
La inteligencia artificial (IA) es una tecnología que permite a los ordenadores y máquinas aprender, comprender, crear, resolver problemas, predecir resultados y tomar decisiones.
Índice
¿Qué es la IA?
En el nivel más básico, la IA se refiere a sistemas informáticos o de máquinas que utilizan tecnologías como machine learning (ML), redes neuronales y arquitecturas cognitivas para realizar los tipos de tareas complicadas que antes solo podían realizar los seres humanos.
Esto incluye todo, desde la creación de contenido hasta la planificación, el razonamiento, la comunicación, el aprendizaje de la experiencia y la toma de decisiones complejas. Dicho esto, dado que los sistemas y herramientas de IA son tan amplios y variados, ninguna definición se aplica perfectamente a todos.
Desde que la IA se introdujo por primera vez en la década de 1950, ha transformado casi todos los aspectos de la vida moderna, la sociedad y la tecnología. Gracias a su capacidad para analizar grandes cantidades de datos, comprender patrones y adquirir nuevos conocimientos, la IA se ha convertido en una herramienta indispensable en prácticamente todos los campos de la actividad humana, desde los negocios y el transporte hasta la atención sanitaria y la ciberseguridad.
Entre otras aplicaciones, las organizaciones utilizan IA para:
- Reducir costes
- Impulsar la innovación
- Empodere a los equipos
- Optimice las operaciones
- Acelere la toma de decisiones
- Consolidar y analizar los hallazgos de la investigación
- Proporcionar servicio y asistencia al cliente inmediatos
- Automatice tareas repetitivas
- Ayudar con la generación de ideas
Una breve historia de IA
La idea de una máquina que puede pensar por sí misma se remonta a miles de años. En su contexto moderno, la inteligencia artificial como concepto definido se remonta al año 1950, cuando el matemático y científico informático Alan Turing, creador de la famosa “prueba de recorrido” para determinar si un ordenador puede pensar como un ser humano, publicó su influyente artículo sobre la noción de inteligencia artificial, máquina de computación e inteligencia.
En las décadas desde que apareció el artículo de Turing, la IA ha experimentado una drástica evolución en su alcance y capacidades, impulsada por avances exponenciales en potencia informática, sofisticación algorítmica, disponibilidad de datos y la introducción de tecnologías como machine learning, minería de datos y redes neuronales.
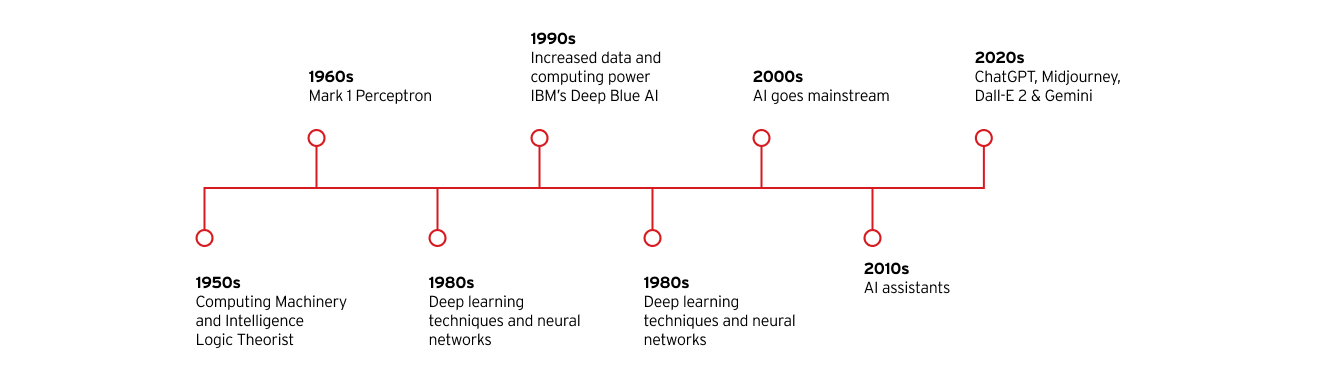
Principales hitos en la evolución de la inteligencia artificial
Año
Hitos
Década de 1950
- Publicación de “Computing Machinery and Intelligence” de Alan Turing
- John McCarthy acuña el término “inteligencia artificial”
- Creación de Logic Theorist, el primer programa informático de IA
Década de 1960
- Creación de Mark 1 Perceptron, el primer ordenador en aprender por prueba y error
Década de los 80
- Crecimiento de técnicas de deep learning y redes neuronales
Década de 1990
- El aumento de los datos y la potencia informática aceleran el crecimiento y la inversión en IA
- La IA Deep Blue de IBM derrota al campeón mundial de ajedrez Garry Kasparov
