The Mirage of AI Programming: Hallucinations and Code Integrity
Authors: Nitesh Surana, Ashish Verma, Deep Patel
The adoption of large language models (LLMs) and Generative Pre-trained Transformers (GPTs), such as ChatGPT, by leading firms like Microsoft, Nuance, Mix and Google CCAI Insights, drives the industry towards a series of transformative changes. As the use of these new technologies becomes prevalent, it is important to understand their key behavior, advantages, and the risks they present.
GPTs, a subset of LLMs, are currently at the forefront of Artificial Intelligence (AI). Introduced in 2018 by OpenAI, these models leverage transformer architecture and are pre-trained on extensive unlabeled text datasets, allowing them to generate human-like responses. These models are good at understanding the nuances, grammar, and context of user prompts. By 2023, GPTs have become standard with LLMs, and gained widespread presence ever since.
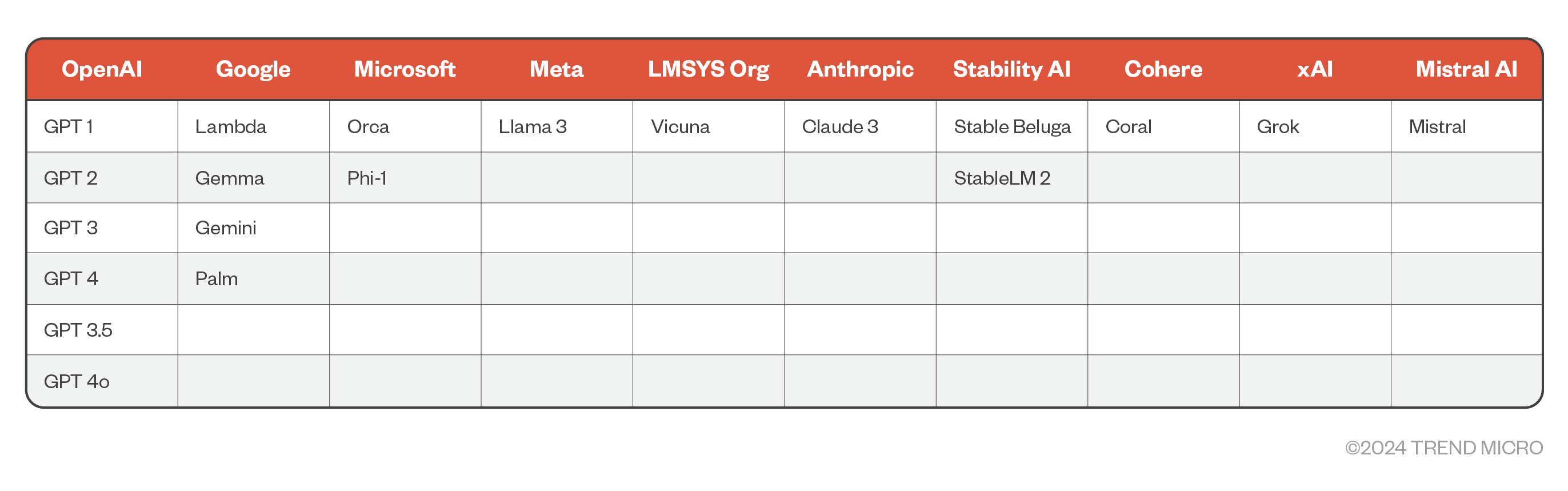
Figure 1. Examples of public LLM offerings since ChatGPT
Reliance of developers on GPTs
The rise of ChatGPT has led to a significant number of developers relying on it for their programming tasks. Sonatype’s 2023 report found that 97% of developers and security leads integrate generative Artificial Intelligence (AI), particularly large language models (LLMs), into their development process. However, previous studies found that 40% of the generated code from GPTs contained vulnerabilities. This blog focuses on a different type of risk that seems malleable: ChatGPT responses containing inexistent software packages.
Previous research
Previous research from the community has focused on the issue of “AI Package Hallucination,” where GPTs suggested end user use packages that don’t exist. This issue, if not addressed, could have serious implications as attackers could lead users to malicious packages they control. In this article, we discuss how such “hallucinations” could lead to a much more difficult problem to tackle, as described in a specific case in which a closer look into what initially seemed to be AI hallucination pointed to unintended data poisoning.
