
Una forma de inteligencia artificial (IA) que permite a los sistemas aprender patrones de los datos y mejorar su rendimiento en las tareas con el tiempo sin que se programen explícitamente.
Tabla de contenido
Significado de Machine Learning
El hecho de tener equipos que sepan qué hacer sin que nadie se lo diga explícitamente es algo que ha ocupado la imaginación de las personas durante mucho tiempo.
La idea de un coche en el que pueda montarse (en el asiento del conductor, por supuesto) y que se ocupe de toda la conducción, que identifique a los peatones y a los baches, y que responda de forma rápida y eficiente a los cambios en el entorno para llevarlo de forma segura a su destino sería una forma de machine learning (ML) puesta en práctica.
¿Cómo funciona? Vamos a comenzar analizando solamente los datos empresariales.
El ML es un tipo de IA que permite que las empresas aprendan de cantidades masivas de datos y les den sentido. Pongamos como ejemplo a Twitter. Según Internet Live Stats, los usuarios de Twitter envían aproximadamente 500 millones de tweets a diario, lo que equivale a un total de aproximadamente 200 mil millones de tweets al año. No es humanamente posible analizar, clasificar, ordenar, descubrir y predecir nada con ese número de tweets.
Cómo el machine learning puede ayudar a las empresas
Machine Learning ayuda a proteger a las empresas de las ciberamenazas. Sin embargo, funciona mejor como parte de una solución de seguridad multicapa.
El machine learning requiere una considerable carga de trabajo por parte de las empresas para que estas obtengan información valiosa. Para sacar el máximo provecho al ML debe tener datos limpios y tener claro qué desea saber sobre ellos. Después podrá seleccionar el modelo y algoritmo que más beneficien a su empresa. El ML no es un proceso simple ni sencillo. Para que tenga éxito es necesario un trabajo diligente.
El ML tiene un ciclo de vida:
- Comprensión. Por qué está cambiando al ML y qué es lo que está buscando hacer o descubrir.
- Limpieza y recopilación de datos. Tiene la cantidad de datos que necesita y están lo suficientemente limpios como para ofrecerle la información que usted necesita.
- Selección de características. Implica determinar los datos que necesita para alimentar el ML y crear el correspondiente modelo. Dependiendo del tipo de algoritmo que se utilice, hay diferentes métodos disponibles para ayudarle a seleccionar características. Por ejemplo, imagine que va a utilizar un algoritmo de árbol de decisión. En ese caso la herramienta de modelado o analista puede aplicar un «marcador de interés», es decir, columnas en una base de datos para determinar si esos datos deberían utilizarse para crear su modelo.
- Selección del modelo. La elección del archivo (modelo) que se ha entrenado para procesar y buscar ciertas cosas en los datos. Se le proporciona un algoritmo a un modelo para que trabaje con él y los datos de prueba combinarán ambos y sacarán una conclusión.
- Entrenamiento y ajustes. Las conclusiones que el modelo ha encontrado para garantizar que usted consiga respuestas a sus preguntas.
- Evaluación del modelo y el algoritmo para determinar si está listo para utilizarse o si tiene que retroceder algunos pasos y refinar su modelo, característica, algoritmo o datos para conseguir sus objetivos.
- Implementación del modelo entrenado en la producción.
- Revisión del resultado del modelo existente en la producción

Aplicaciones de machine learning
El machine learning es una forma de que las empresas comprendan sus datos y aprendan de ellos. Una empresa puede utilizarlo para un gran número de subcampos. El caso de uso depende de si una empresa está intentando mejorar las ventas, proporcionar una característica de búsqueda, integrar comandos de voz en su producto o crear un vehículo autónomo.
Subcampos de machine learning
El ML tiene una fantástica variedad de usos en las empresas de hoy en día y con el tiempo solo puede aumentar y mejorar. Los subcampos del ML incluyen recomendaciones de productos y redes sociales, reconocimiento de imagen, diagnóstico de salud, traducción de idiomas, reconocimiento de voz y minería de datos, por mencionar algunos.