Década de los 2000
- La IA se generaliza con los lanzamientos del motor de búsqueda impulsado por IA de Google, el motor de recomendación de productos de Amazon, el sistema de reconocimiento facial de Facebook y los primeros coches autónomos
Década de 2010
- Se presentan asistentes de IA como Siri de Apple y Alexa de Amazon
- Google lanza su marco de machine learning de código abierto, TensorFlow
- La red neuronal AlexNet populariza el uso de unidades de procesamiento gráfico (GPU) para entrenar modelos de IA
Década de 2020
- OpenAI lanza la tercera iteración de su muy popular IA generativa (GenAI) de modelo de lenguaje grande (LLM) ChatGPT
- La ola de GenAI continúa con el lanzamiento de generadores de imágenes como Midjourney y Dall-E 2 y chatbots de LLM como Gemini de Google
¿Cómo funciona la IA?
Los sistemas de IA funcionan alimentando o ingiriendo grandes cantidades de datos y utilizando procesos cognitivos similares a los humanos para analizar y evaluar esos datos. Al hacer esto, los sistemas de IA identifican y categorizan patrones y los utilizan para realizar tareas o realizar predicciones sobre futuros resultados sin supervisión o instrucciones humanas directas.
Por ejemplo, un programa de IA generador de imágenes como Midjourney que ha alimentado un gran número de fotografías puede aprender a crear imágenes “originales” basadas en las selecciones dinámicas introducidas por un usuario. Del mismo modo, un chatbot de IA de servicio al cliente formado en grandes volúmenes de texto puede aprender a interactuar con los clientes de forma que imite a los agentes de servicio al cliente humanos.
Aunque cada sistema es diferente, los modelos de IA suelen programarse siguiendo el mismo proceso de cinco pasos:
- Formación: el modelo de IA se alimenta de grandes cantidades de datos y utiliza una serie de algoritmos para analizar y evaluar los datos.
- Razonamiento: el modelo de IA clasifica los datos que ha recibido e identifica cualquier patrón en él.
- Ajuste fino: a medida que el modelo de IA prueba diferentes algoritmos, aprende cuáles tienden a tener más éxito y ajusta sus acciones en consecuencia.
- Creación: el modelo de IA utiliza lo aprendido para llevar a cabo tareas asignadas, tomar decisiones o crear música, texto o imágenes.
- Mejorando: finalmente, el modelo de IA realiza ajustes continuos para mejorar su precisión, “aprendizaje” efectivo a partir de su experiencia.

Machine learning frente a deep learning
La mayoría de los sistemas de IA modernos utilizan diversas técnicas y tecnologías para simular los procesos de la inteligencia humana. La más importante de ellas es el deep learning y el machine learning (ML). Aunque los términos machine learning y deep learning a veces se utilizan indistintamente, en realidad son procesos muy distintos en el contexto del entrenamiento de IA.
El machine learning utiliza algoritmos para analizar, categorizar, clasificar, aprender y dar sentido a cantidades masivas de datos para producir modelos precisos y predecir resultados sin tener que decirle exactamente cómo hacerlo.
