanie informacji i wyciąganie wniosków z dużych ilości danych. Weźmy na przykład Twittera. Według Internet Live Stats użytkownicy tego serwisu codziennie wysyłają około 500 milionów tweetów. W skali roku daje to około 200 miliardów tych krótkich wiadomości. Żaden człowiek nie jest w stanie przeanalizować, skategoryzować, posortować i przyswoić takiej ilości danych, a następnie przewidzieć czegokolwiek na ich podstawie.
W jaki sposób uczenie maszynowe może pomóc firmom
Uczenie maszynowe pomaga chronić firmy przed cyberzagrożeniami. Jednak najlepiej sprawdza się jako część wielowarstwowego rozwiązania zabezpieczającego.
Zdobycie cennych informacji za pomocą technologii machine learning (uczenia maszynowego – ML) wymaga od firmy dużego nakładu pracy. Aby maksymalnie wykorzystać możliwości ML, należy zdobyć czyste dane i przygotować precyzyjne pytania. Następnie można wybrać optymalny w danej sytuacji model i algorytm. Uczenie maszynowe (ML) nie jest prostym ani łatwym w przeprowadzeniu procesem. Aby odnieść realne korzyści z tej technologii, trzeba wykonać rzetelną pracę.
Uczenie maszynowe (ML) ma określony cykl życia.
- Zrozumienie — dlaczego korzystasz z machine learning (uczenia maszynowego – ML) i co chcesz zrobić lub czego chcesz się dowiedzieć.
- Gromadzenie i oczyszczanie danych — masz potrzebną ilość danych o stopniu czystości wystarczającym do tego, aby wydobyć z nich interesujące Cię informacje.
- Wybór cech — polega na określeniu danych, które należy wprowadzić do ML, aby zbudować model ML. Metody wyboru cech różnią się w zależności od rodzaju użytego algorytmu. Powiedzmy na przykład, że wybraliśmy algorytm drzewa decyzyjnego. W takim przypadku analityk lub narzędzie modelujące może na przykład zastosować do kolumn bazy danych tzw. „wskaźnik zainteresowania” (interestingness score), aby stwierdzić, czy wykorzystać określone dane do budowy modelu.
- Wybór modelu — wybór pliku (modelu), który został przeszkolony pod kątem przetwarzania i wyszukiwania określonych „rzeczy” w danych. Model otrzymuje algorytm działania oraz dane testowe i na ich podstawie formułuje swoje wnioski.
- Szkolenie i strojenie — wnioski sformułowane przez model, pozwalają upewnić się, że uzyskasz odpowiedzi na swoje pytania.
- Ewaluacja modelu i algorytmu w celu stwierdzenia, czy jest gotowy do użycia, czy trzeba cofnąć się o kilka kroków i udoskonalić model, cechę, algorytm lub dane, aby osiągnąć postawione cele.
- Wdrożenie przeszkolonego modelu do produkcji.
- Przegląd wyników istniejącego modelu w środowisku produkcyjnym

Zastosowania machine learning
Uczenie maszynowe (machine learning, ML) to metoda pozwalająca firmom zrozumieć posiadane dane i wyciągać z nich istotne informacje. Firma może wykorzystać tę technologię w wielu różnych poddziedzinach. Wszystko zależy od tego, czy celem jest zwiększenie sprzedaży, stworzenie wyszukiwarki, integracja poleceń głosowych z produktem, czy stworzenie samochodu autonomicznego.
Poddziedziny machine learning
W dzisiejszym biznesie machine learning ma bardzo szeroki wachlarz zastosowań, który z czasem z pewnością będzie się powiększał. Poddziedziny ML obejmują m.in. media społecznościowe i rekomendacje produktów, rozpoznawanie obrazów, diagnostykę, tłumaczenie językowe, rozpoznawanie mowy oraz data mining.
Platformy mediów społecznościowych, takie jak Facebook, Instagram i LinkedIn wykorzystują ML do proponowania na podstawie polubionych przez użytkownika wpisów stron, które można obserwować lub grup, do których można dołączyć. Technologia ta analizuje dane historyczne na temat tego, co polubili inni lub dotyczące treści podobnych do tych, które polubił użytkownik, aby przygotować rekomendacje lub dodać je do jego kanału wiadomości.
Ponadto technologię ML można wykorzystywać w sklepach internetowych do polecania produktów na podstawie poprzednich zakupów, wyszukiwań i innych czynności wykonywanych przez podobnych użytkowników.