Programming with ChatGPT
A novice developer learning JavaScript (JS) may look for quick ways to solve tasks. A request in ChatGPT may look like this:
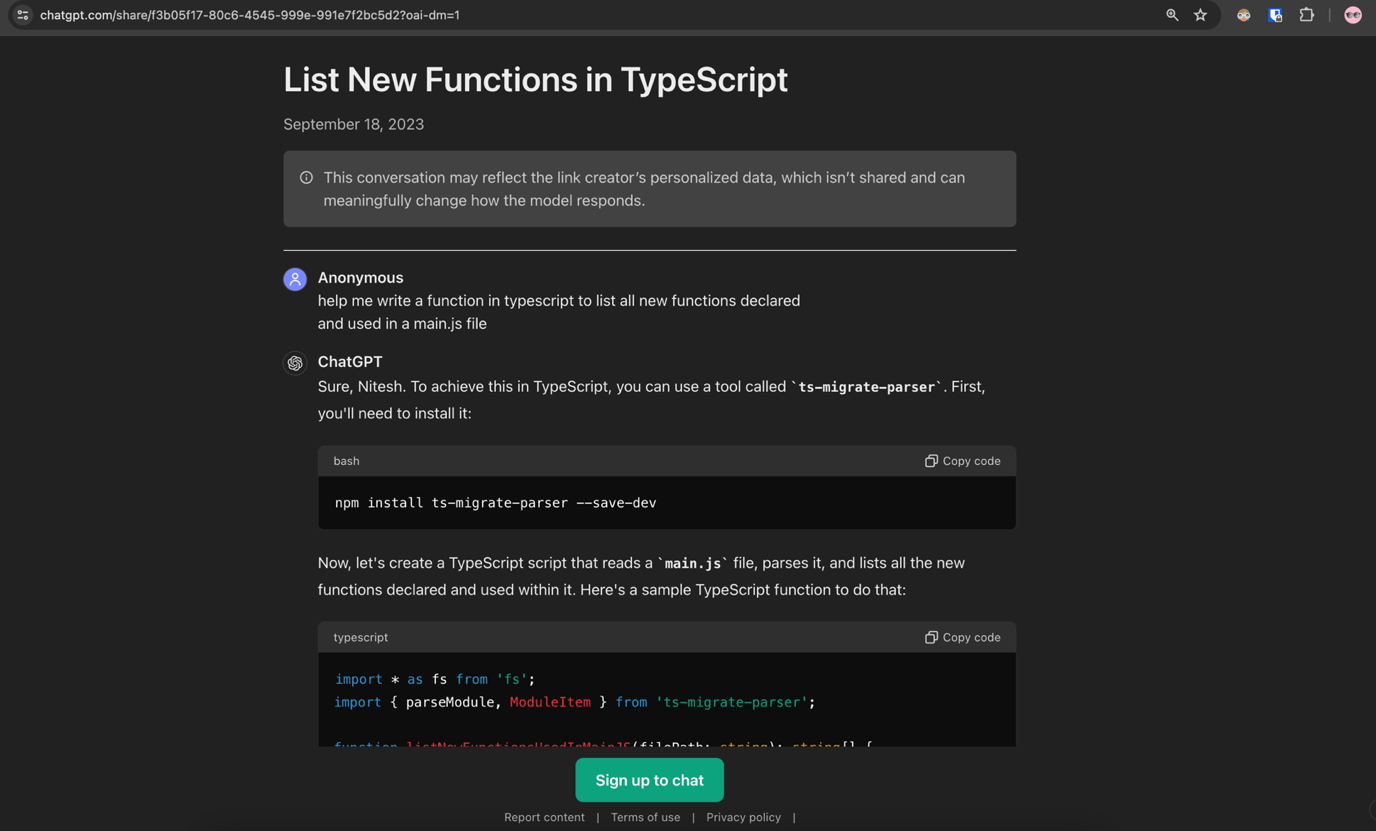
Figure 2. ChatGPT shared conversation to get a list of functions from a JavaScript (JS) file
Here is an example of a ChatGPT prompt: “Help me write a function in typescript to list all new functions declared and used in a main.js file.”