El deep learning es una subcategoría del machine learning que logra los mismos objetivos utilizando redes neuronales para imitar la estructura y la función del cerebro humano. A continuación, analizaremos ambos conceptos con mayor detalle.
Principios básicos del machine learning
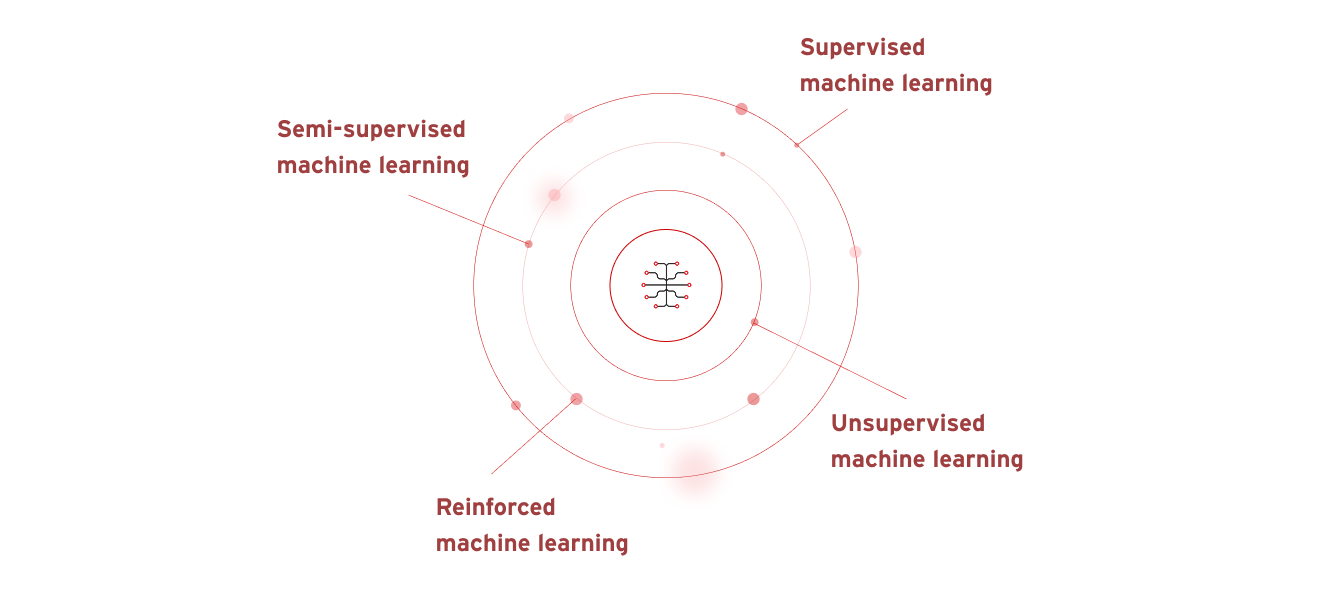
Hay cuatro tipos principales de machine learning:
- Machine learning supervisado: la IA utiliza conjuntos de datos conocidos, establecidos y clasificados para descubrir patrones antes de alimentarlos al algoritmo.
- Machine learning semisupervisado: la IA se forma en un pequeño conjunto de datos conocido y etiquetado, que luego se aplica a conjuntos de datos más grandes, sin etiquetar y desconocidos.
- Machine learning sin supervisión: la IA aprende de conjuntos de datos desconocidos, sin etiquetar y sin clasificar.
- Machine learning reforzado: el modelo de IA no se entrena inicialmente en ningún conjunto de datos, por lo que aprende de las pruebas y errores y altera sus comportamientos hasta que tiene éxito.
El machine learning es lo que permite a los coches autónomos responder a los cambios en el entorno lo suficientemente bien como para poder entregar a sus pasajeros de forma segura en el destino elegido. Otras aplicaciones de machine learning ejecutan la gama desde programas de reconocimiento de voz e imagen, aplicaciones de traducción de idiomas, agentes de IA dirigidos por personas y minería de datos hasta detección de fraude de tarjetas de crédito, diagnósticos de atención médica y recomendaciones de redes sociales, productos o marcas.