Bardzo ważną dziedziną zastosowania technologii ML w dzisiejszych czasach jest rozpoznawanie obrazu. Dzięki niej platformy mediów społecznościowych umożliwiają oznaczanie ludzi na zdjęciach. Policja wykorzystuje ją do wyszukiwania podejrzanych na zdjęciach lub nagraniach wideo. Dzięki niezliczonym kamerom zainstalowanym na lotniskach, w sklepach i przy dzwonkach do drzwi można wykryć wielu sprawców przestępstw lub sprawdzić, dokąd się oddalili.
Kolejną ważną dziedziną zastosowań ML jest diagnostyka medyczna. Po incydencie takim, jak zawał serca można przejrzeć dane, aby odkryć sygnały, które zostały przeoczone. Do systemu używanego przez lekarzy lub szpitale można wprowadzać historyczne dane medyczne, aby wykryć powiązania między danymi wejściowymi (zachowanie, wynik badania, objaw) i wyjściowymi (np. zawał serca). Kiedy w przyszłości lekarz wprowadzi swoje notatki i wyniki badań do systemu, algorytm będzie mógł wykrywać objawy zawału serca znacznie skuteczniej niż potrafią to robić ludzie, co pozwoli na wdrożenie działań profilaktycznych.
Następnym przykładem zastosowania technologii ML jest tłumaczenie treści stron WWW i aplikacji na platformach mobilnych. Niektóre aplikacje spisują się lepiej, a inne gorzej, co jest efektem zastosowania różnych modeli ML, technik i algorytmów.
W dzisiejszych czasach technologia ML stanowi chleb powszedni w bankowości i systemach obsługi kart kredytowych. Wykrycie pewnych oznak oszustwa, które dla ML nie stanowi żadnego wyzwania, człowiekowi zajęłyby bardzo dużo czasu lub byłyby całkowicie poza jego zasięgiem. Analiza i oznakowanie ogromnej ilości transakcji (uczciwa czy fałszywa) w przyszłości mogą umożliwić wykrywanie oszustw w pojedynczych operacjach. Idealnym rodzajem machine learning (uczenia maszynowego – ML) do tego celu jest data mining.
Data mining
Data mining to typ machine learning, który polega na analizie danych, aby formułować prognozy lub wykrywać wzorce w wielkich zbiorach danych. Termin ten jest trochę mylący, ponieważ technologia ta wcale nie polega na przeczesywaniu przez kogokolwiek, czy to przestępcę czy pracownika, danych w celu znalezienia czegoś przydatnego. Tak naprawdę jest to proces polegający na odkrywaniu w danych wzorców, które mogą się przydać przy podejmowaniu decyzji w przyszłości.
Weźmy na przykład firmę obsługującą karty kredytowe. Jeśli masz kartę kredytową, to Twój bank z pewnością choć raz w życiu informował Cię o podejrzanej aktywności związanej z tą kartą. W jaki sposób bank tak szybko to wykrył i błyskawicznie wysłał Ci ostrzeżenie? Tego typu ochronę przed oszustwami zapewniają właśnie działające bez przerwy algorytmy data mining. Na początku 2020 r. w samych Stanach Zjednoczonych było ponad 1,1 biliona kart kredytowych. Przeprowadzane z ich użyciem transakcje generują ogromną ilość danych wykorzystywanych do data mining, wyszukiwania wzorców i nauki identyfikacji podejrzanych zachowań w przyszłości.
Deep learning
Deep learning (uczenie głębokie) to specyficzny typ ML oparty na sieciach neuronowych. Sieć neuronowa naśladuje sposób działania neuronów w ludzkim mózgu, aby podejmować decyzje lub coś rozumieć. Na przykład sześcioletnie dziecko jest w stanie odróżnić po twarzy swoją mamę od osoby pilnującej przejścia dla pieszych, ponieważ jego mózg bardzo szybko analizuje wiele szczegółów – kolor włosów, rysy twarzy, blizny itd. Machine learning odtwarza te procesy w formie uczenia głębokiego.
Sieć neuronowa ma od trzech do pięciu warstw – jedną wejściową, od jednej do trzech warstw ukrytych i jedną warstwę wyjściową. Warstwy ukryte podejmują decyzje pozwalające stopniowo dojść do warstwy wyjściowej lub wniosku. Jaki jest kolor włosów? Jaki jest kolor oczu? Czy widać bliznę? Kiedy warstw jest kilkaset, mamy do czynienia z uczeniem głębokim.