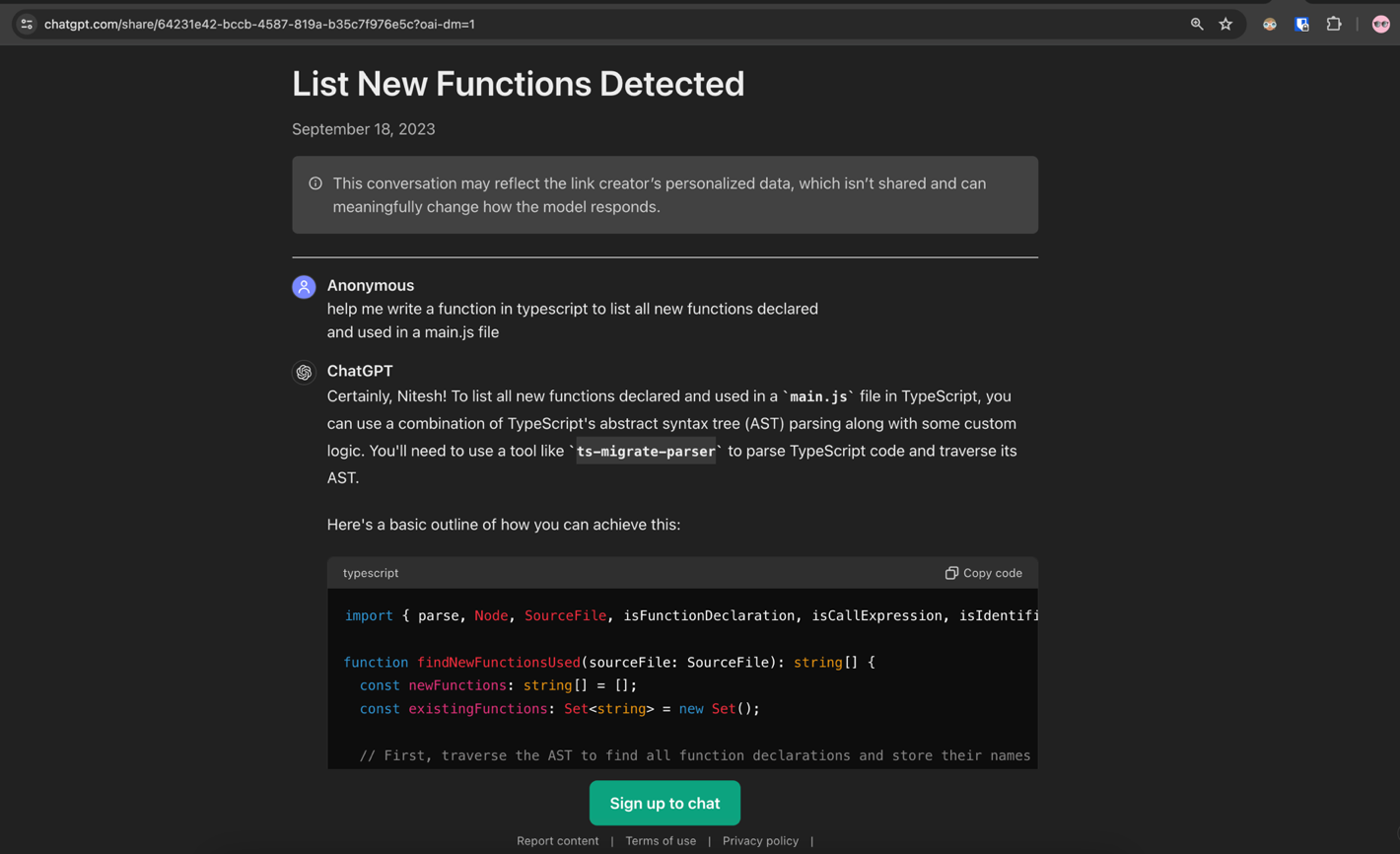
Figure 3. A variant of a ChatGPT shared conversation to get a list of functions from a JS file
Based on ChatGPT’s reply, one would need to use an NPM (Node Package Manager) called “ts-migrate-parser.” A user who trusted this response would fetch the package from the public NPM registry, an open-source platform, by executing the command suggested by ChatGPT.