Deep learning y redes neuronales
El deep learning es una forma de machine learning que se basa en el uso de redes neuronales avanzadas, algoritmos de machine learning que emulan cómo funcionan las neuronas en un cerebro humano con el fin de identificar patrones complejos en grandes conjuntos de datos.
Por ejemplo, incluso los niños muy pequeños pueden diferenciar instantáneamente a sus padres de otros adultos porque sus cerebros pueden analizar y comparar cientos de detalles únicos o distintivos en un abrir y cerrar de ojos, desde el color de sus ojos y cabello hasta expresiones o rasgos faciales distintivos.
Las redes neuronales replican la forma en que funcionan los cerebros humanos analizando de forma similar miles o millones de pequeños detalles en los datos que se alimentan para detectar y reconocer patrones más grandes entre ellos. Los sistemas de IA generativa (o “GenAI”) como ChatGTP de OpenAI o el generador de imágenes de Midjourney, por ejemplo, utilizan deep learning para ingerir y analizar un gran número de imágenes o texto y, a continuación, utilizan esos datos para crear nuevo texto o imágenes que son similares a, pero diferentes de, los datos originales.
¿Cuáles son los últimos desarrollos en IA?
En los últimos años, las innovaciones revolucionarias en procesamiento del lenguaje natural, visión artificial, aprendizaje de refuerzo y tecnologías de vanguardia como redes adversarias generativas (GAN), modelos de transformadores y verdaderas máquinas habilitadas por IA (AIEM) han ampliado enormemente las capacidades de los sistemas de IA para imitar los procesos de inteligencia humana más estrechamente, generar contenido más realista y realizar tareas cada vez más complejas.
Avances en machine learning y deep learning
En los últimos años, las innovaciones revolucionarias en procesamiento del lenguaje natural, visión artificial, aprendizaje de refuerzo y tecnologías de vanguardia como redes adversarias generativas (GAN), modelos de transformadores y verdaderas máquinas habilitadas por IA (AIEM) han ampliado enormemente las capacidades de los sistemas de IA para imitar los procesos de inteligencia humana más estrechamente, generar contenido más realista y realizar tareas cada vez más complejas.
Avances en machine learning y deep learning
Los revolucionarios avances en machine learning y algoritmos de deep learning han permitido a investigadores y desarrolladores crear sistemas de IA increíblemente sofisticados para una amplia variedad de aplicaciones del mundo real.
Por ejemplo, millones de empresas utilizan chatbots de IA cada día para responder preguntas, vender productos e interactuar con sus clientes. Las empresas también utilizan algoritmos de IA para descubrir tendencias basadas en las compras pasadas de un cliente y realizar recomendaciones personalizadas para nuevos productos, marcas o servicios.
En el campo del reconocimiento automático de voz (ASR), los servicios de IA como Siri y Alexa utilizan el procesamiento del lenguaje natural (NLP) para traducir el habla humana en contenido escrito. Del mismo modo, los avances en las redes neuronales de “visión artificial” impulsadas por IA han hecho que sea más fácil etiquetar fotos en las redes sociales y han hecho que los coches autónomos sean más seguros.
Otros ejemplos de IA que utilizan machine learning o deep learning incluyen algoritmos automatizados de negociación de valores, robots inteligentes que pueden realizar tareas repetitivas en fábricas o en líneas de montaje, y el uso de machine learning para ayudar a los bancos a detectar transacciones sospechosas y detener el fraude financiero.
El papel cambiante de la IA en la ciberseguridad
Cuando se trata del papel de la IA en la ciberseguridad, hay dos áreas distintas pero interrelacionadas a tener en cuenta: Seguridad de IA y ciberseguridad de IA.