Rodzaje machine learning
Istnieją zasadniczo cztery typy algorytmów uczenia maszynowego: nadzorowane, półnadzorowane, nienadzorowane i wzmocnione. Specjaliści od ML uważają, że około 70% algorytmów ML, które są obecnie w użyciu, to algorytmy nadzorowane. Operują one na znanych lub oznakowanych zbiorach danych, na przykład zdjęciach psów i kotów. Te dwa gatunki zwierząt są znane, więc administratorzy mogą oznaczyć zdjęcia przed wprowadzeniem ich do algorytmu.
Nienadzorowane algorytmy ML uczą się na podstawie nieznanych zbiorów danych. Weźmy na przykład filmy z serwisu TikTok. Jest ich tam tak wiele i obejmują tak wiele tematów, że nie da się wyszkolić algorytmu na ich podstawie w nadzorowany sposób. Te dane są jeszcze nieoznakowane.
Częściowo nadzorowane algorytmy ML szkoli się wstępnie na niewielkiej próbce danych, która jest znana i oznakowana. Następnie kontynuuje się szkolenie z użyciem większych nieoznakowanych zbiorów danych.
Wzmocnione algorytmy ML nie są wstępnie szkolone. Uczą się metodą prób i błędów na bieżąco. Wyobraź sobie robota, który uczy się jeździć pośród skał. Za każdym razem, gdy coś się nie powiedzie, uczy się, co nie działa i zmienia swoje zachowanie, aż do osiągnięcia sukcesu. Pomyśl o tresowaniu psa i stosowaniu gróźb w celu nauczenia go wykonywania różnych poleceń. Jeśli zastosujemy wzmocnienie pozytywne, to pies będzie wykonywał polecenia oraz będzie zmieniał te zachowania, które nie wywołują pozytywnej reakcji.
Uczenie maszynowe (machine learning, ML) nadzorowane i nienadzorowane
Nadzorowane uczenie maszynowe
Ta technika wykorzystuje znane, ustanowione i sklasyfikowane zbiory danych do wyszukiwania wzorców. Umożliwia rozwinięcie opisanej wcześniej idei wykorzystania zdjęć psów i kotów. Możesz mieć ogromny zbiór danych zawierający wizerunki tysięcy zwierząt na milionach zdjęć. Jako że te gatunki są znane, można je pogrupować i oznakować przed wprowadzeniem do nadzorowanego algorytmu ML, aby nauczyć go ich rozpoznawania.
Następnie taki algorytm nadzorowany porównuje to, co dostanie na wejściu z tym, co pojawia się na wyjściu oraz zdjęcie z etykietą gatunku zwierzęcia. W końcu nauczy się rozpoznawać określony gatunek zwierzęcia na nowych zdjęciach, które zostaną mu „pokazane”.
Nienadzorowane uczenie maszynowe
Nienadzorowane algorytmy ML są dziś jak filtry SPAM-u. Pierwsze takie filtry definiowane przez administratorów szukały określonych słów w wiadomościach e-mail, aby zrozumieć SPAM. Teraz to niemożliwe, więc dobrze sprawdzają się algorytmy nienadzorowane. Nienadzorowany algorytm ML otrzymuje wiadomości e-mail, które nie zostały oznakowane, aby rozpocząć wyszukiwanie wzorców. Kiedy je wykryje, nauczy się, jak wygląda SPAM i będzie go identyfikować w środowisku produkcyjnym.

Techniki machine learning (uczenia maszynowego, ML)
Techniki ML rozwiązują problemy. Jedną z nich wybiera się na podstawie problemu, który trzeba rozwiązać. Oto sześć typowych.
Technika regresji
Za pomocą regresji można przewidywać ceny na rynku nieruchomości lub określić optymalną cenę łopaty do śniegu w Minnesocie w grudniu. Regresja opiera się na zasadzie, że choć ceny mogą się wahać, zawsze wracają do pewnej wartości średniej. Mimo że z czasem ceny domów rosną, istnieje średnia cena, która zawsze będzie się powtarzać. Aby odkryć średnią na podstawie zmian cen w czasie, można je nanieść na wykres. Czerwona linia wykresu pnąca się w górę umożliwia formułowanie prognoz na przyszłość.