Las plataformas de redes sociales como Facebook, Instagram o LinkedIn utilizan el ML para sugerir qué páginas seguir o a qué grupos unirse según las publicaciones que le hayan gustado. Hacen falta datos históricos sobre lo que les ha gustado a los demás o qué publicaciones son similares a aquellas que le han gustado a usted para realizar esas sugerencias o para añadirlas a su actividad.
También es posible utilizar el ML en un sitio de e-commerce para realizar recomendaciones según adquisiciones anteriores, sus búsquedas y las acciones de otros usuarios similares a usted.
Un uso importante del ML hoy en día es el reconocimiento de imagen. Las plataformas de las redes sociales han recomendado etiquetar a las personas en sus fotos con base en el ML. La policía ha podido utilizarla para buscar a sospechosos en fotografías o en vídeos. Debido a la gran cantidad de cámaras instaladas en los aeropuertos, tiendas y portales, es posible averiguar quién ha cometido un crimen o a dónde ha ido el criminal.
Los diagnósticos de salud también son un buen uso del ML. Después de un suceso como un ataque al corazón, es posible retroceder y ver señales de alarma que se pasaron por alto. Un sistema utilizado por médicos u hospitales podría ser utilizar historias clínicas del pasado y aprender a ver las conexiones desde el inicio (comportamiento, resultado de pruebas o síntomas) hasta el resultado (p. ej.: un ataque al corazón). A continuación, cuando el médico introduzca sus notas y los resultados de las pruebas en el sistema en el futuro, la máquina podrá detectar síntomas de un ataque al corazón de una forma mucho más fiable que los humanos para que así tanto paciente como médico puedan realizar cambios y evitarlo.
La traducción de idiomas en las páginas web o en las aplicaciones para plataformas móviles es otro ejemplo de ML. Algunas aplicaciones lo hacen mejor que otras, lo cual tiene que ver con los algoritmos, la técnica y el modelo de ML que utilizan.
Un uso diario del ML hoy en día se puede ver en las operaciones bancarias y en las tarjetas de crédito. Hay signos de fraude que el ML puede detectar rápidamente y que a los humanos les costaría un largo tiempo descubrir, si es que llegan a hacerlo. La gran cantidad de transacciones que se han examinado y catalogado (siendo fraude o no) puede permitir al ML detectar un fraude en el futuro en una sola transacción. La minería de datos es un ML fantástico para hacer esto.
Minería de datos
La minería de datos es un tipo de ML que analiza los datos para realizar predicciones o para descubrir patrones en grandes cantidades de datos. El término es un poco confuso ya que no es necesario que nadie, sea un agente malicioso o un empleado, rebusque entre sus datos para que encuentre algún dato que sea útil. En su lugar, el proceso hace que el descubrimiento de patrones sea útil para tomar decisiones en el futuro.
Pongamos, por ejemplo, una empresa de tarjetas de crédito. Si usted tiene una tarjeta de crédito, su banco seguramente le ha avisado de una actividad sospechosa con su tarjeta en alguna ocasión. ¿Cómo detecta el banco ese tipo de actividad tan rápido y envía una alerta prácticamente instantánea? Lo que permite esta protección frente al fraude es una minería de datos continua. A principios de 2020 había más de 1100 millones de tarjetas emitidas solamente en EE. UU. El número de transacciones desde esas tarjetas produce diferentes datos para la minería, búsqueda de patrones y el aprendizaje, y así identificar transacciones sospechosas en el futuro.
Aprendizaje profundo
El aprendizaje profundo es un tipo de ML específico que se basa en redes neuronales. Una red neuronal funciona para emular el funcionamiento de las neuronas en un cerebro humano y así tomar una decisión o entender algo. Por ejemplo, un niño de seis años puede mirar un rostro y distinguir entre su madre y el guardia de cruce porque el cerebro analiza muchos detalles rápidamente (color de pelo, rasgos faciales, cicatrices, etc.), todo en un solo pestañeo. El machine learning reproduce esto con el aprendizaje profundo.
Una red neuronal tiene entre 3 y 5 capas: una capa de entrada, entre una y tres capas ocultas, y una capa de salida. Las capas ocultas toman las decisiones una por una para trabajar hacia la capa de salida o la conclusión. ¿Qué color de pelo? ¿Qué color de ojos? ¿Hay alguna cicatriz? Como las capas aumentan hasta ser cientos de ellas, se llama aprendizaje profundo.
Tipos de machine learning
Existen fundamentalmente cuatro tipos de algoritmos de machine learning: supervisados, semisupervisados, no supervisados y reforzados. Los expertos en ML creen que aproximadamente un 70 % de los algoritmos de ML que se utilizan hoy en día son supervisados. Trabajan con conjuntos de datos catalogados o conocidos (por ejemplo, fotografías de perros y gatos). Estos dos tipos de animales son conocidos, así que los administradores pueden catalogar las fotografías antes de dárselas al algoritmo.
Los algoritmos de ML no supervisado aprenden de conjuntos de datos desconocidos. Por ejemplo, los vídeos de TikTok. Hay tanta cantidad de vídeos de tantos temas diferentes que es imposible entrenar a un algoritmo a partir de ellos de manera supervisada, los datos aún no se han catalogado.
Los algoritmos de ML semisupervisados se entrenan inicialmente con un pequeño conjunto de datos conocido y catalogado. A continuación, se aplica a un conjunto de datos más grande sin catalogar para continuar su entrenamiento.
Los algoritmos de ML de refuerzo no están entrenados inicialmente. Aprenden del ensayo y error sobre la marcha. Piense en un robot que está aprendiendo a hacerse camino sobre un montón de rocas. Cada vez que falla, aprende lo que no funciona y altera su comportamiento hasta que tiene éxito. Piense en el entrenamiento de un perro y en el uso de los premios para enseñar diferentes órdenes. Gracias a un refuerzo positivo el perro continuará obedeciendo las órdenes y cambiará aquel comportamiento que no le proporcione una respuesta favorable.
Machine learning supervisado frente a no supervisado
Machine learning supervisado
Utiliza conjuntos de datos clasificados, establecidos y conocidos para encontrar patrones. Ampliemos la idea anterior de las imágenes de perros y gatos. Usted podría tener un conjunto de datos gigante lleno de cientos de diferentes animales en millones de imágenes. Como conocemos los tipos de animales, estos se podrían haber agrupado y catalogado antes de proporcionárselos al algoritmo de ML supervisado para que este aprenda a comprender.
Ahora el algoritmo supervisado compara la entrada con la salida y la fotografía con la clasificación del tipo de animal. Con el tiempo aprenderá a reconocer un tipo concreto de animal en las fotografías nuevas que se encuentre.
Machine learning no supervisado
Los algoritmos de ML no supervisado son como los filtros de spam de hoy en día. Al principio los administradores podían programar los filtros de spam para que buscase palabras concretas en un email para comprender el spam. Esto ya no es posible, por lo que el algoritmo no supervisado funciona bien aquí. El algoritmo de ML no supervisado se compone de emails que no se han catalogado para empezar a buscar patrones. A medida que va encontrando esos patrones aprenderá cuál es el aspecto del spam y cómo identificarlo en el entorno de la producción.

Técnicas de machine learning
Las técnicas de ML solucionan problemas. Dependiendo del problema al que se enfrente, elija una técnica de ML concreta. Aquí hay seis comunes.
La técnica de regresión
La regresión se puede utilizar para predecir los precios de mercado de la vivienda o para determinar el mejor precio de venta de una pala para la nieve en Minnesota en diciembre. La regresión dice que, aunque los precios fluctúen, siempre regresarán a su precio medio, aunque con el tiempo los precios de las viviendas estén aumentando, hay una media que siempre volverá a suceder. Puede trazar los precios a lo largo del tiempo en un gráfico y encontrar la media a medida que pasa el tiempo. Si la línea roja sigue apareciendo en la gráfica, será posible hacer predicciones futuras.
Clasificación
La clasificación se utiliza para agrupar los datos en categorías conocidas. Puede estar buscando clientes que previsiblemente sean buenos clientes (siempre vuelven y se gastan más dinero) o que previsiblemente vayan a empezar a comprar en otro sitio. Si puede mirar hacia en el tiempo y encontrar predictores para cada clasificación de clientes, lo aplicará a los clientes actuales y predecirá qué grupo encajará. Entonces podrá comercializar de forma más efectiva y posiblemente convertir al cliente que potencialmente conducirá a un excelente cliente recurrente. Este es un buen ejemplo de un ML supervisado.
Agrupación
A diferencia de la técnica de clasificación, la agrupación es un ML no supervisado. En la agrupación, el sistema encontrará la forma de agrupar los datos que usted no sabe cómo agrupar. Este tipo de ML es excelente para analizar imágenes médicas, para analizar redes sociales o para buscar anomalías.
Google utiliza la agrupación para la generalización, la compresión de datos y la preservación de la privacidad en productos como los vídeos de YouTube, las aplicaciones de Play y las pistas de Music.
Detección de anomalías
La detección de anomalías se utiliza cuando está buscando valores atípicos, como detectar la oveja negra en un rebaño. Cuando buscamos en una cantidad masiva de datos, es imposible que un humano encuentre este tipo de anomalías. Pero, por ejemplo, si un científico de datos alimentó los datos de un sistema de facturación médica de diferentes hospitales, la detección de anomalías encontraría una forma de agrupar la facturación. Podría descubrir un conjunto de valores atípicos que resulten ser donde ocurren los fraudes.
Análisis de la cesta de la compra
La lógica de los análisis de la cesta de la compra permite predicciones futuras. Un ejemplo sencillo: si los clientes añaden carne picada, tomates y tacos a su cesta, usted podría predecir que añadirán queso y crema agria. Estas predicciones se pueden utilizar para generar ventas adicionales al realizar sugerencias valiosas para los compradores online sobre los productos que podrían haber olvidado o para ayudar a agrupar los productos en una tienda.
Dos profesores del MIT utilizaron este enfoque para descubrir el «presagio del fallo». Al parecer, a algunos clientes les gustan los productos que fallan. Si puede detectarlos, puede determinar si continuar vendiéndole un producto y qué tipo de marketing aplicar para aumentar las ventas con los clientes adecuados.
Datos de series temporales
Los datos de series temporales se suelen recopilar sobre muchos de nosotros gracias a los monitores de aptitud física de nuestras muñecas. Puede recopilar las pulsaciones por minuto, cuántos pasos damos por minuto u hora y algunos ahora incluso miden la saturación de oxígeno a lo largo del tiempo. Con estos datos podría ser posible predecir cuándo alguien va a ir a correr en el futuro. También sería posible recopilar datos sobre maquinaria y predecir el fallo debido a los datos con base en el tiempo sobre el nivel de vibración, el nivel de los decibelios de ruido y la presión.
Algoritmos de machine learning
Si se supone que el ML aprende de los datos, ¿cómo diseña un algoritmo para aprender y encontrar los datos estadísticamente importantes? Los algoritmos de ML admiten el proceso del ML de refuerzo, no supervisado o supervisado.
Los ingenieros de datos escriben fragmentos de código que son algoritmos que permiten que un equipo aprenda o encuentre importancia en los datos
Vamos a ver algunos algoritmos concretos que son lo más comunes. Aquí tenemos los 5 mejores en uso hoy en día.
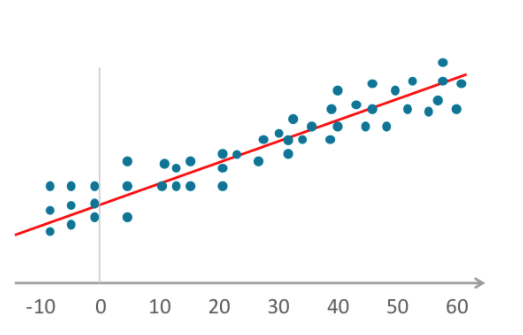
- Los algoritmos de regresión lineal establecen una relación al ajustar variables dependientes e independientes en un gráfico y trazar una línea recta para la media o la tendencia. El Merriam-Webster define la regresión como "una función que produce el valor medio de una variable aleatoria con la condición de que una o más variables independientes tengan valores especificados." Esta definición también se aplica a la regresión logística.