La seguridad de IA (también llamada seguridad para IA) se refiere al uso de medidas de ciberseguridad para proteger la pila de IA de una organización, reducir o eliminar los riesgos de seguridad de IA y proteger cada sistema, componente y aplicación de IA en una red, desde los endpoints hasta los modelos de IA. Esto incluye:
- Proteger la pila de IA, la infraestructura, los modelos y los datos de formación frente a ataques
- Mantenimiento de la integridad de los datos de las canalizaciones de machine learning y deep learning
- Abordar los problemas de sesgo de IA, transparencia, explicabilidad y otras preocupaciones éticas
Garantizar que el uso o desarrollo de la IA cumple plenamente con todas las leyes, políticas y normativas pertinentes
La ciberseguridad de IA abarca todas las diferentes formas en las que las herramientas habilitadas para IA pueden mejorar proactivamente las defensas de ciberseguridad de una organización de forma más rápida, precisa y efectiva que cualquier equipo de ciberseguridad humana o centro de operaciones de seguridad (SOC) que pueda. Esto incluye el uso de IA para:
- Identifique ciberamenazas y defienda frente a ciberataques en tiempo real
- Elimine las brechas y vulnerabilidades de ciberseguridad más rápido y con mayor precisión
- Automatice la detección y respuesta ante amenazas y otras herramientas de ciberseguridad para una respuesta más rápida ante incidentes
- Mejore la información sobre amenazas para potenciar o respaldar una gestión de amenazas más eficiente
- Automatice las tareas rutinarias como el análisis de vulnerabilidades y el análisis de registros de datos para liberar al equipo de ciberseguridad humano para abordar amenazas más complejas
Ejemplos de aplicaciones de IA en ciberseguridad
Las organizaciones ya están utilizando la IA de diversas formas para mejorar su postura de ciberseguridad, detectar y responder a ciberataques y defender sus redes de ciberamenazas como filtraciones de datos, ataques de denegación de servicio distribuido (DDoS), ransomware, malware, ataques de phishing y amenazas de identidad.
En el área de detección y respuesta de amenazas, la IA puede identificar y predecir ciberamenazas, analizar patrones en registros de actividad y tráfico de red, autenticar y proteger contraseñas e inicios de sesión de usuarios, emplear reconocimiento facial e inicios de sesión CAPTCHA, simular ciberataques, analizar vulnerabilidades de red y crear defensas de ciberseguridad automatizadas contra amenazas nuevas o emergentes. Esto incluye herramientas como:
- Firewalls de nueva generación (NGFW) con tecnología de IA
- Gestión de eventos e información de seguridad de IA (SIEM)
- Sistemas de seguridad de endpoint y nube de IA
- Detección y respuesta de red de IA (NDR)
- Detección y respuesta extendidas (XDR) de IA
Cuando se produce un ataque, la IA también puede ofrecer estrategias de remediación eficaces o responder automáticamente a incidentes de seguridad basados en las políticas y manuales preestablecidos de una organización. Esto puede ayudar a reducir los costes y minimizar el daño de un ataque, y permitir a las organizaciones recuperarse más rápidamente.
¿Qué consideraciones éticas están implicadas en el desarrollo y uso de la IA?
La IA ofrece claramente una serie de potentes ventajas sobre otros tipos de sistemas informáticos. Sin embargo, al igual que con cualquier nueva tecnología, hay riesgos, desafíos y preguntas éticas que deben tenerse en cuenta en el desarrollo, la adopción y el uso de la IA.
Sesgo y justicia
Los modelos de IA son entrenados por seres humanos utilizando datos extraídos del contenido existente. Esto crea un riesgo de que el modelo pueda reflejar o reforzar cualquier sesgo implícito contenido en ese contenido. Esos sesgos podrían conducir potencialmente a desigualdad, discriminación o injusticia en los algoritmos, predicciones y decisiones que se toman utilizando esos modelos.