Klasyfikacja
Klasyfikacja służy do grupowania danych w znane kategorie. Można na przykład szukać takich osób, które prawdopodobnie zostaną dobrymi klientami (takimi, którzy zawsze wracają i wydają więcej pieniędzy) lub prawdopodobnie zmienią miejsce robienia zakupów. Jeśli potrafisz spojrzeć wstecz i znaleźć czynniki prognostyczne dla każdej klasyfikacji klientów, zastosujesz je do obecnych klientów i przewidujesz, do której grupy będą oni należeć. Dzięki temu będziesz w stanie prowadzić skuteczniejsze działania marketingowe i potencjalnie przekształcić klienta, który może stać się doskonałym stałym klientem. To jest dobry przykład ML nadzorowanego.
Grupowanie
W odróżnieniu od klasyfikacji, technika grupowania należy do kategorii ML nienadzorowanego. W przypadku grupowania system znajdzie sposób na podzielenie na grupy danych, których Ty nie wiesz jak pogrupować. Ten rodzaj ML doskonale sprawdza się w analizie obrazów medycznych i media społecznościowych oraz w wyszukiwaniu anomalii.
Google wykorzystuje grupowanie do generalizacji, kompresji danych i zachowywania prywatności w produktach, na przykład filmach na YouTube, aplikacjach w sklepie Play i utworach muzycznych.
Wykrywanie anomalii
Wykrywanie anomalii stosuje się w celu znalezienia nietypowych obiektów, na przykład czarnej owcy w stadzie. Ich znalezienie w ogromnej masie danych jest niemożliwe dla człowieka. Jeśli natomiast badacz wprowadzi do algorytmu wyszukiwania anomalii dane rozliczeniowe z systemu medycznego wielu szpitali, ten znajdzie sposób na ich pogrupowanie. Dzięki temu może wykryć anomalie będące oznakami oszustwa.
Analiza koszyka rynkowego
Logika analizy koszyka rynkowego umożliwia formułowanie prognoz. Prosty przykład: jeśli klienci włożą do swojego koszyka mieloną wołowinę, pomidory i taco, to można przewidywać, że dołożą do tego jeszcze ser i śmietanę. Na podstawie takich prognoz można stymulować dodatkową sprzedaż przez podsuwanie klientom sklepów internetowych atrakcyjnych propozycji zakupu produktów, o których mogliby zapomnieć lub można grupować produkty w sklepie.
Z pomocą tej techniki dwóch profesorów z MIT odkryło „zwiastuny klapy”. Okazało się, że niektórzy klienci lubią kupować produkty, które są skazane na porażkę. Dzięki dostrzeżeniu ich obecności wiesz, czy kontynuować sprzedaż danego produktu oraz jakie działania promocyjne wdrożyć, aby zmaksymalizować sprzedaż w odpowiedniej grupie klientów.
Szeregi czasowe
Dane w postaci szeregów czasowych powszechnie gromadzą noszone przez nas na nadgarstkach monitory sprawności. Zapisują liczbę uderzeń serca na minutę, liczbę kroków robionych na minutę lub godzinę, a niektóre z nich mierzą już nawet saturację. Na podstawie takich danych można przewidzieć, kiedy ktoś będzie biegać. Można by było też zbierać dane maszyn, na przykład na temat poziomu wibracji, natężenia hałasu i ciśnienia, aby przewidywać awarie.
Algorytmy machine learning
Skoro ML ma uczyć się na podstawie danych, to jak stworzyć algorytm do nauki i wyszukiwania statystycznie istotnych danych? Algorytmy ML wspierają procesy ML nadzorowanego, nienadzorowanego i wzmocnionego.
Specjaliści od przetwarzania danych piszą algorytmy, które umożliwiają maszynom naukę lub znajdowanie istotnych danych.
Przyjrzymy się paru najczęściej używanym algorytmom tego typu. Oto pięć najpopularniejszych algorytmów ML.
- Algorytmy regresji liniowej ustalają relacje przez umieszczenie na wykresie niezależnych i zależnych zmiennych oraz nakreślenie prostej linii wyznaczającej średnią lub trend. Słownik Merriam-Webster definiuje regresję jako „funkcję zwracającą wartość średnią losowej zmiennej pod warunkiem, że jedna lub więcej niezależnych zmiennych ma określone wartości”." Ta definicja odnosi się także do regresji logistycznej.
