Cloud
The Difference Between Virtual Machines and Containers
Discover the key differences, use cases, and benefits of virtual machines and containers.


Save to Folio
The difference between virtual machines and containers
Virtual machines (VMs) and containers are as similar as they are different. They each have their own unique characteristics and use cases that separate them from each other. However, they are similar in that they can be used either together, or interchangeably, to enhance IT and DevOps efficiency.
Great, all that sounds fine and dandy, but what are virtual machines and containers actually used for? I’m glad you asked.
Virtualization
According to IBM, virtualization is a process whereby software is used to create an abstraction layer over computer hardware that allows the hardware elements of a single computer to be divided into multiple virtual computers. Thus, birthing virtual machines.
VMs traditionally run far more operations than a single container. However, this ability does make them less portable than containers. Here are a few use cases for virtual machines:
- Isolate risky developments.
- Have it act as your own sandbox.
- Run or test a different OS than your current one.
- Save data from older systems.
Containers on the other hand are smaller and lightweight, which allows them to be moved easily across the different cloud environments. Here are some use cases for containers:
- Build cloud-native apps.
- Package microservices.
- Deploy repetitive jobs and tasks easier.
What makes them different?
Monolithic applications are often refactored into a set of microservices that each have a distinct function and work together to provide the same functionality as the original application. This new architecture has a several advantages:
- It allows you to scale specific functions separately.
- It also makes it easier to develop new functionality. As long as a developer works on his “own” container and respects the required API endpoints, there is little risk of breaking the application.
The two main differences between VMs and containers are:
- Containers do not contain a complete OS.
- The isolation that a container provides is totally different than the isolation provided by a virtual machine.
To understand the latter, we need to understand how a container is created.
History of containers
Linux Namespaces was created in 2002 by Eric W. Biederman, Pavel Emelyanov, Al Viro, and Cyrill Gorcunov. I mention that because containers are talked about as if they are something new and unheard-of, when in reality they’ve been around for a while. It’s a given that the containers we see and use today differ greatly from what we had when they first came out, but the core idea of their purpose remains the same.
Namespaces are one of the main features of the Linux kernel. They make sure that a set of processes “sees” only a specified subset of the resources of the host. A similar project, the Control Group project (cgroups) by Paul Menage and Rohit Seth was added to the Linux kernel in 2008. Cgroups allow you to allocate the resource usage of a collection of processes.
When you combine these two features you have the core components for a container.
Namespaces and cgroups
The diagram below shows how cgroups and namespace slice up a host.
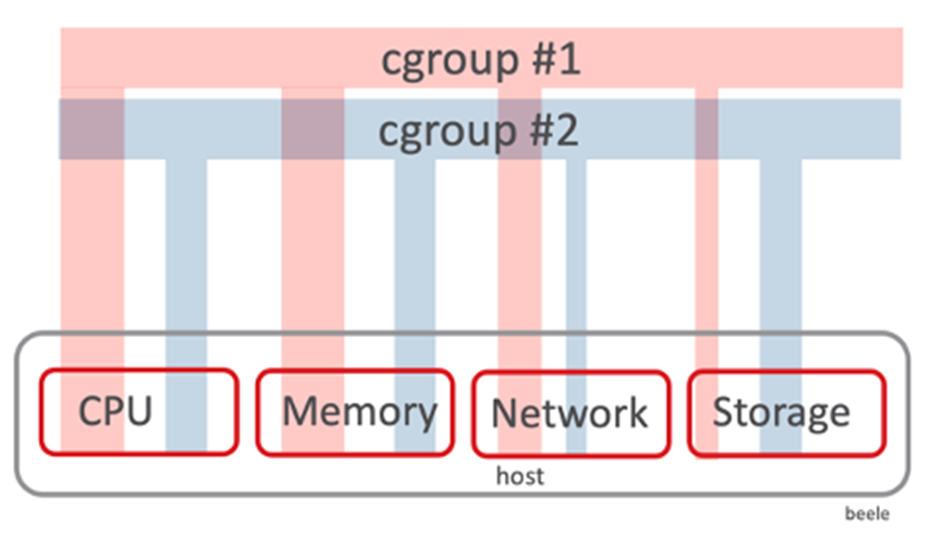
Slicing up a host isolates the processes from each other which is very important. The main benefits of isolating the process from each other are stability and security. If a process runs away and tries to aggregate too much memory or CPU, the host will restrict the cgroup to only get whatever amount it is relegated to. This is absolutely essential because if the process did run away and there was no stopgap, it could overpower everything and bring down the host, including other applications that run on that same host.
In the diagram above, for a process that is running in cgroup1, its “world” is that specific cgroup. It “thinks” the server only has a small CPU, indicated by the red slice. The same for the memory, the network, and the storage. That process has no knowledge about anything outside of cgroup1. The same is true for a process in cgroup2 and so on.
Let’s put this isolation to a test
Below is a little do-it-yourself test for you to run. To put what was said earlier into action, follow the steps below.
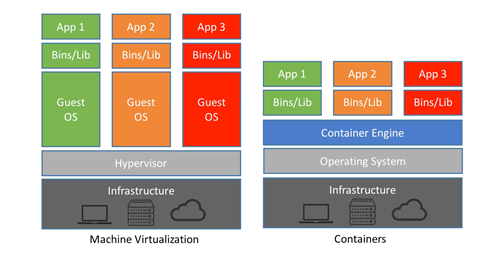
Based on the diagram below, we can picture “a container on a host” like this.
Let’s start a container:
docker run -p 8080:80 -d nginx
Now connect to the Nginx container:
docker exec -it ${MYCONTAINERID} bash
Still in the container, create a file. Then exit the container:
echo "this is a test" >> mydummytestfile.txt
exit
Now on the host, search for that file:
sudo find / -name mydummytestfile.txt
Voila, there is that file… on the host!

In some implementations, on the host, you can even see the processes running inside the container(s).
Securing containers
While containers do a good job of isolating their resources from other containers, they are leaking information to their host. Unlike with virtual machines, with containers the host can “see” what is going on in each container. Securing the container host is one of seven main security concerns for containers—but don’t panic. Leveraging the right security tool—such as a unified cybersecurity platform—with automation and customizable APIs can help DevOps teams secure your containers without disrupting workflows.
Check out these resources for more insights into container security:
[Documentation] Trend Micro Cloud One™ – Container Security
[Documentation] Trend Micro Cloud One ™ – Workload Security
[Video] Seven Things DevOps Needs to Know About Container Security
[Blog] 7 Container Security Best Practices For Better Apps
[Blog] How to use Rancher in Kubernetes
[Blog] Detect Container Drift in Your Kubernetes Deployments