Además, dado que el contenido que crean puede ser tan realista, las herramientas de GenAI tienen el potencial de ser utilizadas indebidamente para crear o difundir información errónea, desinformación, contenido dañino e imágenes, audio y vídeo falsos.
Preocupaciones sobre privacidad
También hay varias preocupaciones de privacidad en torno al desarrollo y uso de la IA, especialmente en sectores como la atención sanitaria, la banca y los servicios legales que tratan con información altamente personal, sensible o confidencial.
Para proteger esa información, las aplicaciones impulsadas por IA deben seguir un conjunto claro de prácticas recomendadas en torno a la seguridad, privacidad y protección de datos. Esto incluye el uso de técnicas de anonimización de datos, la implementación de un sólido cifrado de datos y el empleo de defensas de ciberseguridad avanzadas para protegerse contra el robo de datos, las filtraciones de datos y los hackers.
Cumplimiento normativo
Muchas agencias reguladoras y marcos de trabajo como el Reglamento General de Protección de Datos (GDPR) exigen que las empresas sigan un conjunto claro de reglas cuando se trata de proteger la información personal, garantizar la transparencia y la responsabilidad y proteger la privacidad.
Para cumplir con esas normativas, las organizaciones deben asegurarse de que cuentan con políticas corporativas de IA implementadas para supervisar y controlar los datos que se utilizan para crear nuevos modelos de IA y para proteger cualquier modelo de IA que pueda contener información personal o sensible de agentes maliciosos.
¿Cuál es el futuro de la tecnología de IA?
Lo que sucederá en el futuro de la IA es, por supuesto, imposible de predecir. Pero es posible hacer algunas suposiciones educadas sobre lo que viene a continuación en función de las tendencias actuales en el uso y la tecnología de IA.
Tendencias emergentes en la investigación de IA
En términos de investigación de IA, las innovaciones en sistemas autónomos de IA, meta-IA y meta-aprendizaje, modelos de aprendizaje de lenguaje grande (LLM) de código abierto, gemelos digitales y equipos rojos para la validación de riesgos y la toma de decisiones conjunta entre IA y humanos podrían revolucionar la forma en que se desarrolla la IA.
Los nuevos sistemas complejos como la IA neurosímbola, las verdaderas máquinas habilitadas para IA (AIEM) y el machine learning cuántico también probablemente mejorarán aún más el alcance y las capacidades de los modelos, herramientas y aplicaciones de IA.
Otra tecnología que tiene el potencial de revolucionar la forma en que funciona la IA es el paso hacia la IA agente de nueva generación, la IA que tiene la capacidad de tomar decisiones y acciones por sí sola, sin dirección, supervisión ni intervención humanas.
Según el analista tecnológico Gartner, para el año 2028 la IA agente podría utilizarse para tomar hasta el 15 % de todas las decisiones laborales diarias. Las interfaces de usuario (IU) de IA agente también podrían volverse más proactivas e impulsadas por la persona a medida que aprenden a actuar como agentes más humanos con personalidades establecidas, a realizar tareas empresariales más complejas, a tomar decisiones empresariales más importantes y a proporcionar recomendaciones más personalizadas a los clientes.
Posibles impactos de la IA en la fuerza laboral
A medida que la IA aumenta la eficiencia operativa y asume las tareas rutinarias, y a medida que los motores de GenAI como ChatGPT y Midjourney se vuelven más potentes y generalizados, existen preocupaciones válidas sobre el posible impacto en los trabajos en numerosas industrias.
Sin embargo, al igual que con la introducción de Internet, ordenadores personales, teléfonos móviles y otras tecnologías que cambiaron el paradigma en el pasado, la IA también probablemente creará nuevas oportunidades e incluso industrias completamente nuevas que necesitarán trabajadores cualificados y con talento.
Como resultado, en lugar de navegar por las pérdidas de puestos de trabajo, el mayor desafío puede ser determinar la mejor manera de capacitar a los trabajadores para esas nuevas oportunidades y facilitar sus transiciones de la reducción a las ocupaciones crecientes.
