Cloud
Terraform Tutorial: Drift Detection Strategies
A fundamental challenge of architecture built using tools like Terraform is configuration drift. Check out these actionable strategies and steps you can take to detect and mitigate Terraform drift and manage any drift issues you might face.


Save to Folio
A common misconception among DevOps teams using infrastructure as code (IaC) tools is that the templates they use to run their deployments are infallible sources of truth. Instead, a fundamental challenge of architectures built using tools like Terraform is configuration drift. This occurs when the actual state of your infrastructure begins to accumulate changes and deviates from the configurations defined in your code.
Configuration drift can occur for many reasons, regardless of how good your DevOps engineers are at trying to avoid it. Even when your deployments are completely dependent on IaC, there might be situations where drift occurs. Common failure points typically include adding, removing, or modifying remote resources.
Another big risk is that there’s no easy way to guarantee that deployments in cloud environments are only being implemented by using IaC. It’s often still possible to deploy manually or semi-manually by using the web portal browser, command-line interface, or via APIs.
Because this is an ongoing—and potentially serious—problem in environments that rely on IaC, this article will show your DevOps teams how to counteract common Terraform drift. This article explores a few different strategies for detecting, monitoring, and remediating drift using examples from a sample Azure Virtual Machine deployment.
Terraform state
To better understand how Terraform drift can occur, it’s important to know the purpose and significance of the Terraform state.
In addition to containing environmental metadata, the most significant function of the Terraform state is to be the single source of truth for your back-end APIs. Terraform uses a declarative approach to configuration and resource mapping, binding each remote object to a resource and then recording this association in a Terraform state file.
To do this, it contains the list of deployed resources with their settings and parameters and keeps track of any providers and dependencies.
At the start of a simple terraform plan deployment job, for example, the terraform.tfstate file is initialized with these properties:
Directory of C:\Terraform\my1stlinuxvm
02/09/2022 03:03 PM 0 terraform.tfstate
After running the deployment, the summary is a little different:
Directory of C:\Terraform\my1stlinuxvm
02/09/2022 03:09 PM 27,589 terraform.tfstate
The state file contains extensive details about all deployed resources. For example, it encodes approximately 25Mb of state information to deploy your Azure Virtual Machine—including the deployment and state metadata itself. This metadata is found at the beginning of the file:
{
"version": 4,
"terraform_version": "0.13.4",
"serial": 12,
"lineage": "ba42cc9f-46ae-13f5-4808-08716f7b82b1",
"outputs": {},
"resources": [
{
"mode": "managed",
"type": "azurerm_linux_virtual_machine",
"name": "myterraformvm",
"provider": "provider[\"registry.terraform.io/hashicorp/azurerm\"]",
"instances": [
The Terraform state file also contains various environment metadata. In this case, the file clearly identifies the version of Terraform used for running the deployment. This is important to the immutable approach that HashiCorp utilizes for infrastructure management. The metadata also includes a serial parameter, which is the file’s internal counter indicating how many iterations of state change have occurred.
The state is encoded as a JSON file. This makes it more machine-friendly than the native HashiCorp Configuration Language (HCL) used in most Terraform files, which is designed to emphasize readability by humans.
Although it’s a JSON document, the state file isn’t intended to be directly manually modified, as this will tamper with its condition and might corrupt it.
Instead, to get a clearer view of the state’s contents, run the terraform show command, which will output something similar to this:
C:\Terraform>terraform show
# azurerm_linux_virtual_machine.myterraformvm:
resource "azurerm_linux_virtual_machine" "myterraformvm" {
admin_username = "azureuser"
allow_extension_operations = true
computer_name = "myvm"
disable_password_authentication = true
encryption_at_host_enabled = false
extensions_time_budget = "PT1H30M"
id = "/subscriptions/46801f45-d426-43b3-a094-0781444710a8/resourceGroups/my1stTFRG/providers/Microsoft.Compute/virtualMachines/myVM"
location = "eastus"
max_bid_price = -1
name = "myVM"
network_interface_ids = [
"/subscriptions/46801f45-d426-43b3-a094-0781444710a8/resourceGroups/my1stTFRG/providers/Microsoft.Network/networkInterfaces/myNIC",
Here, you can see all details from the last successful deployment state of these example resources.