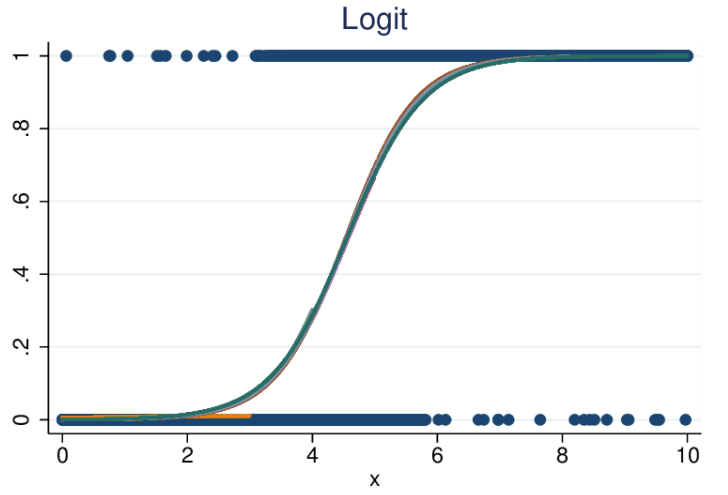
- La regresión logística (también conocida como logit) también ajusta variables en un gráfico, al igual que la regresión lineal, pero la línea no es lineal. Esta línea es una función sigmoide.
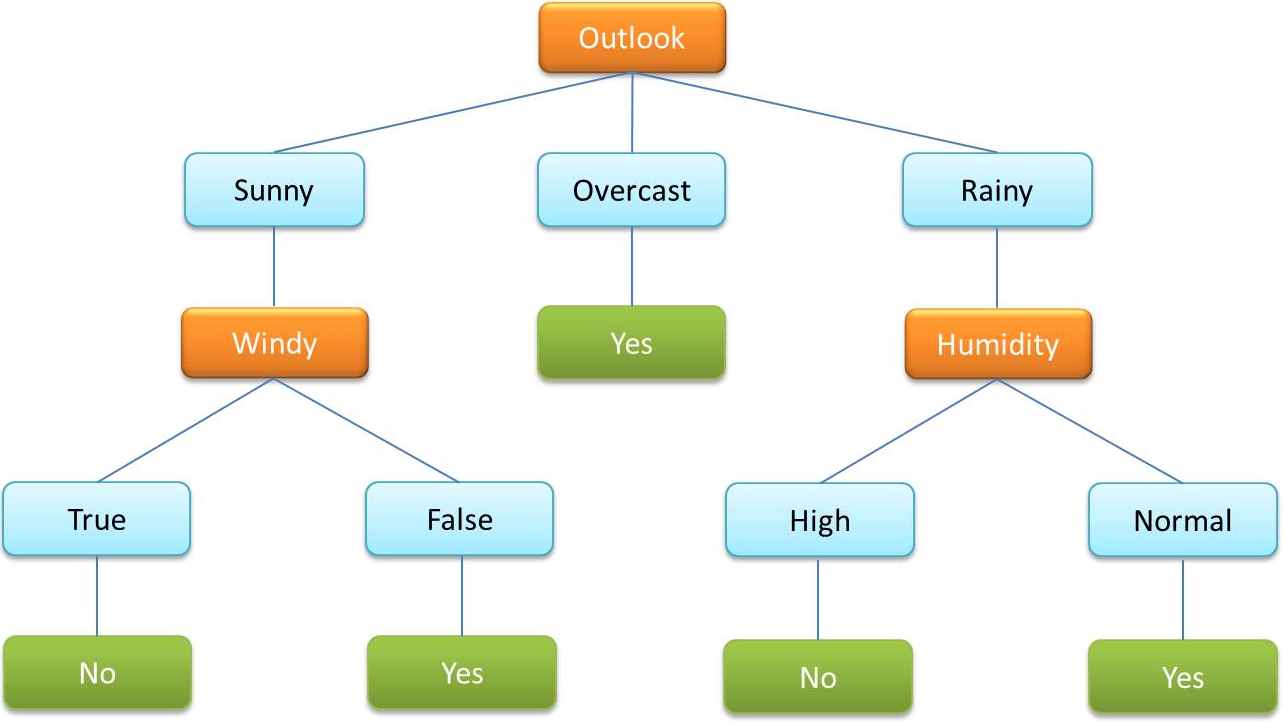
- Un árbol de decisión es un algoritmo utilizado muy comúnmente en el ML supervisado. Se utiliza para clasificar los datos mediante variables continuas y categóricas.