El papel de la IA en la respuesta a los desafíos globales
Además de aumentar la eficiencia operativa y mejorar la ciberseguridad, la IA tiene el potencial de ayudar a resolver algunos de los mayores desafíos a los que se enfrenta la humanidad hoy en día.
En el campo de la atención sanitaria, la IA puede ayudar a los médicos a realizar diagnósticos más rápidos y precisos, realizar un seguimiento de la propagación de futuras pandemias y acelerar el descubrimiento de nuevos fármacos, tratamientos y vacunas farmacéuticas.
Las tecnologías de IA podrían mejorar la velocidad y la eficiencia de las respuestas de emergencia ante desastres naturales y provocados por humanos y eventos meteorológicos graves.
La IA también podría ayudar a abordar el cambio climático optimizando el uso de energía renovable, reduciendo las huellas de carbono de las empresas, realizando un seguimiento de la deforestación global y los niveles de contaminación de los océanos, y mejorando la eficiencia de los sistemas de reciclaje, tratamiento del agua y gestión de residuos.
Otras tendencias y desarrollos probables
Algunas de las otras tendencias, capacidades y aplicaciones futuras probables para la IA incluyen:
- Seguridad de modelo de lenguaje grande (LLM) para proteger a los LLM de ataques maliciosos, uso indebido general, acceso no autorizado y otras ciberamenazas. Esto incluye medidas para proteger los datos de LLM, modelos y sus sistemas y componentes asociados.
- IA personalizada y centrada en el usuario para ofrecer un servicio al cliente más personalizado, inteligente y personalizado, incluido para marketing de endpoints de email.
- Uso de modelos de IA para facilitar el trabajo en equipo en rojo y los ejercicios de gemelo digital simulando ataques en los sistemas de TI de una organización para probar vulnerabilidades y mitigar cualquier defecto o debilidad.
¿Dónde puedo obtener ayuda con la IA y la ciberseguridad?
Trend Vision One to End ofrece una protección de extremo a extremo inigualable para toda la pila de IA en una única plataforma unificada con tecnología de IA.
Aprovechando las numerosas funciones de Trend Cybertron, la primera IA de ciberseguridad proactiva del mundo, Trend Vision One incluye un conjunto de funciones de IA agente que evolucionan continuamente en función de la inteligencia del mundo real y las operaciones de seguridad.
Esto le permite adaptarse rápidamente a las amenazas emergentes con el fin de mejorar la postura de seguridad de una organización, mejorar la eficiencia operativa, transformar las operaciones de seguridad de reactivas a proactivas y proteger cada capa de la infraestructura de IA.


Fernando Cardoso es el vicepresidente de Product Management en Trend Micro, centrándose en el mundo en constante evolución de la IA y la nube. Su carrera comenzó como ingeniero de ventas y redes, donde perfeccionó sus habilidades en datacenters, nube, DevOps y ciberseguridad, áreas que continúan impulsando su pasión.
Preguntas frecuentes (FAQ)
¿Qué es una IA?
La inteligencia artificial (o “IA”) es un ordenador que utiliza tecnología para imitar la forma en que los seres humanos piensan, funcionan y toman decisiones.
¿Qué hace realmente la IA?
Los modelos de IA utilizan algoritmos complejos y utilizan grandes cantidades de información "aprendida" para calcular las respuestas a las preguntas de los usuarios o generar contenido basado en las indicaciones de los usuarios.
¿Es Siri una IA?
Siri es una forma sencilla de IA que utiliza tecnologías como el machine learning y el reconocimiento de voz para comprender y responder al habla humana.
¿La IA es buena o mala?
Como todas las tecnologías, la IA no es intrínsecamente buena ni mala. Es una herramienta que se puede utilizar para fines positivos y negativos.
¿Cuál es el objetivo principal de la IA?
El objetivo principal de la IA es permitir que los ordenadores tomen decisiones más inteligentes, realicen tareas más difíciles y aprendan de la experiencia sin una constante aportación humana.
¿Por qué se creó la IA?
La IA se desarrolló para ayudar a automatizar tareas repetitivas, resolver problemas complejos y permitir una investigación e innovación más avanzadas en múltiples sectores diferentes.
¿Cuáles son los riesgos de la IA?
Algunos riesgos planteados por la IA incluyen preocupaciones sobre sesgos e imparcialidad, riesgos de privacidad, riesgos de ciberseguridad y el potencial de desplazamiento del trabajo.
¿Quién hizo la IA?
Los científicos informáticos Alan Turing (1912 – 1954) y John McCarthy (1927 – 2011) suelen considerarse los “padres de la IA” no oficiales.
¿Qué es la IA en la vida real?
Hay muchos ejemplos de IA en nuestra vida diaria, desde software en el smartphone en su bolsillo hasta chatbots que responden a preguntas comunes de atención al cliente.
¿Qué es una IA sencilla?
Algunos ejemplos de IA simples incluyen asistentes de voz como Siri o Alexa, motores de búsqueda inteligentes como Google, chatbots de atención al cliente e incluso robots aspiradores.
¿Cuáles son las desventajas de la IA?
Algunas de las desventajas de la IA incluyen preocupaciones sobre la privacidad y los sesgos, los riesgos de ciberseguridad y el posible impacto en los trabajos en ciertos campos.
¿Cuáles son las 5 desventajas de la IA?
Dependiendo de cómo se utilice, la IA puede provocar pérdidas de trabajo, generar información errónea, comprometer la información privada, reducir la creatividad y conducir a una excesiva dependencia de la tecnología.
¿Cómo puedo activar la IA?
La mayoría de las herramientas de IA se pueden activar o desactivar en las funciones de configuración de teléfonos móviles, ordenadores, aplicaciones de software o sitios web.
¿Puedo utilizar la IA de forma gratuita?
Muchas herramientas de IA como los motores de búsqueda o Alexa son completamente gratuitas. Otros, como ChatGPT, ofrecen opciones gratuitas y de pago. La IA de grado comercial suele ser solo de pago.
¿Qué IA es totalmente gratuita?
La mayoría de las empresas de IA ofrecen versiones introductorias gratuitas, incluidas Microsoft Copilot, Grammarly, Google Gemini y ChatGPT.
¿Cuál es la aplicación de IA más popular en este momento?
Actualmente, las aplicaciones de IA más populares incluyen ChatGPT, Google Maps, Google Assistant, Microsoft Copilot y Google Gemini.
¿Cuál es la aplicación de escritura de IA que todo el mundo utiliza?
Algunas de las aplicaciones de escritura asistida por IA más populares son Grammarly, ChatGPT, Writesonic, Jasper y Claude.
¿Cuál es la aplicación de IA que todo el mundo está utilizando de forma gratuita?
Google Gemini, Copilot de Microsoft y ChatGPT se encuentran entre las aplicaciones de IA gratuitas más utilizadas en este momento.
¿Cuál es el mejor chatbot de IA en este momento?
El “mejor” chatbot depende de para qué lo necesite, pero algunos de los chatbots de IA más populares incluyen Perplexity, Google Gemini, Jasper y ChatGPT.
¿Cuál es un ejemplo de IA en la vida diaria?
Algunos ejemplos comunes de IA en la vida diaria incluyen smartphones, motores de búsqueda de IA, chatbots de servicio al cliente y asistentes de voz digitales como Siri y Alexa.
Artículos relacionados
Los 10 principales riesgos y mitigaciones de 2025 para aplicaciones de IA de generación y LLM
Gestión de riesgos emergentes para la seguridad pública
¿Hasta dónde nos pueden llevar los estándares internacionales?
Cómo redactar una política de ciberseguridad de IA generativa
Ataques maliciosos mejorados con IA entre los principales riesgos
Aumento de la amenaza de identidades falsas