How drift creeps in
Although Terraform’s approach keeps things tidy when your DevOps engineers make changes from the Terraform CLI, changes outside the platform remain invisible to the Terraform state until the next terraform plan or terraform apply command.
For example, if a DevOps engineer changes a VM size configuration using a manual update process, like a cloud CLI or portal, or runs a non-Terraform-automated process, like CloudFormation, an ARM template, Chef, Puppet, or Ansible, the Terraform State file won’t detect the change.
DevOps engineers can sometimes identify these differences by using the terraform plan command followed by the terraform apply command, but some changes can invisibly break the state and need to be manually resolved. In particular, aggregate types and API responses should be error-checked.
You should therefore be cautious when modifying resources outside of Terraform and subsequently using terraform apply in your automations after doing so, as this command will revert your changes. Modifications like this can result in deployment failures by adversely changing the availability of deployed resources or even destructively affecting their state.
Detecting Terraform drift
The most basic way to detect drift is by comparing a Terraform state file to monitoring metrics provided by the actual infrastructure. This might involve something like comparing the Terraform state file to information from a cloud provider’s API to find discrepancies that would indicate configuration drift.
The READ method
You can use a provider’s READ method to capture the state of a schema and ensure that it’s synchronized to your state file. Provider CREATE and UPDATE functions frequently normalize inputs—as in the case of sanitized string inputs—or apply default values to unspecified (often optional) attributes. So, it’s good practice to call the READ method after any modifications to ensure your state is synchronized.
Terraform refresh
It’s tedious to compare files manually, and you can’t always rely on good practice being implemented universally, so Terraform provides commands for drift detection and remediation.
In the past, developers could use terraform refresh to validate configuration updates. This command reads the state of managed remote objects and updates the state file accordingly. However, terraform refresh is now deprecated, as its behavior can cause serious issues if remote resources are incorrectly configured. It should only be used in versions of Terraform before v0.15.4.
Terraform plan
So, how do you easily remedy drift in your state file after making changes to remote objects outside of Terraform? If you need to perform a simple refresh, it’s now recommended that you use the terraform plan command and apply the –refresh-only option:
terraform plan –refresh-only
The refresh functionality is also natively integrated in terraform plan and terraform apply, which are the two main commands used to trigger the deployment of resources.
To run a Terraform-based deployment of resources, you'll need to follow three steps:
- You’ll start with the terraform init command, which initializes the resource provider—Azure, AWS, Kubernetes, or whichever provider you’re using—and validates your terraform template file or files for syntax correctness.
- Next, run terraform plan. This command runs through your Terraform template and validates the deployment in a pre-deployment state. Consider this a check of what will get deployed in the final step.
- Use terraform apply to run the deployment. This command connects to the target environment and deploys the defined resources from the template file or files.
The terraform.state file is created during the execution of the apply step, storing the actual most up-to-date state of the deployment in it.
Here's an example output of the terraform plan phase in your Azure Virtual Machine deployment, where the deploy.tf file is stored in a folder called my1stlinuxvm:
> terraform plan my1stlinuxvm
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
------------------------------------------------------------------------
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# azurerm_linux_virtual_machine.myterraformvm will be created
+ resource "azurerm_linux_virtual_machine" "myterraformvm" {
+ admin_username = "azureuser"
+ allow_extension_operations = true
+ computer_name = "myvm"
+ disable_password_authentication = true
+ extensions_time_budget = "PT1H30M"
+ id = (known after apply)
+ location = "eastus"
+ max_bid_price = -1
+ name = "myVM"
+ network_interface_ids = (known after apply)
+ priority = "Regular"
+ private_ip_address = (known after apply)
+ private_ip_addresses = (known after apply)
+ provision_vm_agent = true
+ public_ip_address = (known after apply)
+ public_ip_addresses = (known after apply)
+ resource_group_name = "my1stTFRG"
+ size = "Standard_DS2_v2"
+ tags = {
+ "environment" = "Terraform Demo"
}
+ virtual_machine_id = (known after apply)
+ zone = (known after apply)
Notice when running this command, it clearly identifies the integrated refresh functionality. You can see this in the second line through the Refreshing Terraform state... operation.