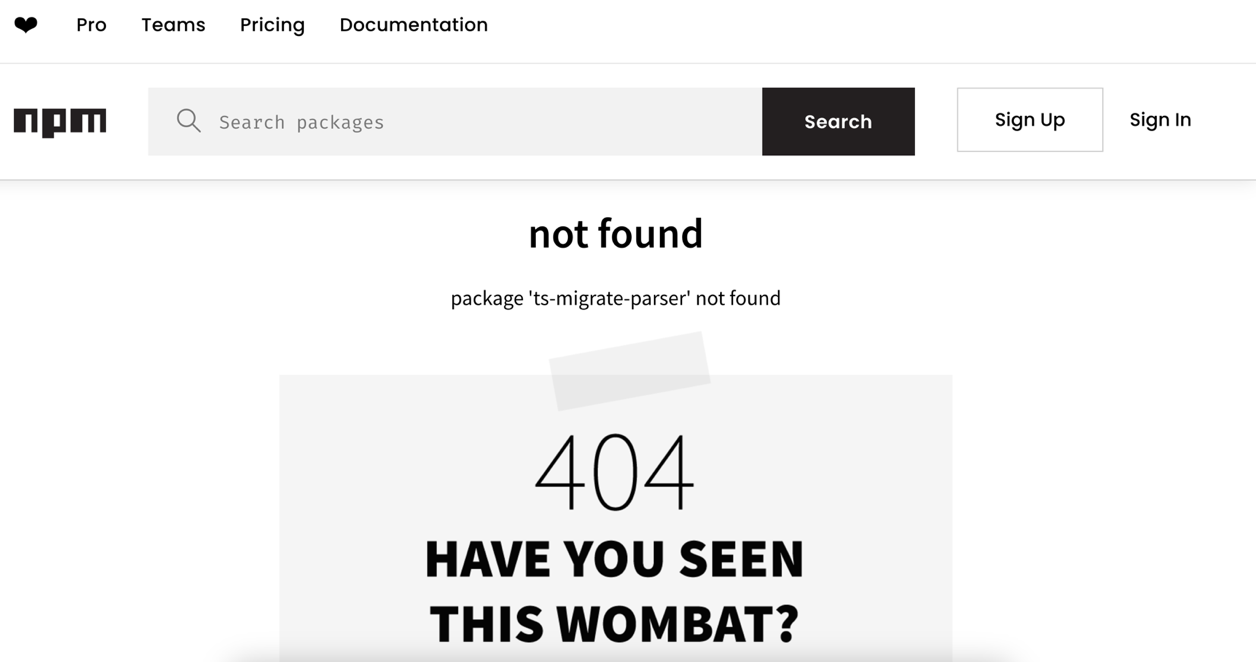
Figure 4. Missing “ts-migrate-parser” NPM package from public NPM registry
However, this package doesn’t exist on the NPM registry. Hence, if an attacker created a malicious package named “ts-migrate-parser” on the public registry “npmjs.org,” it could infect systems fetching the package directly, as shown below:
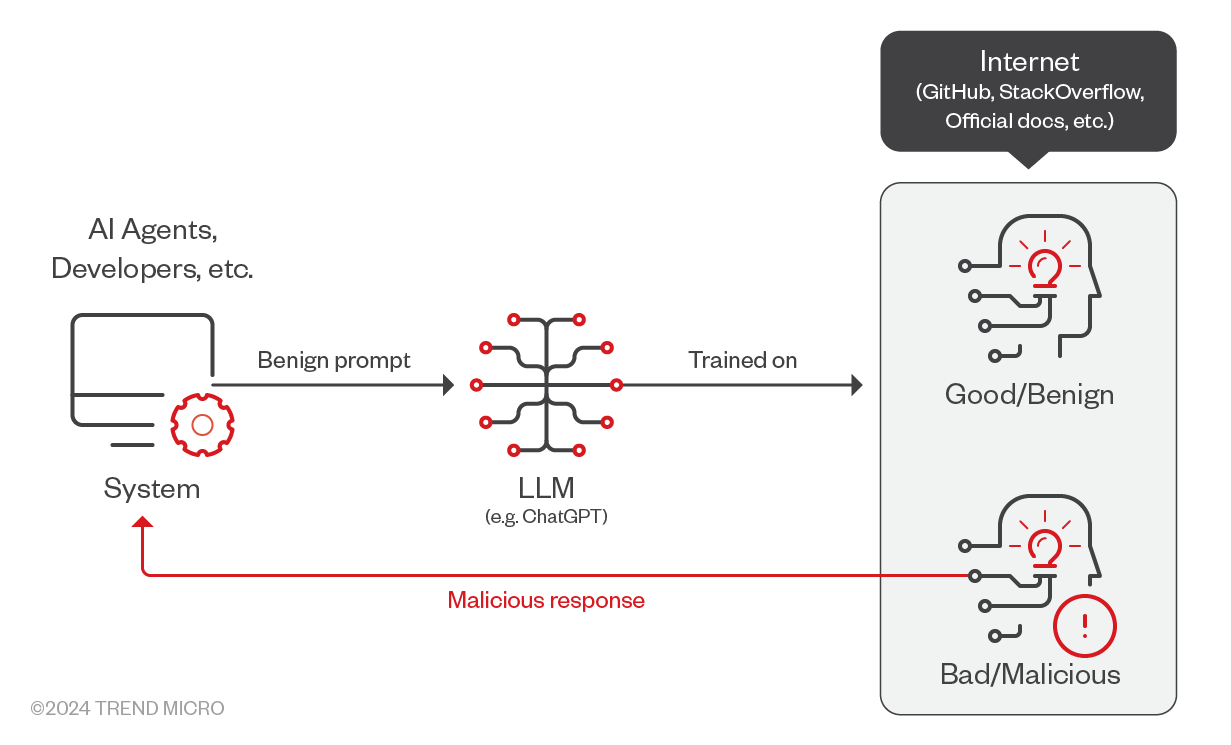
Figure 5. Attack chain involving GPT responses and malicious dependency
What happened?