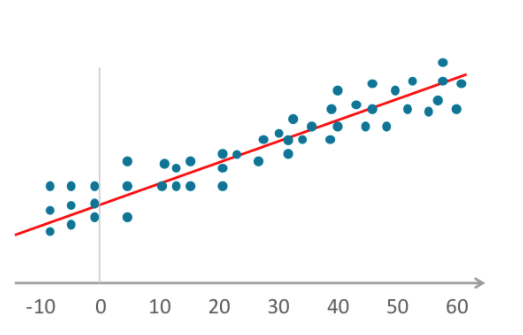
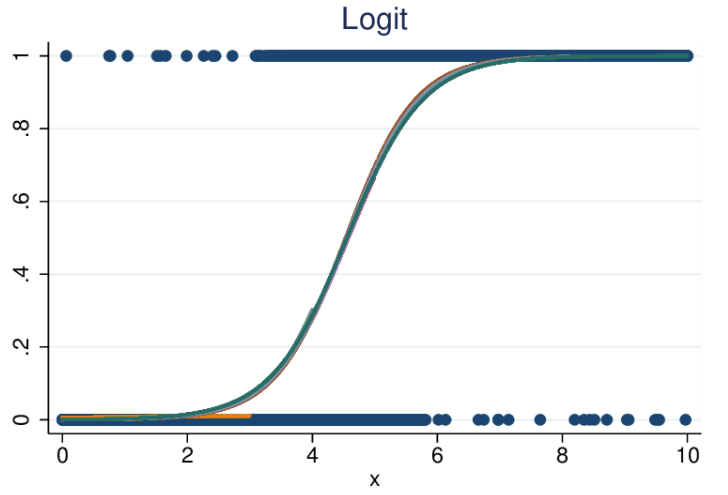
- Regresja logistyczna, podobnie jak liniowa, także umieszcza zmienne na wykresie, ale nie tworzą one linii prostej, tylko o kształcie esowatym.
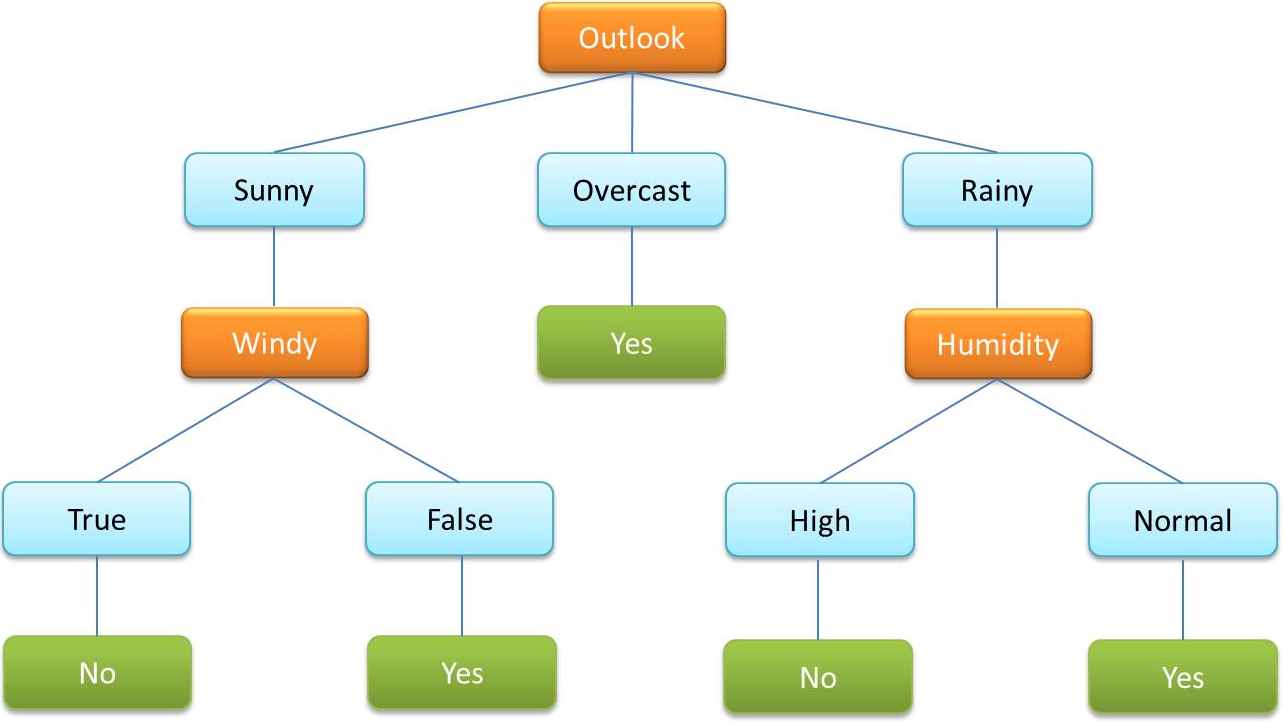
- Bardzo często używanym rodzajem algorytmu w nadzorowanym ML jest drzewo decyzyjne. Z jego pomocą można dokonać klasyfikacji danych na podstawie zmiennych kategorialnych i ciągłych.