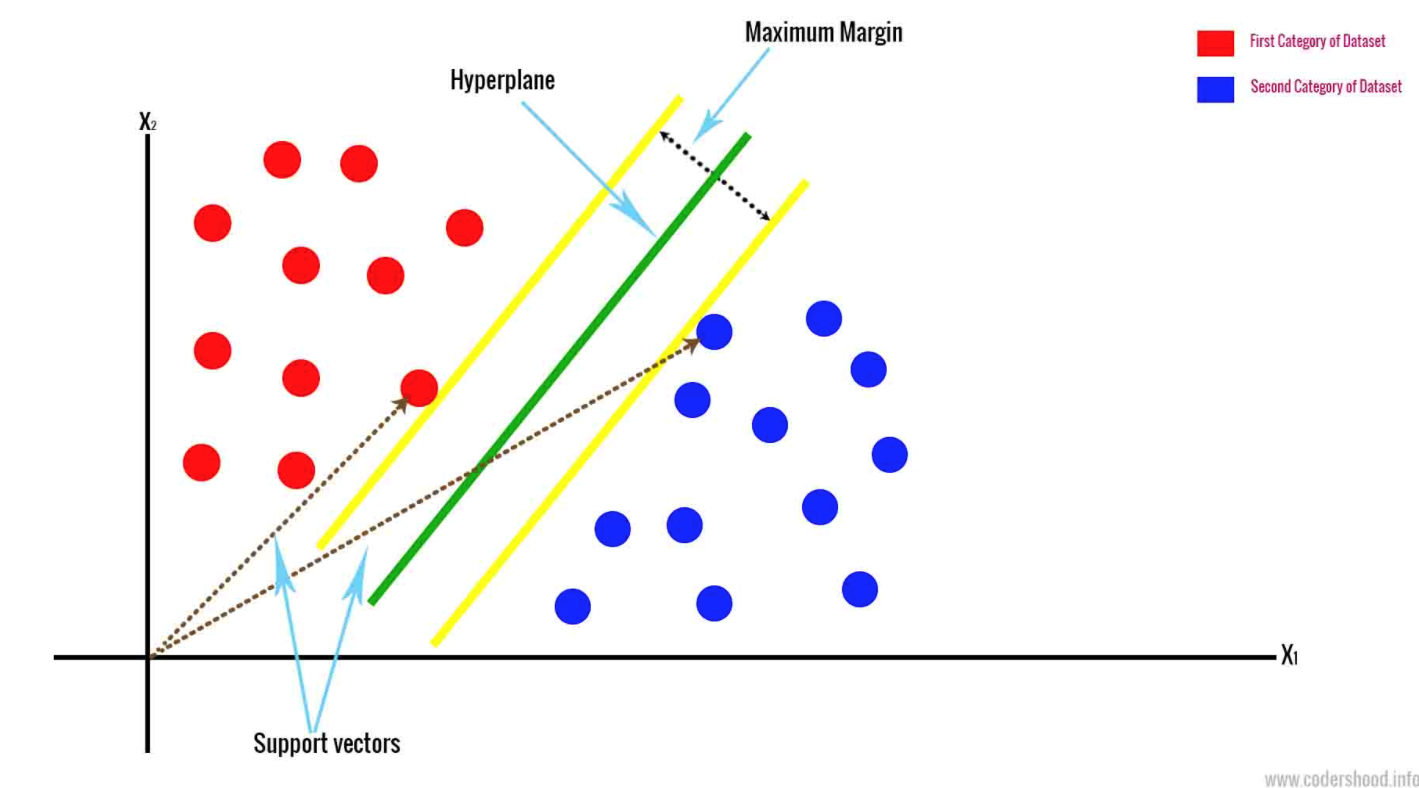
- Una máquina de vectores de soporte dibuja un hiperplano según los puntos de datos más cercanos. Esto separa los datos al marginalizar las clases. Clasifica los datos según un espacio n-dimensional. La N representa el número de las diferentes características que usted tiene.