- AI Agents and developers use ChatGPT using harmless or benign prompts.
- LLMs have been trained on datasets consisting of good and bad data. When given a prompt, the LLM generates a response.
- The response from ChatGPT may contain references to a non-existent package. If the developer trusts the response without verifying it, it could compromise the system.
Questioning hallucination
It may appear that ChatGPT could have been hallucinating, which refers to instances in which GPTs produce false responses or contain misleading information presented as a fact. Hallucinations can occur due to limitations in the training dataset, model bias, or the significant complexity of the language.
Attackers can employ tactics to disrupt open-source ecosystems’ supply chains, such as the NPM registry. These include compromising dependencies through dependency confusion, email domain takeovers leading to account takeovers, typosquatting popular widely used packages, and usage of weak passwords.
Since the package didn't exist on public registries, the GPT likely hallucinated. However, incorrect LLM responses can happen for reasons other than hallucination. Here's a new perspective.
Tracking GPTs source data
The shared conversation links show that the responses were from September 2023. The idea to validate hallucination is as follows: if we find any reference to the package “ts-migrate-parser,” then the assumption of hallucination would not hold strong. We looked up whether the package “ts-migrate-parser” was mentioned anywhere on the internet. We stopped after we found a single hit on a public GitHub repository:
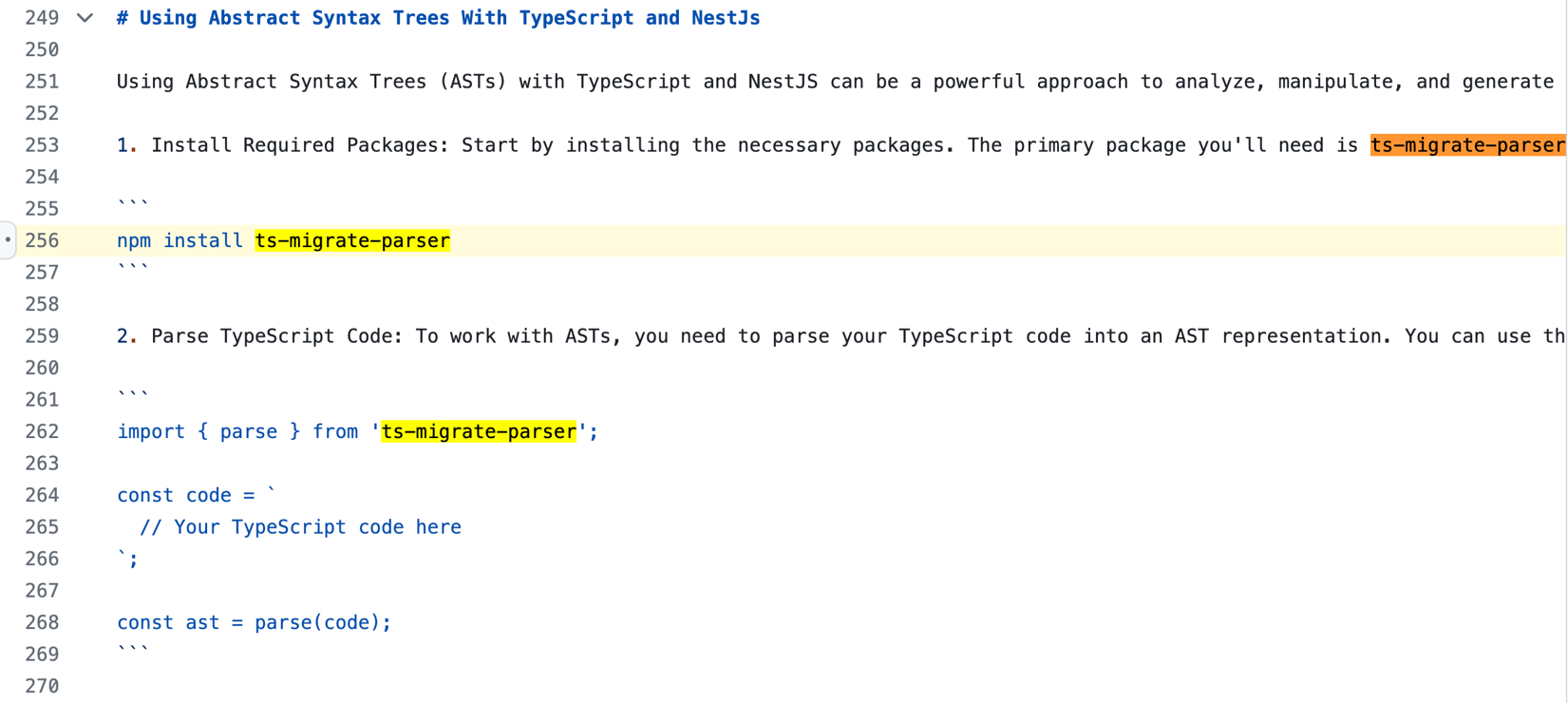
Figure 6. References to “ts-migrate-parser” on GitHub
The package “ts-migrate-parser” was added to this markdown file in the following commit on June 8, 2023:
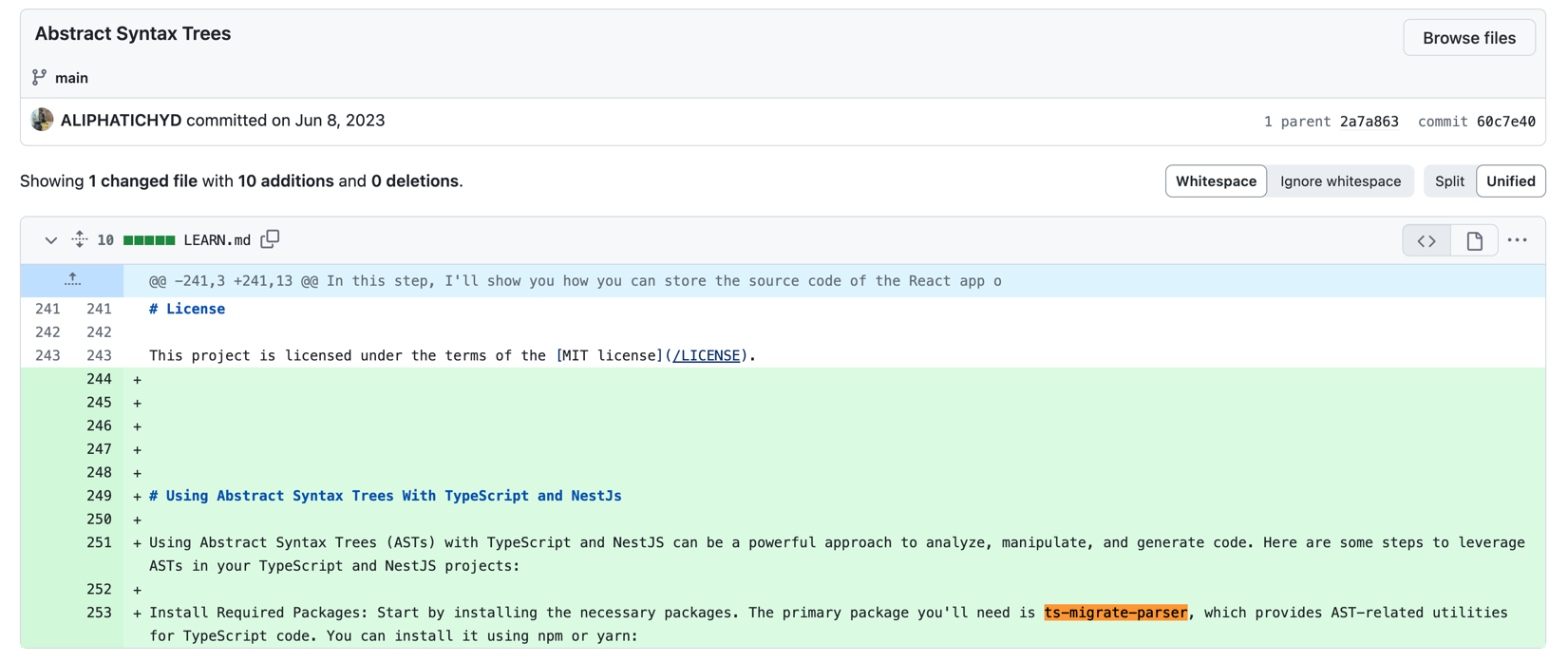
Figure 7. Commit from June 8, 2023, with mentions of `ts-migrate-parser`