From there, initiate the actual deployment by running and examining the output of a terraform apply command:
> terraform apply my1stlinuxvm
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# azurerm_linux_virtual_machine.myterraformvm will be created
+ resource "azurerm_linux_virtual_machine" "myterraformvm" {
+ admin_username = "azureuser"
+ allow_extension_operations = true
+ computer_name = "myvm"
+ disable_password_authentication = true
+ extensions_time_budget = "PT1H30M"
+ id = (known after apply)
+ location = "eastus"
+ max_bid_price = -1
+ name = "myVM"
+ network_interface_ids = (known after apply)
+ priority = "Regular"
+ private_ip_address = (known after apply)
+ private_ip_addresses = (known after apply)
+ provision_vm_agent = true
+ public_ip_address = (known after apply)
+ public_ip_addresses = (known after apply)
+ resource_group_name = "my1stTFRG"
+ size = "Standard_DS2_v2"
+ tags = {
+ "environment" = "Terraform Demo"
}
Once the deployment is complete, you can validate the Azure VM and, for example, check the size in the Azure Portal:
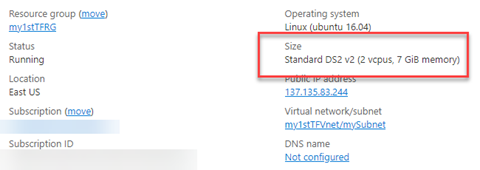
Your deployment is now done. Next, simulate a configuration drift by manually changing the Azure VM size outside of Terraform. For this example, you’ll switch to a burstable (B2ms) VM:
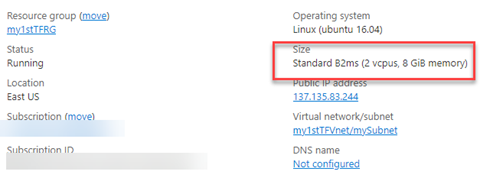
Now, see what happens when you run a new terraform plan sequence operation:
> terraform plan my1stlinuxvm
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
priority = "Regular"
private_ip_address = "10.0.1.4"
private_ip_addresses = [
"10.0.1.4",
]
provision_vm_agent = true
public_ip_address = "137.135.83.244"
public_ip_addresses = [
"137.135.83.244",
]
resource_group_name = "my1stTFRG"
~ size = "Standard_B2ms" -> "Standard_DS2_v2"
tags = {
"environment" = "Terraform Demo"
}
virtual_machine_id = "a7d36d96-7973-4c3f-9631-40b73572e0e0"
}
Plan: 0 to add, 1 to change, 0 to destroy.
------------------------------------------------------------------------
Note how the plan identifies the detected difference between what is expected from the VM in the terraform.state file and the Azure API’s response from the actual running VM in Azure. The ~ character signifies a change, a – character signifies the removal of a component, and a + character identifies that Terraform will deploy a new component.
Besides identifying the change, Terraform also conveniently tells you it will read and write the new VM size (Standard_B2ms) over the one you have in the template.tf file (Standard_DS2_v2).
Initiating a new terraform apply command will loop through the deployment template and result in a changed VM size.
Besides these Terraform-native methods of detecting drift, you can also use external monitoring tools to accomplish the same thing, keeping in mind still that changes should still be applied using Terraform commands rather than manual file changes.
Conclusion
This article touched on the complexity of managing drift in Infrastructure as Code architectures using Terraform. It emphasized the centrality of terraform.state as the source of all Terraform deployments, and you’ve learned the risks of configuration drift in mismanaging this file. Although an Azure Terraform deployment has been used as an example here, it’s important to note that Terraform supports multiple public, private, and hybrid cloud environments.
You also learned about a few methods to detect Terraform drift, culminating in an examination of the native drift detection and remediation functionality in the terraform plan and terraform apply commands.
Mitigating configuration drift in your infrastructure as code is important, but it's also industry best practice to ensure your IaC's initial desired state is secure, compliant, and free of misconfigurations, vulnerabilities, and secrets. Look for an IaC security tool that integrates seamlessly into your CI/CD pipeline via API.
Check out documentation on our template scanner to learn more.