- Un clasificador de Naïve Bayes calcula la probabilidad de un resultado concreto. Es muy eficaz y consigue mejores resultados que modelos de clasificación más sofisticados. Un clasificador de Naïve Bayes comprenderá que cualquier característica determinada no está relacionada con la presencia de otras características específicas.
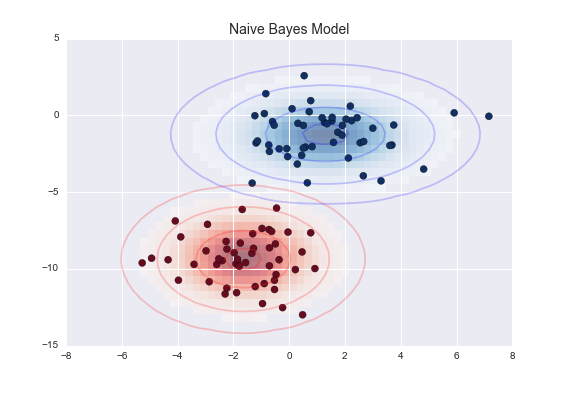
Modelos de machine learning
Tras combinar el tipo de ML (supervisado, no supervisado, etc.), las técnicas y los algoritmos, el resultado es un archivo que se ha entrenado. Ahora a este archivo se le puede proporcionar datos nuevos y será capaz de crear patrones de reconocimiento y realizar predicciones o tomar decisiones para la empresa, el director o el cliente a demanda.
Los mejores lenguajes para el machine learning
Los lenguajes de machine learning son la forma en la que se escriben las instrucciones para que el sistema aprenda. Cada lenguaje tiene una comunidad de usuarios de soporte de los que aprender o para guiar a otros. Hay bibliotecas incluidas en cada lenguaje para el uso del machine learning.
Aquí están los 10 mejores según GitHub Encuesta de los 10 mejores en 2019.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala: un idioma que se está utilizando para las interacciones con el big data
Machine learning con Python
Como Python es el lenguaje de ML más común, aquí hablamos un poco más sobre él.
Python es un lenguaje orientado a objetos, de open source e interpretado que le debe su nombre a los Monty Python. Como es interpretado, se convierte a códigos de bytes antes de que sea ejecutable mediante una máquina virtual de Python.
Hay una variedad de características que hacen que Python sea la opción preferida para el ML.
- Un gran conjunto de potentes paquetes que están disponibles para su uso ahora. Hay paquetes de ML específicos como NumPy, SciPy y Panda.
- Sencillo y rápido hasta el prototipo.
- Hay una variedad de herramientas que permiten colaboración.
- Como un científico de datos se mueve desde la extracción hasta el modelado por completo para actualizar su solución de ML, Python puede seguir siendo el lenguaje de elección. El científico de datos no tiene que cambiar de lenguaje mientras se mueve por el ciclo de vida.
Ciberseguridad y machine learning
La aparición del ransomware ha puesto el machine learning en el centro de atención, dada su capacidad para detectar ataques de ransomware en el momento cero.
La evolución es el juego del malware. Hace unos años, los atacantes utilizaban el mismo malware con el mismo valor hash, la huella dactilar de un malware, varias veces antes de aparcarlo permanentemente. Hoy en día, estos atacantes utilizan algunos tipos de malware que generan valores hash únicos con frecuencia. Por ejemplo, el ransomware Cerber puede generar una nueva variante de malware, con un nuevo valor hash cada 15 segundos. Esto significa que estos malware se utilizan solo una vez, lo que hace que sean extremadamente difíciles de detectar utilizando técnicas antiguas. Introduzca machine learning. Gracias a la capacidad del machine learning para detectar dichos formularios de malware basados en el tipo de familia, sin duda es una herramienta de ciberseguridad lógica y estratégica.
Los algoritmos de machine learning pueden realizar predicciones precisas basadas en la experiencia previa con programas maliciosos y amenazas basadas en archivos. Al analizar millones de diferentes tipos de ciberriesgos conocidos, el machine learning es capaz de identificar ataques nuevos o sin clasificar que comparten similitudes con los conocidos.