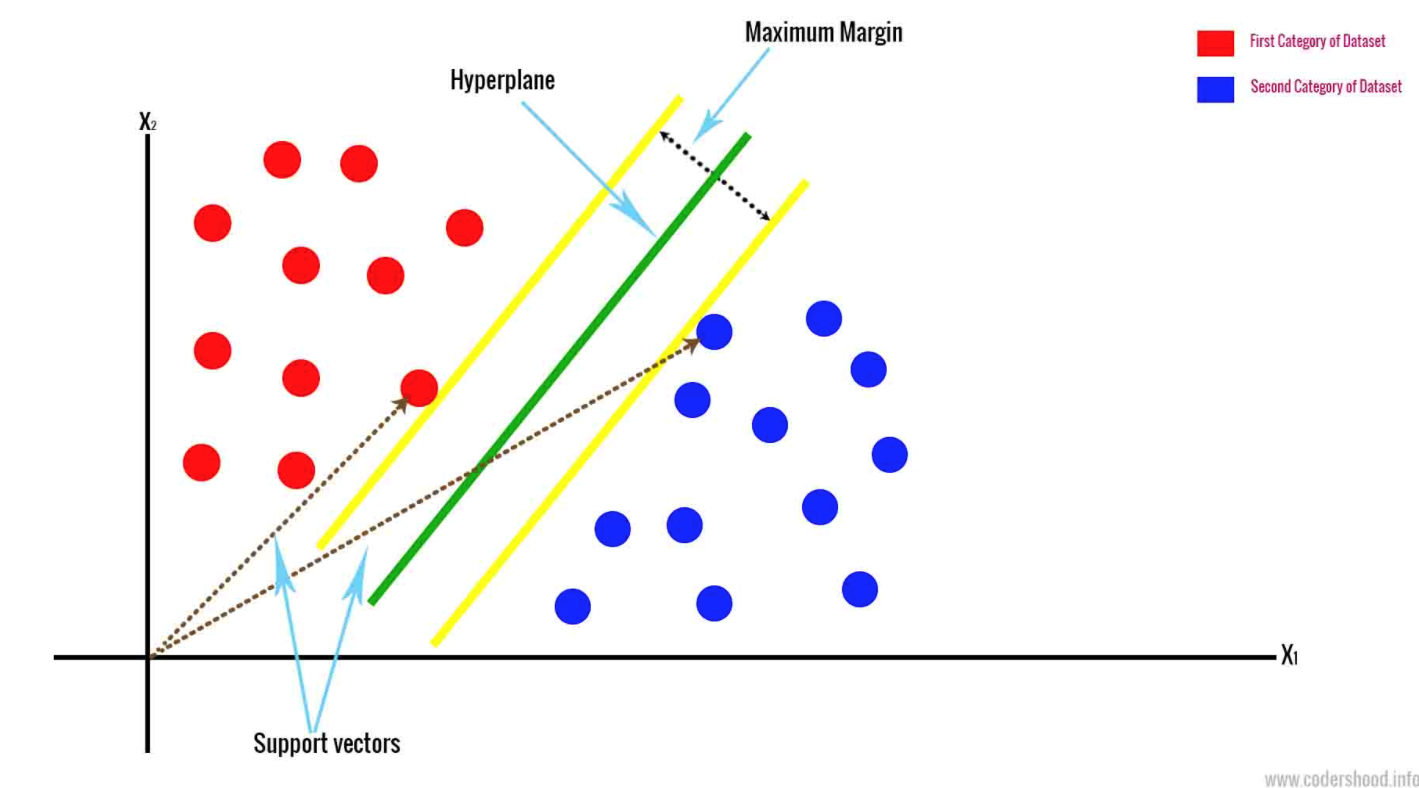
- Maszyna wektorów nośnych wyznacza hiperpłaszczyznę na podstawie dwóch najbardziej zbliżonych do siebie punktów danych. To pozwala na rozdzielenie danych z maksymalnym marginesem przykładów należących do dwóch klas. Klasyfikacja danych odbywa się na podstawie przestrzeni n-wymiarowej. Parametr n reprezentuje liczbę posiadanych przez Ciebie różnych cech.
- Naiwny klasyfikator bayesowski oblicza prawdopodobieństwo wystąpienia określonego wyniku. Jest bardzo skuteczny i przewyższa efektywnością bardziej zaawansowane modele klasyfikacji. Naiwny klasyfikator bayesowski rozumie, że jakakolwiek dana cecha nie jest powiązana z obecnością innych określonych cech.
Modele uczenia maszynowego (machine learning, ML)
Z połączenia typu ML (nadzorowane, nienadzorowane itd.), technik i algorytmów powstaje wyszkolony plik. Można do niego wprowadzać nowe dane, aby rozpoznawał wzorce i formułował prognozy lub podejmował decyzje biznesowe, związane z zarządzaniem bądź odnoszące się do klientów.
Najlepsze języki programowania do uczenia maszynowego (machine learning)
Języki programowania służą do pisania instrukcji nauki systemów machine learning. Każdy z nich skupia społeczność użytkowników, od których można się wiele nauczyć. I każdy zawiera specjalne biblioteki do uczenia maszynowego (machine learning).
Oto 10 najpopularniejszych z nich według portalu GitHub. 10 najpopularniejszych języków wg ankiety z 2019 r.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala – wykorzystywany do pracy z dużymi zbiorami danych
Machine learning w Pythonie
Poniżej znajduje się garść podstawowych informacji o języku Python, który cieszy się największą popularnością w ML.
Python to interpretowany obiektowy język programowania open-source, którego nazwa pochodzi od Monty Pythona. Jako że jest to język interpretowany, jego kod źródłowy przed wykonaniem przez maszynę wirtualną jest konwertowany na kod bajtowy.
Python ma kilka cech, które zapewniły mu popularność w dziedzinie ML.
- Jedną z nich jest duży zbiór zaawansowanych pakietów dostępnych od ręki. Wiele spośród nich, na przykład numpy, scipy i panda, jest specjalnie przeznaczonych do zastosowań w machine learning.
- Łatwe i szybkie tworzenie prototypów.
- Istnieje szeroki wybór narzędzi umożliwiających współpracę.
- Kiedy specjalista od obróbki danych przechodzi od etapu ekstrakcji do modelowania, a potem aktualizacji opracowanych rozwiązań ML, język Python nadal jest najlepszym wyborem. Analityk danych nie musi zmieniać języka w trakcie pracy.
Uczenie maszynowe i cyberbezpieczeństwo
Pojawienie się oprogramowania ransomware sprawiło, że uczenie maszynowe stało się najistotniejszym punktem, biorąc pod uwagę możliwość wykrywania ataków ransomware w czasie zera.
Ewolucja to gra typu malware. Kilka lat temu atakujący wielokrotnie korzystali z tego samego złośliwego oprogramowania o tej samej wartości hash — odcisku palca złośliwego oprogramowania — zanim zaparkowali je na stałe. Obecnie atakujący wykorzystują niektóre rodzaje złośliwego oprogramowania, które często generują unikalne wartości skrótu. Na przykład ransomware Cerber może wygenerować nowy wariant złośliwego oprogramowania — z nową wartością hash co 15 sekund. Oznacza to, że złośliwe oprogramowanie jest używane tylko raz, co sprawia, że bardzo trudno je wykryć przy użyciu starych technik. Wprowadź machine learning. Dzięki możliwości uczenia maszynowego w zakresie przechwytywania takich formularzy złośliwego oprogramowania w oparciu o typ rodziny jest to bez wątpienia logiczne i strategiczne narzędzie cyberbezpieczeństwa.
Algorytmy uczenia maszynowego są w stanie dokładnie przewidywać na podstawie wcześniejszych doświadczeń ze złośliwymi programami i zagrożeniami opartymi na plikach. Analizując miliony znanych rodzajów zagrożeń cybernetycznych, uczenie maszynowe jest w stanie zidentyfikować zupełnie nowe lub jawne ataki, które dzielą podobieństwa ze znanymi.
Od przewidywania nowego złośliwego oprogramowania w oparciu o dane historyczne po skuteczne śledzenie zagrożeń w celu ich zablokowania, uczenie maszynowe pokazuje skuteczność w pomaganiu rozwiązaniom z zakresu cyberbezpieczeństwa w poprawie ogólnej postawy cyberbezpieczeństwa.
I choć uczenie maszynowe stało się ostatnio głównym punktem dyskusji w dziedzinie cyberbezpieczeństwa, jest już zintegrowanym narzędziem rozwiązań zabezpieczających Trend Micro od 2005 r. — na długo przed tym, jak rozpoczęło się ten zawirowanie.
Gdzie mogę uzyskać pomoc w lepszym wykorzystaniu uczenia maszynowego (ML)?