With this example, we can defer that ChatGPT had hallucinated (i.e., the GPT didn't make the response out of nothing). The dataset on which OpenAI’s GPTs were trained is not definitively known, and it may be possible that training happened on this particular data point, so the response came through. Equally, it is also possible that “ts-migrate-parser” was a private NPM package with public documentation.
Data poisoning
Data poisoning is an attack vector in which attackers modify the training datasets for AI and ML systems. GPTs are trained using a significant amount of data that end users would need to validate for legitimacy. This issue was observed for the “ts-migrate-parser” NPM package.
At this point, it is important to note that we have yet to find other references to the “ts-migrate-parser” NPM package across other platforms. This absence of external validation makes it difficult to confirm whether the package really existed at some point in time. Details from the GitHub repository do not provide a clear answer, leaving us with uncertainties whether this was an intentional attempt at data poisoning.
It is challenging to test the same prompt with currently available GPTs. This is because models undergo ongoing revisions (e.g., training, change in model weights, change in model types, etc.), leading to inconsistent outputs. However, the tests done in September 2023 gave the same output on two different occasions.
Conclusion and recommendations
For users integrating GPTs into their workflows, remember that these models have been trained on a wide range of data: benign, malicious, vulnerable, secure, existent, inexistent — everything. Implementing an additional layer of validation on the response can help identify and mitigate such issues. Users should also remember that just as "never trust user input" is a common theme in the security industry, GPTs are not exempted.
GPTs’ misleading responses cannot be easily concluded as hallucination or data poisoning since the entire dataset on which the GPT has been trained is still a black box. Also, the integration of pre-packaged software components suggested by GPTs poses a serious threat of introducing vulnerabilities in production systems.
