Cyber Crime
Rogue AI: What the Security Community is Missing
This is the fourth blog post in an ongoing series on Rogue AI. Keep following for more technical guidance, case studies, and insights.


Save to Folio
Previously in this series, we’ve taken a deep dive into Rogue AI to understand what it is and how we can identify it. In the last blog, we also looked at possible mitigations. Our aim here is to help shape the debate around the future of cybersecurity threats and find the most effective ways to minimize the risks they pose to individuals, companies and society at large.
In this piece, we’ll explore community efforts currently underway to assess AI risk. While there’s some great work being done, what they’re missing to date is the idea of linking causality with attack context.
Who’s doing what?
Different parts of the security community have different perspectives on Rogue AI:
- OWASP focuses on vulnerabilities and mitigations, with its Top 10 for LLM Applications report, and high-level guidance in its LLM AI Cybersecurity and Governance Checklist
- MITRE is concerned with attack tactics and techniques, via an ATLAS matrix that extends MITRE ATT&CK to AI systems
- A new AI Risk Repository from MIT provides an online database of over 700 AI risks categorized by cause and risk domain
Let’s take a look at each in turn.
OWASP
Rogue AI is related to all of the Top 10 large language model (LLM) risks highlighted by OWASP, except perhaps for LLM10: Model Theft, which signifies “unauthorized access, copying, or exfiltration of proprietary LLM models.” There is also no vulnerability associated with “misalignment”—i.e., when an AI has been compromised or is behaving in an unintended manner.
Misalignment:
- Could be caused by prompt injection, model poisoning, supply chain, insecure output or insecure plugins
- Can have greater Impact in a scenario of LLM09: Overreliance (in the Top 10)
- Could result in Denial of Service (LLM04), Sensitive Information Disclosure (LLM06) and/or Excessive Agency (LLM08)
Excessive Agency is particularly dangerous. It refers to situations when LLMs “undertake actions leading to unintended consequences,” and stems from excessive functionality, permissions or autonomy. It could be mitigated by ensuring appropriate access to systems, capabilities and use of human-in-the-loop.
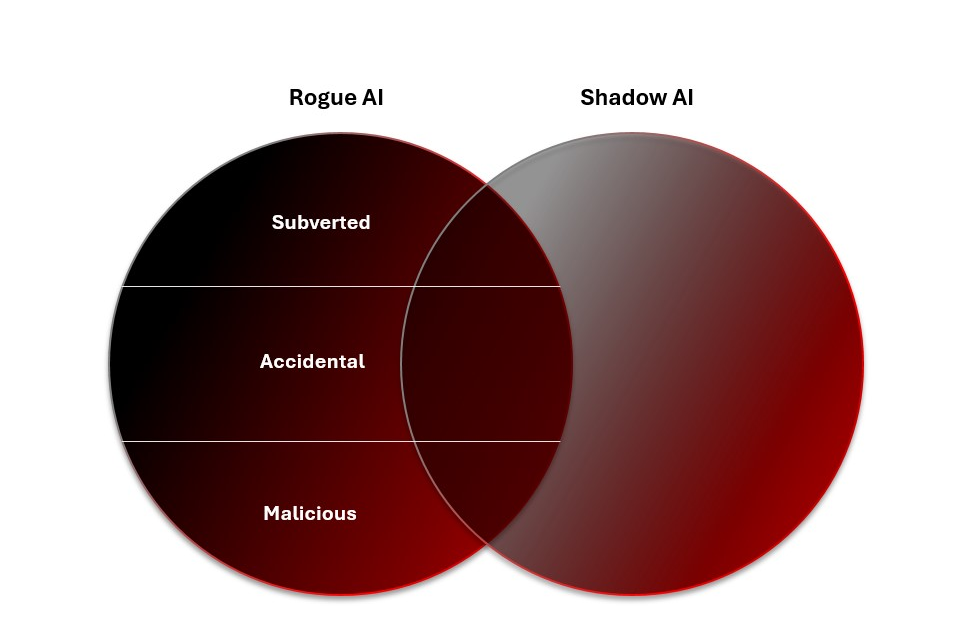
OWASP does well in the Top 10 at suggesting mitigations for Rogue AI (which is a subject we’ll return to), but doesn’t deal with causality: i.e., whether an attack is intentional or not. Its security and governance document also offers a handy and actionable checklist for securing LLM adoption across multiple dimensions of risk. It highlights shadow AI as the “most pressing non-adversary LLM threat” for many organizations. Rogues thrive in shadow, and lack of AI governance is already AI use beyond policy. Lack of visibility into Shadow AI systems prevents understanding of their alignment.