Uczenie maszynowe może znacznie zwiększyć zdolność platformy cyberbezpieczeństwa do ochrony organizacji, pracowników i partnerów, umożliwiając szybsze, inteligentniejsze i bardziej proaktywne wykrywanie zagrożeń oraz reagowanie na nie.
Trend Vision One™ to jedyna platforma cyberbezpieczeństwa dla przedsiębiorstw oparta na sztucznej inteligencji, która centralizuje zarządzanie ryzykiem cybernetycznym, operacje zabezpieczeń i solidną ochronę warstwową. To kompleksowe podejście pomaga przewidywać zagrożenia i zapobiegać im, przyspieszając proaktywne wyniki w zakresie bezpieczeństwa w całym przedsiębiorstwie cyfrowym. Wykorzystując duże zbiory danych zabezpieczeń, zaawansowaną analizę behawioralną i modele wykrywania anomalii, Trend Vision One pomaga identyfikować znane i wcześniej niewidoczne zagrożenia, w tym luki zero-day i ukierunkowane kampanie phishingowe.


Joe Lee jest wiceprezesem ds. zarządzania produktami w Trend Micro, gdzie kieruje globalną strategią i rozwojem produktów w zakresie rozwiązań bezpieczeństwa poczty elektronicznej i sieci dla przedsiębiorstw.
Często zadawane pytania (FAQ)
Co oznacza machine learning?
Uczenie maszynowe jest podzbiorem sztucznej inteligencji (AI), która umożliwia systemom komputerowym naśladowanie sposobu podejmowania złożonych decyzji i uczenia się na podstawie doświadczenia.
Czym jest machine learning w prosty sposób?
Uczenie maszynowe to rodzaj sztucznej inteligencji, który umożliwia komputerom uczenie się na podstawie danych i poprawę wydajności w miarę upływu czasu, bez konieczności wyraźnego programowania dla każdego zadania.
Jaki jest przykład uczenia maszynowego?
Przykładem uczenia maszynowego są technologie rozpoznawania twarzy, w ramach których system komputerowy uczy się rozpoznawać sygnały wizualne, aby ostatecznie zidentyfikować ludzkie twarze.
Jakie są 4 rodzaje uczenia maszynowego?
Cztery główne rodzaje uczenia maszynowego (ML) to uczenie nadzorowane, uczenie nienadzorowane, uczenie półnadzorowane i uczenie się wzmacniające.
Jaka jest różnica między AI a ML?
Sztuczna inteligencja (AI) odnosi się do systemów zaprojektowanych w celu naśladowania ludzkiej inteligencji. Uczenie maszynowe (ML) to podzbiór sztucznej inteligencji, który znajduje wzorce w danych w celu poprawy wydajności systemu.
Czy ChatGPT LLM czy generacyjna sztuczna inteligencja?
ChatGPT jest przykładem zarówno modelu LLM (dużego języka), jak i generacyjnego AI (GenAI).
Czy jest to chatbot AI czy ML?
Chatboty są zazwyczaj opracowywane przy użyciu technologii sztucznej inteligencji (AI) i uczenia maszynowego (ML).
Czym jest AI, ale nie ML?
Niektóre systemy AI nie polegają na machine learning, takie jak oparte na regułach systemy eksperckie, systemy rozumowania symbolicznego i wstępnie zaprogramowane algorytmy, które są zgodne ze stałymi regułami.
Co jest lepsze, AI lub ML?
W zależności od potrzeb żadna z tych opcji nie jest „lepsza”. ML to podzbiór sztucznej inteligencji, który umożliwia systemom komputerowym uczenie się na podstawie doświadczenia bez nadzoru człowieka.
Czy powinienem najpierw nauczyć się AI lub ML?
Zależy to od Twoich zainteresowań i celów. Jednak większość ludzi uczy się najpierw sztucznej inteligencji, a dopiero potem specjalizuje się w podzbiorach technologii sztucznej inteligencji, takich jak machine learning (ML).
Powiązane artykuły
10 najlepszych środków ograniczających ryzyko dla LLM i aplikacji Gen AI w 2025 r.
Zarządzanie nowymi zagrożeniami dla bezpieczeństwa publicznego
Jak daleko mogą nas zaprowadzić międzynarodowe standardy?
Jak napisać generatywną politykę cyberbezpieczeństwa AI?
Złośliwe ataki z wykorzystaniem sztucznej inteligencji wśród największych zagrożeń
Rosnące zagrożenie związane z Deepfake tożsamości