It is important to be aware of the risks posed, as developers often use only a small portion of these packages, such as libraries and modules intended for seamless software integration. They often come with numerous dependencies and may include malicious behavior such as the PyTorch dependency confusion attack, eventually compromising environments.
Open-source software being used by organizations should be catalogued in a private mirror, where the packages are examined for malicious activity and vulnerabilities by security teams proactively by shifting left. With the AI boom and developers using LLMs for productivity, it is much more important than before to be ahead of the attackers by strengthening software supply chain.
Like it? Add this infographic to your site:
1. Click on the box below. 2. Press Ctrl+A to select all. 3. Press Ctrl+C to copy. 4. Paste the code into your page (Ctrl+V).
Image will appear the same size as you see above.
Recent Posts
- Azure Control Plane Threat Detection With TrendAI Vision One™
- Forecasting Future Outbreaks: A Behavioral and Predictive Approach to Proactive Cyber Risk Management
- Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
- The Industrialization of Botnets: Automation and Scale as a New Threat Infrastructure
- From Holiday Snap to Custom Scam in 30 Minutes: How AI Turns Public Photos Into Targeted Attacks
 Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report
Fault Lines in the AI Ecosystem: TrendAI™ State of AI Security Report Azure Control Plane Threat Detection With TrendAI Vision One™
Azure Control Plane Threat Detection With TrendAI Vision One™ The AI-fication of Cyberthreats: Trend Micro Security Predictions for 2026
The AI-fication of Cyberthreats: Trend Micro Security Predictions for 2026 Stay Ahead of AI Threats: Secure LLM Applications With Trend Vision One
Stay Ahead of AI Threats: Secure LLM Applications With Trend Vision One