Desde la predicción de nuevo malware basado en datos históricos hasta el seguimiento eficaz de amenazas para bloquearlas, el machine learning demuestra su eficacia en ayudar a las soluciones de ciberseguridad a reforzar la postura general de ciberseguridad.
Y aunque el machine learning se ha convertido en un punto de debate importante en ciberseguridad recientemente, ya ha sido una herramienta integrada en las soluciones de seguridad de Trend Micro desde 2005, mucho antes de que comenzara el rumor.
¿Dónde puedo obtener ayuda para utilizar mejor el machine learning (ML)?
El machine learning puede mejorar significativamente la capacidad de una plataforma de ciberseguridad para proteger a su organización, empleados y partners al permitir una detección y respuesta de amenazas más rápida, inteligente y proactiva.
Trend Vision One™ es la única plataforma de ciberseguridad empresarial impulsada por IA que centraliza la gestión de la exposición al riesgo cibernético, las operaciones de seguridad y la sólida protección por capas. Este enfoque integral le ayuda a predecir y prevenir amenazas, acelerando los resultados de seguridad proactivos en todo su patrimonio digital. Al aprovechar los conjuntos de datos de seguridad a gran escala, el análisis de comportamiento avanzado y los modelos de detección de anomalías, Trend Vision One ayuda a identificar amenazas conocidas y no vistas previamente, incluidas vulnerabilidades de día cero y campañas de phishing dirigidas.


Joe Lee es Vice President of Product Management en Trend Micro, donde lidera la estrategia global y el desarrollo de productos para soluciones de seguridad de red y email empresarial.
Preguntas frecuentes (FAQ)
¿Qué significa machine learning?
El machine learning es un subconjunto de la inteligencia artificial (IA) que permite a los sistemas informáticos imitar cómo las mentes humanas toman decisiones complejas y aprenden de la experiencia.
¿Qué es el machine learning en términos sencillos?
El machine learning es un tipo de IA que permite a los ordenadores aprender de los datos y mejorar su rendimiento con el tiempo, sin necesidad de programarse explícitamente para cada tarea.
¿Cuál es un ejemplo de machine learning?
Un ejemplo de machine learning serían las tecnologías de reconocimiento facial, en las que un sistema informático aprende a reconocer entradas visuales para que pueda finalmente identificar caras humanas.
¿Cuáles son los 4 tipos de machine learning?
Los cuatro tipos principales de machine learning (ML) son el aprendizaje supervisado, el aprendizaje no supervisado, el aprendizaje semisupervisado y el aprendizaje de refuerzo.
¿Cuál es la diferencia entre IA y ML?
La inteligencia artificial (IA) se refiere a sistemas diseñados para imitar la inteligencia humana. Machine Learning (ML) es un subconjunto de IA que encuentra patrones en los datos para mejorar el rendimiento del sistema.
¿Es ChatGPT LLM o IA generativa?
ChatGPT es un ejemplo tanto de un LLM (modelo de lenguaje grande) como de IA generativa (GenAI).
¿Es un chatbot IA o ML?
Los chatbots suelen desarrollarse utilizando tecnologías de inteligencia artificial (IA) y machine learning (ML).
¿Qué es la IA pero no el ML?
Algunos sistemas de IA no dependen del machine learning, como los sistemas expertos basados en reglas, los sistemas de razonamiento simbólico y los algoritmos preprogramados que siguen reglas fijas.
¿Cuál es mejor, IA o ML?
Dependiendo de lo que necesite, tampoco es «mejor». ML es un subconjunto de IA que permite a los sistemas informáticos aprender de la experiencia sin supervisión humana.
¿Debo aprender primero la IA o el ML?
Depende de sus intereses y objetivos. Pero la mayoría de las personas aprenden primero la IA antes de especializarse en subconjuntos de tecnología de IA como el machine learning (ML).
Artículos relacionados
Los 10 principales riesgos y mitigaciones de 2025 para aplicaciones de IA de generación y LLM
Gestión de riesgos emergentes para la seguridad pública
¿Hasta dónde nos pueden llevar los estándares internacionales?
Cómo redactar una política de ciberseguridad de IA generativa
Ataques maliciosos mejorados con IA entre los principales riesgos
Aumento de la amenaza de identidades falsas