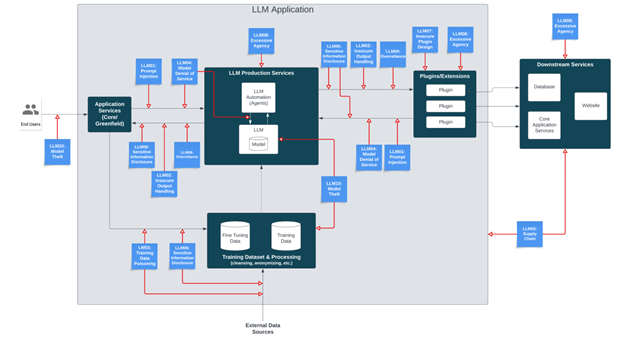
MITRE ATLAS
MITRE’s tactics techniques and procedures (TTPs) are a go-to resource for anyone involved in cyber-threat intelligence—helping to standardize analysis of the many steps in the kill chain and enabling researchers to identify specific campaigns. Although ATLAS extends the ATT&CK framework to AI systems, it doesn’t address Rogue AI directly. However, Prompt Injection, Jailbreak and Model Poisoning, which are all ATLAS TTPs, can be used to subvert AI systems and thereby create Rogue AI.
The truth is that these subverted Rogue AI systems are themselves TTPs: agentic systems can carry out any of the ATT&CK tactics and techniques (e.g., Reconnaissance, Resource Development, Initial Access, ML Model Access, Execution) for any Impact. Fortunately, only sophisticated actors can currently subvert AI systems for their specific goals, but the fact that they’re already checking for access to such systems should be concerning.
Although MITRE ATLAS and ATT&CK deal with Subverted Rogues, they do not yet address Malicious Rogue AI. There’s been no example to date of attackers installing malicious AI systems in target environments, although it’s surely only a matter of time: as organizations begin adopting agentic AI so will threat actors. Once again, using an AI to attack in this way is its own technique. Deploying it remotely is like AI malware, and more besides—just as using proxies with AI services as attackers is like an AI botnet, but also a bit more.
MIT AI Risk Repository
Finally, there’s MIT’s risk repository, which includes an online database of hundreds of AI risks, as well as a topic map detailing the latest literature on the subject. As an extensible store of community perspective on AI risk, it is a valuable artifact. The collected risks allow more comprehensive analysis. Importantly, it introduces the topic of causality, referring to three main dimensions:
- Who caused it (human/AI/unknown)
- How it was caused in AI system deployment (accidentally or intentionally)
- When it was caused (before, after, unknown)
Intent is particularly useful in understanding Rogue AI, although it’s only covered elsewhere in the OWASP Security and Governance Checklist. Accidental risk often stems from a weakness rather than a MITRE ATLAS attack technique or an OWASP vulnerability.
Who the risk is caused by can also be helpful in analyzing Rogue AI threats. Humans and AI systems can both accidentally cause Rogue AI, while Malicious Rogues are, by design, intended to attack. Malicious Rogues could theoretically also try to subvert existing AI systems to go rogue, or be designed to produce “offspring”—although, at present, we consider humans to be the main intentional cause of Rogue AI.
Understanding when the risk is caused should be table stakes for any threat researcher, who needs to have situational awareness at all points in the AI system lifecycle. That means pre- and post-deployment evaluation of systems and alignment checks to catch malicious, subverted or accidental Rogue AIs.
MIT divides risks into seven key groups and 23 subgroups, with Rogue AI directly addressed in the “AI System Safety, Failures and Limitations” domain. It defines it thus:
“AI systems that act in conflict with ethical standards or human goals or values, especially the goals of designers or users. These misaligned behaviors may be introduced by humans during design and development, such as through reward hacking and goal mis-generalization, and may result in AI using dangerous capabilities such as manipulation, deception, or situational awareness to seek power, self-proliferate, or achieve other goals.”
Defense in depth through causality and risk context
The bottom line is that adopting AI systems increases the corporate attack surface—potentially significantly. Risk models should be updated to take account of the threat from Rogue AI. Intent is key here: there’s plenty of ways for accidental Rogue AI to cause harm, with no attacker present. And when harm is intentional, who is attacking whom with what resources is critical context to understand. Are threat actors, or Malicious Rogue AI, targeting your AI systems to create subverted Rogue AI? Are they targeting your enterprise in general? And are they using your resources, their own, or a proxy whose AI has been subverted.
These are all enterprise risks, both pre- and post-deployment. And while there’s some good work going on in the security community to better profile these threats, what’s missing in Rogue AI is an approach which includes both causality and attack context. By addressing this gap, we can start to plan for and mitigate Rogue AI risk comprehensively.
To read more about Rouge AI: